













粉絲關系鏈,10億數據,如何設計?
繼續答星球水友提問,大數據量,高并發量,好友關系鏈、粉絲關系鏈要如何設計?
什么是關系鏈業務?
關系鏈主要分為兩類,弱好友關系與強好友關系,兩類都有典型的互聯網產品應用。
弱好友關系的建立,不需要雙方彼此同意:
- 用戶A關注用戶B,不需要用戶B同意,此時用戶A與用戶B為弱好友關系,對A而言,暫且理解為“關注”;
- 用戶B關注用戶A,也不需要用戶A同意,此時用戶A與用戶B也為弱好友關系,對A而言,暫且理解為“粉絲”;
idol與fans這類微博粉絲關系鏈,是一個典型的弱好友關系應用。
強好友關系的建立,需要好友關系雙方彼此同意:
- 用戶A請求添加用戶B為好友,用戶B同意,此時用戶A與用戶B則互為強好友關系,即A是B的好友,B也是A的好友;
QQ好友關系鏈,是一個典型的強好友關系應用。

好友中心是一個典型的多對多業務:
- 一個用戶可以添加多個好友
- 也可以被多個好友添加
其典型架構為:
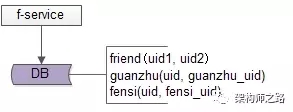
- friend-service:好友中心服務,對調用者提供友好的RPC接口
- db:對好友數據進行存儲
弱好友關系,存儲層應該如何實現?
通過弱好友關系業務分析,很容易了解到,其核心元數據為:
- guanzhu(uid, guanzhu_uid);
- fensi(uid, fensi_uid);
其中:
- guanzhu表,用戶記錄uid所有關注用戶guanzhu_uid
- fensi表,用來記錄uid所有粉絲用戶fensi_uid
需要強調的是,一條弱關系的產生,會產生兩條記錄,一條關注記錄,一條粉絲記錄。 例如:用戶A(uid=1)關注了用戶B(uid=2),A多關注了一個用戶,B多了一個粉絲,于是:
- guanzhu表要插入{1, 2}這一條記錄,1關注了2
- fensi表要插入{2, 1}這一條記錄,2粉了1
如何查詢一個用戶關注了誰?回答:在guanzhu的uid上建立索引:
- select * from guanzhu where uid=1;
即可得到結果,1關注了2。 如何查詢一個用戶粉了誰?回答:在fensi的uid上建立索引:
- select * from fensi where uid=2;
即可得到結果,2粉了1。
強好友關系,存儲層應該如何實現?
方案一
通過強好友關系業務分析,很容易了解到,其核心元數據為:
- friend(uid1, uid2);
其中:
- uid1,強好友關系中一方的uid
- uid2,強好友關系中另一方的uid
uid=1的用戶添加了uid=2的用戶,雙方都同意加彼此為好友,這個強好友關系,在數據庫中應該插入記錄{1, 2}還是記錄{2,1}呢?
回答:都可以。為了避免歧義,可以人為約定,插入記錄時uid1的值必須小于uid2。 例如:有uid=1,2,3三個用戶,他們互為強好友關系,那邊數據庫中可能是這樣的三條記錄
- {1, 2}
- {2, 3}
- {1, 3}
如何查詢一個用戶的好友呢?回答:假設要查詢uid=2的所有好友,只需在uid1和uid2上建立索引,然后:
- select * from friend where uid1=2
- union
- select * from friend where uid2=2
即可得到結果。
方案二
強好友關系是弱好友關系的一個特例,A和B必須互為關注關系(也可以說,同時互為粉絲關系),即也可以使用關注表和粉絲表來實現:
- guanzhu(uid, guanzhu_uid);
- fensi(uid, fensi_uid);
例如:用戶A(uid=1)和用戶B(uid=2)為強好友關系,即相互關注:
用戶A(uid=1)關注了用戶B(uid=2),A多關注了一個用戶,B多了一個粉絲,于是:
- guanzhu表要插入{1, 2}這一條記錄
- fensi表要插入{2, 1}這一條記錄
同時,用戶B(uid=2)也關注了用戶A(uid=1),B多關注了一個用戶,A多了一個粉絲,于是:
- guanzhu表要插入{2, 1}這一條記錄
- fensi表要插入{1, 2}這一條記錄
兩種實現,各有什么優缺點?
對于強好友關系的兩類實現:
- friend(uid1, uid2)表
- 數據冗余guanzhu表與fensi表(后文稱正表T1與反表T2)
在數據量小時,看似無差異,但數據量大時,數據冗余的優勢就體現出來了:
- friend表,數據量大時,如果使用uid1來分庫,那么uid2上的查詢就需要遍歷多庫
- 正表T1與反表T2通過數據冗余來實現好友關系,{1,2}{2,1}分別存在于兩表中,故兩個表都使用uid來分庫,均只需要進行一次查詢,就能找到對應的關注與粉絲,而不需要多個庫掃描
畫外音:假如有10億關系鏈,必須水平切分。
數據冗余,是多對多關系,在數據量大時,數據水平切分的常用實踐。
如何進行數據冗余?
接下來的問題轉化為,好友中心服務如何來進行數據冗余,常見有三種方法。
方法一:服務同步冗余

