四種分布式數據庫場景選型、優缺點對比分析和未來展望
1 引言
近年來,隨著國際信息安全形式的日益嚴峻,國家信息安全策略逐步深入。因此,一行兩會連續針對金融業數據庫技術受制于人的嚴峻形勢出臺了相關政策,以滿足構建安全可靠可控的信息技術體系的要求。
縱觀近年來普惠金融的發展,多用戶、低額的客單價帶來的主要挑戰是數據量、交易額的大幅提高,并伴隨著數十倍的交易高峰壓力以及交易復雜度的增加。而傳統數據庫在處理此類應用場景的時,在擴展性、性能、吞吐量和可靠性等方面遇到了明顯的瓶頸,只能通過業務拆分、升級硬件的方式來提升性能,造成設備投入和人員成本的不斷攀升。面對著互聯網金融業態不斷的發展,數據的交互和存儲也呈現指數級增長,這樣的方式也無法保證業務連續性。在此形式下,在分布式數據庫的選型上,根據不同的業務場景和關鍵系統中選擇不同的開源產品,通過對開源數據庫的深入研究和應用,滿足了互聯網金融業務場景的事務處理和數據處理的要求。
2 傳統數據庫的那些事
個人認為,分布式數據庫是起源于傳統的關系型數據庫,兩者的設計場景不同,前者面對企業級應用,運行在獨立的服務器上,而后者的應用更多的是面對互聯網用戶。隨著用戶相應的數據量極具增加,傳統的關系型數據庫在可擴展性的弊端日益顯現,一般有下面幾個方面:
(1)單點處理的性能瓶頸,即單點的數據庫系統無法處理大規模的并發請求和計算;
(2)單點運行風險高,容災容錯能力差;
(3)單點存儲能力有限,只能縱向擴展,不能橫向擴展;
(4)應用擴容升級難度大,設備投入高。
對于數據庫本身來說,傳統的分布式數據庫都有各自的集群解決方案,不過這不是真正意義上的分布式,僅僅是為了解決高可用場景下數據庫的負載均衡問題。這種特性是每個數據庫都是冗余的,所謂冗余,那就是每個數據庫的數據都是完全一樣的,所以數據量上升到一定的程度,對集群中的每個數據庫都會造成很大的壓力。
然而,云計算的出現引爆了這一切。當資源不再是瓶頸的時候,分布式數據庫的春天來了。
3 說說分布式數據庫
分布式數據庫的概念不再闡述,大體描述就是數據庫技術和網絡技術的親生孩子。在此,我們為什么選擇分布式數據庫,理由有如下:
(1)具有靈活的體系結構;
(2)適應分布式的管理和控制機構;
(3)經濟性能優越;
(4)系統的可靠性高、可用性好;
(5)局部的應用響應快;
(6)優越的可擴展性,易于集成現有的系統。
那分布式數據庫應該怎么用?基于分布式數據庫的選型該怎么做?
首先,基于特性,分布式數據庫大致可以分為三類:
(1)支持持久化存儲的分布式存儲系統,如MySQL,OceanBase;
(2)偏向于計算的分布式計算框架,如Hadoop HDFS,Ceph,Swift,Blob,Cinder,Lustre;
(3)分布式消息隊列,如Redis,RMQ,CMQ,Kafka。
其次,基于不同的應用場景,根據特性繼續細化,又可以分為以下:
(1)分布式協同數據庫系統;
(2)分布式任務;
(3)流式計算;
(4)分布式文件系統;
(5)分布式nosql存儲;
(6)分布式關系數據庫;
(7)分布式消息隊列。
回到最核心的問題,如何進行分布式數據庫技術路線的選擇?
