作為運維還不會正則表達式?趕快看這篇學習一下
概述
正則表達式是很多運維薄弱的一項技能。大家很多時候都會覺得正則表達式難記、難學、難用,但不可否認的是正則表達式是一項很重要的技能,所有今天將學習和使用正則表達式時的關鍵點整理如下,僅供參考。
什么是正則表達式?
正則表達式(Regular Expression 或 Regex),是用于定義某種特定搜索模式的字符組合。正則表達式可用于匹配、查找和替換文本中的字符,進行輸入數據的驗證,查找英文單詞的拼寫錯誤等。
調試工具
下面列出了幾款優秀的在線調試工具,如果你想創建或者調試正則表達式可能會需要。個人比較偏好Regex101,regex101 支持在正則表達式的不同 flavor 之間切換、解釋你的正則表達式、顯示匹配信息、提供常用語法參考等功能,非常強大。
1、Regex101
2、Regexr
3、Regexpal
開始
在 Javascript 中,一個正則表達式以 / 開頭和結尾,所以簡單至 /hello regexp/ 就是一個正則表達式。
Flags(標志符或修飾符)
Flags 寫在結束的/之后,可以影響整個正則表達式的匹配行為。常見的 flags 有:
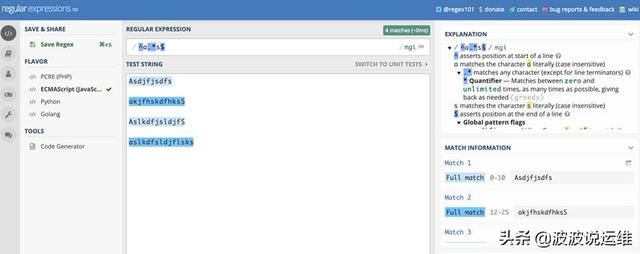
g:全局匹配(global);正則表達式默認只會返回第一個匹配結果,使用標志符g則可以返回所有匹配
i:忽略大小寫(case-insensitive);在匹配時忽略英文字母的大小寫
m:多行匹配(multiline);將開始和結束字符(^和$)視為在多行上工作,即分別匹配每一行(由 \n 或 \r 分割)的開始和結束,而不只是只匹配整個輸入字符串的最開始和最末尾處
Flags 可以組合使用,如:
Character Sets(字符集合)
用于匹配字符集合中的任意一個字符,常見的字符集有:
[xyz]:匹配 "x"或"y"``"z"
[^xyz]:補集,匹配除 "x" "y" "z"的其他字符
[a-z]:匹配從 "a" 到 "z" 的任意字符
[^a-n]:補集,匹配除 "a" 到 "n" 的其他字符
[A-Z]:匹配從 "A" 到 "Z" 的任意字符
[0-9]:匹配從 "0" 到 "9" 的任意數字
比如匹配所有的字母和數字可以寫成:/[a-zA-Z0-9]/ 或者 /[a-z0-9]/i。
Quantifiers (量詞)
在實際使用中常需要匹配同一類型的字符多次,比如匹配 11 位的手機號,我們不可能將 [0-9] 寫 11 遍,此時可以使用 Quantifiers 來實現重復匹配。
{n}:匹配 n 次
{n,m}:匹配 n-m 次
{n,}:匹配 >=n 次
?:匹配 0 || 1 次
*:匹配 >=0 次,等價于 {0,}
+:匹配 >=1 次,等價于 {1,}
Metacharacters(元字符)
在正則表達式中有一些具有特殊含義的字母,被稱為元字符,簡言之,元字符就是描述字符的字符,它用于對字符表達式的內容、轉換及各種操作信息進行描述。
常見的元字符有:
\d:匹配任意數字,等價于 [0-9]
\D:匹配任意非數字字符;\d 的補集
\w:匹配任意基本拉丁字母表中的字母和數字,以及下劃線;等價于 [A-Za-z0-9_]
\W:匹配任意非基本拉丁字母表中的字母和數字,以及下劃線;\w 的補集
\s:匹配一個空白符,包括空格、制表符、換頁符、換行符和其他 Unicode 空格
\S:匹配一個非空白符;\s的補集
\b:匹配一個零寬單詞邊界,如一個字母與一個空格之間;例如,/\bno/ 匹配 "at noon" 中的 "no",/ly\b/ 匹配 "possibly yesterday." 中的 "ly"
\B:匹配一個零寬非單詞邊界,如兩個字母之間或兩個空格之間;例如,/\Bon/ 匹配 "at noon" 中的 "on",/ye\B/ 匹配 "possibly yesterday."中的 "ye"
\t:匹配一個水平制表符(tab)
\n:匹配一個換行符(newline)
\r:匹配一個回車符(carriage return)
實例
上面羅列出了這么多正則表達式的語法和規則,可以在一定程度上幫助我們分析和理解一段正則表達式的作用,但是如何將這些規則組合并創造出有特定作用的表達式還需要我們自己多加練習,下面舉幾個例子來說明運用這些規則。
1. 匹配手機號碼
我們先從比較簡單的匹配手機號碼開始。目前國內的手機號碼是1(3/4/5/7/8)開頭的 11 位數字,因此手機號碼的正則可以分解為以下幾部分:
以 1 開頭:/^1/第 2 位為3、4、5、7、8中的一個:/[34578]/ 或 /(3|4|5|7|8)/剩余 3-11 位均為數字,并以數字結尾:/\d{9}$/
組合起來即為 /^1[34578]\d{9}$/ 或 /^1(3|4|5|7|8)\d{9}$/,因為使用捕獲括號存在性能損失,所以推薦使用第一種寫法。
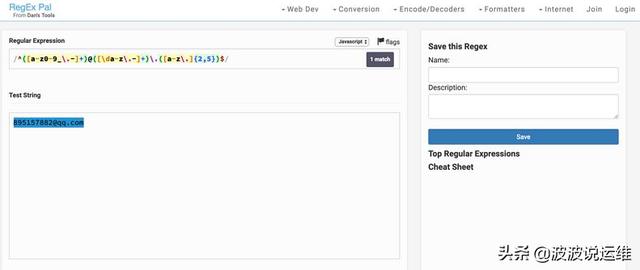
2. 匹配電子郵件
標準的電子郵件組成為
每部分的格式標準為(進行了相應的簡化,主要為展示如何書寫正則):
yourname:任意英文字母(a-z/A-Z)、數字(0-9)、下劃線(_)、英文句點(.)、連字符(-),長度大于 0domain:任意英文字母(a-z/A-Z)、數字(0-9)、連字符(-),長度大于 0extension:任意英文字母(a-z/A-Z),長度 2-8optional-extension:"."開頭,后面跟任意英文字母(a-z/A-Z),長度 2-8,可選
每部分的正則表達式為:
- yourname:/[a-z\d._-]+/domain:/[a-z\d-]+/extension: /[a-z]{2,8}/optional-extension:/(\.[a-z]{2,8})?/
組合起來形成最后的正則表達式:
- /^([a-z\d._-]+)@([a-z\d-]+)\.([a-z]{2,8})(\.[a-z]{2,8})?$/;
為了增加可讀性可以將每部分用"()"包起來,并不要忘記起始和結束符 ^$。
總結
篇幅有限,今天關于正則表達式的內容就介紹到這里,后面會分享更多devops和DBA方面的內容,感興趣的朋友可以關注下~