顧名思義,由好友中心服務同步寫冗余數據,如上圖1-4流程:
- 業務方調用服務,新增數據
- 服務先插入T1數據
- 服務再插入T2數據
- 服務返回業務方新增數據成功
優點:
- 不復雜,服務層由單次寫,變兩次寫
- 數據一致性相對較高(因為雙寫成功才返回)
缺點:
- 請求的處理時間增加(要插入次,時間加倍)
- 數據仍可能不一致,例如第二步寫入T1完成后服務重啟,則數據不會寫入T2
如果系統對處理時間比較敏感,引出常用的第二種方案。
方法二:服務異步冗余

數據的雙寫并不再由好友中心服務來完成,服務層異步發出一個消息,通過消息總線發送給一個專門的數據復制服務來寫入冗余數據,如上圖1-6流程:
- 業務方調用服務,新增數據
- 服務先插入T1數據
- 服務向消息總線發送一個異步消息(發出即可,不用等返回,通常很快就能完成)
- 服務返回業務方新增數據成功
- 消息總線將消息投遞給數據同步中心
- 數據同步中心插入T2數據
優點:
- 請求處理時間短(只插入1次)
缺點:
- 系統的復雜性增加了,多引入了一個組件(消息總線)和一個服務(專用的數據復制服務)
- 因為返回業務線數據插入成功時,數據還不一定插入到T2中,因此數據有一個不一致時間窗口(這個窗口很短,最終是一致的)
- 在消息總線丟失消息時,冗余表數據會不一致
如果想解除“數據冗余”對系統的耦合,引出常用的第三種方案。
方法三:線下異步冗余
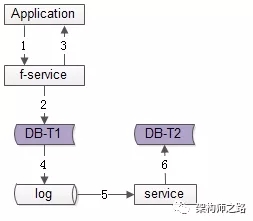
數據的雙寫不再由好友中心服務來完成,而是由線下的一個服務或者任務來完成,如上圖1-6流程:
- 業務方調用服務,新增數據
- 服務先插入T1數據
- 服務返回業務方新增數據成功
- 數據會被寫入到數據庫的log中
- 線下服務或者任務讀取數據庫的log
- 線下服務或者任務插入T2數據
優點:
- 數據雙寫與業務完全解耦
- 請求處理時間短(只插入1次)
缺點:
- 返回業務線數據插入成功時,數據還不一定插入到T2中,因此數據有一個不一致時間窗口(這個窗口很短,最終是一致的)
- 數據的一致性依賴于線下服務或者任務的可靠性
上述三種方案各有優缺點,可以結合實際情況選取。 數據冗余固然能夠解決多對多關系的數據庫水平切分問題,但又帶來了新的問題,如何保證正表T1與反表T2的數據一致性呢?
從上面的討論可以看到,不管哪種方案,因為兩步操作不能保證原子性,總有出現數據不一致的可能,高吞吐分布式事務是業內尚未解決的難題,此時的架構優化方向:最終一致性。并不是完全保證數據的實時一致,而是盡早的發現不一致,并修復不一致。 最終一致性,是高吞吐互聯網業務一致性的常用實踐。更具體的,保證數據最終一致性的常見方案有三種。
方法一:線下掃面正反冗余表全部數據
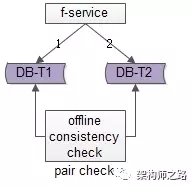
如上圖所示,線下啟動一個離線的掃描工具,不停的比對正表T1和反表T2,如果發現數據不一致,就進行補償修復。
優點:
- 比較簡單,開發代價小
- 線上服務無需修改,修復工具與線上服務解耦
缺點:
- 掃描效率低,會掃描大量的“已經能夠保證一致”的數據
- 由于掃描的數據量大,掃描一輪的時間比較長,即數據如果不一致,不一致的時間窗口比較長
有沒有只掃描“可能存在不一致可能性”的數據,而不是每次掃描全部數據,以提高效率的優化方法呢?
方法二:線下掃描增量數據