分布式一般分為三條技術路線:分布式訪問客戶端、分布式中間件模式、分布式數據庫模式。其中分布式訪問客戶端對應用侵入性大,改造難度很高;分布式中間件則類似MyCAT等產品,在數據庫和應用間架一層Proxy,這種方案無法支持分布式事務、也無法支持跨庫關聯,分布式數據庫方案則將分庫分表等中間件實現的功能下推到數據庫層面來做,對應用透明,應用就像使用單機數據庫來使用分布式數據庫,同時天然地支持分布式事務。
4 常用的分布式數據庫和場景選型
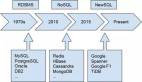
針對以上概述,列舉ElasticSearch、Redis、MySQL分布式集群、MongoDB四個分布式數據庫進行舉例,分別從簡介、應用場景、優點、缺點、備份/持久化進行對比和分析。其中MySQL分布式集群包括以下幾種集群方式:Proxy,Cluster,Mha,Mgr,基于MySQL協議的NewSQL,如MyCAT,OceanBase不在此范圍之內。
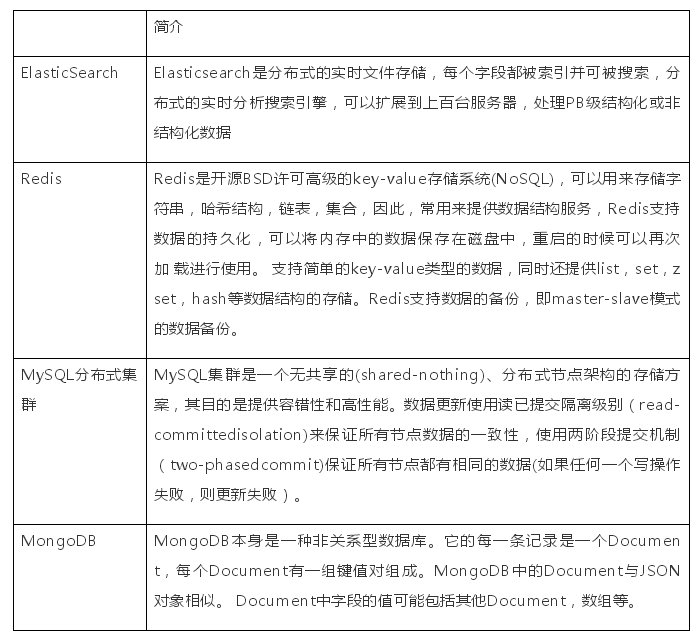
(1)簡介
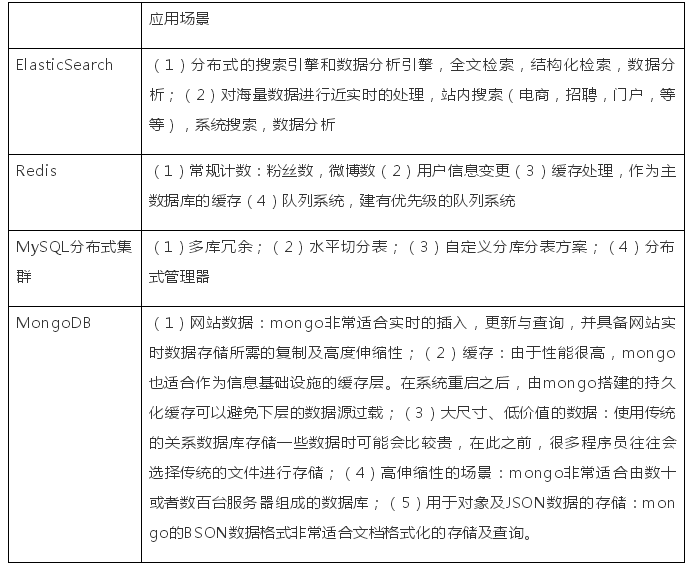
(2)應用場景
(3)優點
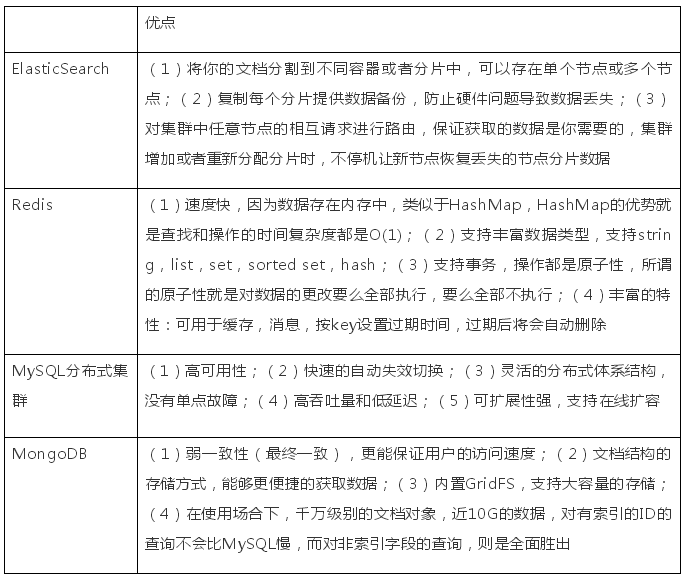
(4)缺點
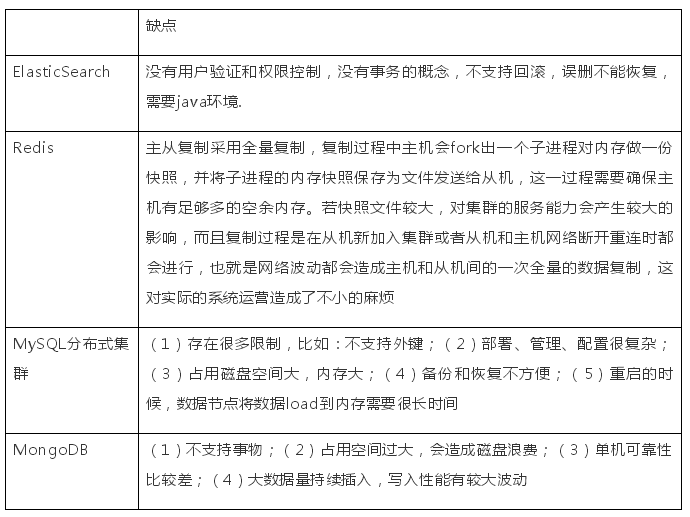
(5)備份/持久化方案
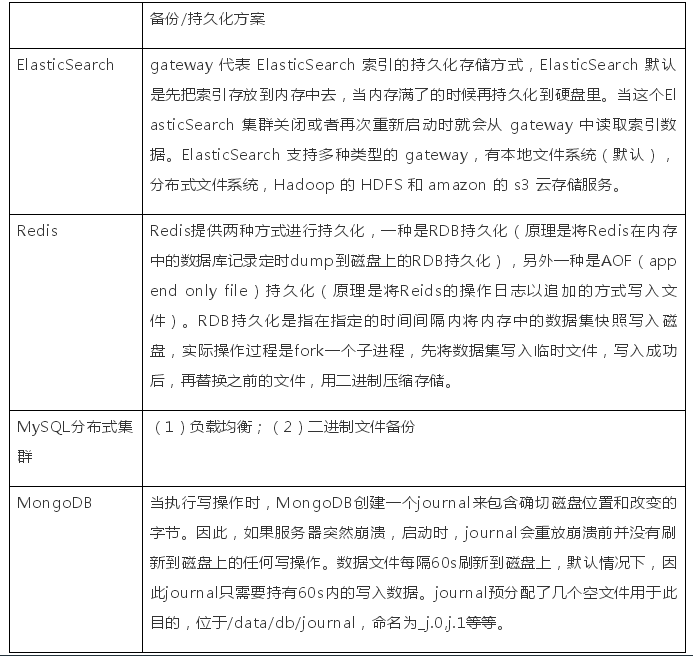
5 項目中的一些問題
在項目中,針對分布式數據庫的設計,一般有幾個難點。
(1)分布式事務的問題,在分布式數據庫中,分布式事務的實時一致性是很難保證的,而容錯性的設計一定要考慮全面,通過犧牲相應的可用性來保證一致性。
