生產環境中輕松部署深度學習模型
譯文【51CTO.com快譯】能從數據中學習,識別模式并在極少需要人為干預的情況下做出決策的系統令人興奮。深度學習是一種使用神經網絡的機器學習,正迅速成為解決對象分類到推薦系統等許多不同計算問題的有效工具。然而,將經過訓練的神經網絡部署到應用程序和服務中可能會給基礎設施經理帶來挑戰。多個框架、未充分利用的基礎設施和缺乏標準實施,這些挑戰甚至可能導致AI項目失敗。本文探討了如何應對這些挑戰,并在數據中心或云端將深度學習模型部署到生產環境。
一般來說,我們應用開發人員與數據科學家和IT部門合作,將AI模型部署到生產環境。數據科學家使用特定的框架來訓練面向眾多使用場景的機器/深度學習模型。我們將經過訓練的模型整合到為解決業務問題而開發的應用程序中。然后,IT運營團隊在數據中心或云端運行和管理已部署的應用程序。
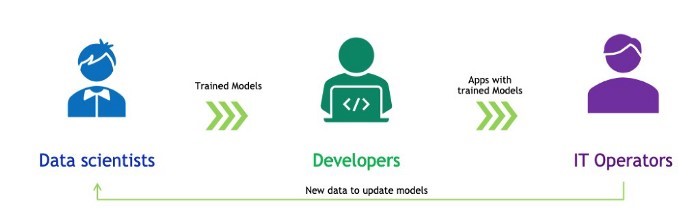
圖1.
將深度學習模型部署到生產環境面臨兩大挑戰:
- 我們需要支持多種不同的框架和模型,這導致開發復雜性,還存在工作流問題。數據科學家開發基于新算法和新數據的新模型,我們需要不斷更新生產環境。
- 如果我們使用英偉達GPU提供出眾的推理性能,有幾點要牢記。首先,GPU是強大的計算資源,每GPU運行一個模型可能效率低下。在單個GPU上運行多個模型不會自動并發運行這些模型以盡量提高GPU利用率。
那么我們如何是好?不妨看看我們如何使用英偉達的TensorRT Inference Server之類的應用程序來應對這些挑戰。你可以從英偉達NGC庫(https://ngc.nvidia.com/catalog/containers/nvidia:tensorrtserver)作為容器,或者從GitHub(https://github.com/NVIDIA/tensorrt-inference-server)作為開源代碼來下載TensorRT Inference Server。
TensorRT Inference Server:使部署更容易
TensorRT Inference Server通過以下功能組合,簡化部署經過訓練的神經網絡:
- 支持多種框架模型:我們可以使用TensorRT Inference Server的模型庫克服第一個挑戰,該模型庫是個存儲位置,用任何框架(TensorFlow、TensorRT、ONNX、PyTorch、Caffe、Chainer、MXNet甚至自定義框架)開發的模型都可以存儲在此處。TensorRT Inference Server可以部署用所有這些框架構建的模型;Inference Server容器在GPU或CPU服務器上啟動時,它將所有模型從模型庫加載到內存中。然后,該應用程序使用API調用推理服務器對模型運行推理。如果我們有很多無法裝入到內存中的模型,可以將單個庫拆分成多個庫,并運行TensorRT Inference Server的不同實例,每個實例指向不同的庫。即使在推理服務器和我們的應用程序運行時,也可以通過改變模型庫來輕松更新、添加或刪除模型。
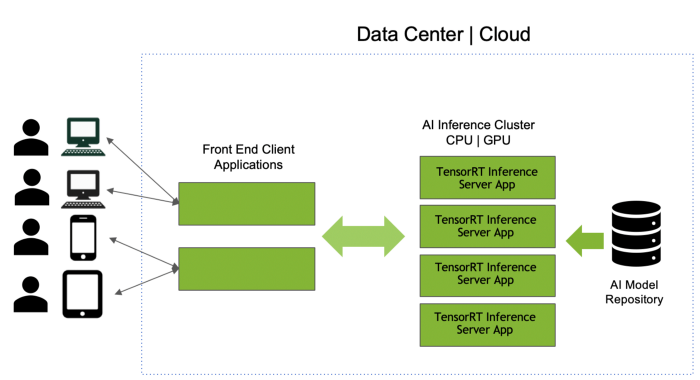
圖2
- 盡量提高GPU利用率:我們已成功地運行應用程序和推理服務器,現可以克服第二個挑戰。GPU利用率常常是基礎設施經理眼里的關鍵績效指標(KPI)。TensorRT Inference Server可以在GPU上并發調度多個相同或不同的模型;它可自動盡量提高GPU利用率。因此,我們開發人員不必采取特殊措施,IT運營要求也得到滿足。IT運營團隊將在所有服務器上運行同樣的TensorRT Inference Server容器,而不是在每臺服務器上部署一個模型。由于它支持多個模型,因此相比每臺服務器一個模型這種場景,可確保GPU充分利用,并使服務器的負載更均衡。這個演示視頻(https://youtu.be/1DUqD3zMwB4)解釋了服務器負載均衡和利用率。
- 啟用實時和批推理:推理有兩種。如果我們的應用程序需要實時響應用戶,那么推理也需要實時完成。由于延遲是個問題,請求無法放入隊列、與其他請求一起批處理。另一方面,如果沒有實時要求,可以將請求與其他請求進行批處理,以提高GPU利用率和吞吐量。
我們開發應用程序時,有必要了解實時要求。TensorRT Inference Server有個參數可以為實時應用程序設置延遲閾值,還支持動態批處理,它可以設為非零數字,以實施批處理。我們要與IT運營團隊密切合作,確保這些參數正確設置。
- CPU、GPU和異構集群上的推理:在許多企業,GPU主要用于訓練。推理在常規CPU服務器上完成。然而,在GPU上運行推理大大加快速度,我們還需要靈活地在任何處理器上運行模型。
不妨探討如何從CPU推理遷移到GPU推理。
- 我們目前的集群是一組純CPU服務器,它們都運行TensorRT Inference Server應用程序。
- 我們將GPU服務器引入到該集群,在這些服務器上運行TensorRT Inference Server軟件。
- 我們將GPU加速模型添加到模型庫中。
- 使用配置文件,我們指示這些服務器上的TensorRT Inference Server使用GPU進行推理。
- 我們可以停用集群中的純CPU服務器,也可以在異構模式下使用它們。
- 無需對調用TensorRT Inference Server的應用程序更改代碼。
- 與DevOps基礎設施集成:最后一點與IT團隊較為密切。貴公司是否遵循DevOps實踐?DevOps是一系列流程和實踐,旨在縮短整個軟件開發和部署周期。實施DevOps的企業往往使用容器來包裝用于部署的應用程序。TensorRT Inference Server是一個Docker容器,IT人員可以使用Kubernetes來管理和擴展它。他們還可以將推理服務器作為Kubeflow管道的一部分,用于端到端的AI工作流程。來自推理服務器的GPU/CPU利用率度量指標告訴Kubernetes何時在新服務器上啟動新實例以便擴展。
如果設置模型配置文件,并集成客戶端庫,很容易將TensorRT Inference Server整合到我們的應用程序代碼中。
部署經過訓練的神經網絡可能帶來挑戰,不過本文介紹了使這種部署更輕松的若干技巧。歡迎留言交流。
原文標題:Easily Deploy Deep Learning Models in Production,作者:Shankar Chandrasekaran
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】