每次只掃描增量的日志數據,就能夠極大提高效率,縮短數據不一致的時間窗口,如上圖1-4流程所示:
- 寫入正表T1
- 第一步成功后,寫入日志log1
- 寫入反表T2
- 第二步成功后,寫入日志log2
當然,我們還是需要一個離線的掃描工具,不停的比對日志log1和日志log2,如果發現數據不一致,就進行補償修復
優點:
- 雖比方法一復雜,但仍然是比較簡單的
- 數據掃描效率高,只掃描增量數據
缺點:
- 線上服務略有修改(代價不高,多寫了2條日志)
- 雖然比方法一更實時,但時效性還是不高,不一致窗口取決于掃描的周期
有沒有實時檢測一致性并進行修復的方法呢?
方法三:實時線上“消息對”檢測
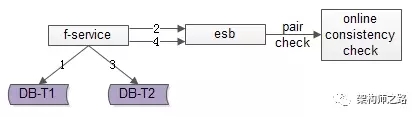
這次不是寫日志了,而是向消息總線發送消息,如上圖1-4流程所示:
- 寫入正表T1
- 第一步成功后,發送消息msg1
- 寫入反表T2
- 第二步成功后,發送消息msg2
這次不是需要一個周期掃描的離線工具了,而是一個實時訂閱消息的服務不停的收消息。假設正常情況下,msg1和msg2的接收時間應該在3s以內,如果檢測服務在收到msg1后沒有收到msg2,就嘗試檢測數據的一致性,不一致時進行補償修復
優點:
- 效率高
- 實時性高
缺點:
- 方案比較復雜,上線引入了消息總線這個組件
- 線下多了一個訂閱總線的檢測服務
however,技術方案本身就是一個投入產出比的折衷,可以根據業務對一致性的需求程度決定使用哪一種方法。
總結
(1) 關系鏈業務是一個典型的多對多關系,又分為強好友與弱好友
(2) 數據冗余是一個常見的多對多業務數據水平切分實踐
(3) 冗余數據的常見方案有三種
- 服務同步冗余
- 服務異步冗余
- 線下異步冗余
(4) 數據冗余會帶來一致性問題,高吞吐互聯網業務,要想完全保證事務一致性很難,常見的實踐是最終一致性
(5) 最終一致性的常見實踐是,盡快找到不一致,并修復數據,常見方案有三種
- 線下全量掃描法
- 線下增量掃描法
- 線上實時檢測法
希望大家有所啟示,思路比結論重要。
【本文為51CTO專欄作者“58沈劍”原創稿件,轉載請聯系原作者】






