(2)性能方面,為了保證事務的全局一致性,分布式數據庫需要一個全局的事務管理器,用于分配全局事務的工作,不同的分布式數據庫或許有不一樣的功能,如果數據量和請求達到一個量級的時候,事務管理器或許就成為一個新的瓶頸。
(3)高可用的問題,當分布式數據庫集群中有節點宕機的時候,宕機數量和選舉工作會影響整個集群提供服務的質量,這一點跟業務的容忍性密切相關。
在運維階段,針對分布式數據庫是從認識、熟悉到經過的過程,一個新的產品或者功能的運維是離不開很多準備工作。因此,進入運維階段,一般要考慮下面幾步。
(1)準備好常用的運維腳本、應急手冊、運維手冊;
(2)做好分布式數據庫的監控,尤其是關鍵指標的監控;
(3)技術手冊的培訓,準入條件的限制;
(4)定期做好演練工作,及時發現問題。
6 分布式數據庫發展的一些思考
在企業中,對于新技術新產品的選型不僅僅為了滿足當前業務場景的需求,還要考慮到這個產品未來三到五年的發展道路和方向,以及是否能夠不斷迭代以滿足未來的需求。因此,用戶僅了解每一種技術的現狀是遠遠不夠的,只有當認識到一種技術的發展策略以及其架構的局限性后,才能夠預見和洞察未來。架構局限性并不等于功能的缺失。很多新型技術 在開始時都無法提供像Oracle一樣完備的企業級功 能,但并不意味著用戶必須要等到全部功能完備后才 開始考慮學習和使用。用戶在評估一種新產品和技術時,產品的功能點需要滿足幾個必備的基礎功能,而一些高級功能則不需要立刻具備。
對于分布式數據庫來說,隨著業務場景和數據的使用處理方面的需求趨于成熟和明朗,分布式數據庫的以場景和功能的區分更為細化,主要發展發現基本可以分為分布式聯機數據庫和分布式計算數據庫兩種,而針對非結構化小文件需求也在考驗分布式數據庫是否在這個領域能夠打出一片天地,可以展望,小型的分布式的針對非結構化的文件存儲數據庫也可能后期的戰場之一。
【作者】顧黃亮,十年技術老兵,歷經研發和運維,了解基礎架構、安全、中間件、數據庫,專注于智慧運維體系的打造。曾供職于航天晨光、上汽集團云計算中心,現任蘇寧消費金融安全運維部總監。