微服務注冊中心 Eureka 架構深入解讀
微服務架構中最核心的部分是服務治理,服務治理最基礎的組件是注冊中心。隨著微服務架構的發展,出現了很多微服務架構的解決方案,其中包括我們熟知的 Dubbo 和 Spring Cloud。
關于注冊中心的解決方案,dubbo 支持了 Zookeeper、Redis、Multicast 和 Simple,官方推薦 Zookeeper。Spring Cloud 支持了 Zookeeper、Consul 和 Eureka,官方推薦 Eureka。
兩者之所以推薦不同的實現方式,原因在于組件的特點以及適用場景不同。簡單來說:
- ZK 的設計原則是 CP,即強一致性和分區容錯性。他保證數據的強一致性,但舍棄了可用性,如果出現網絡問題可能會影響 ZK 的選舉,導致 ZK 注冊中心的不可用。
- Eureka 的設計原則是 AP,即可用性和分區容錯性。他保證了注冊中心的可用性,但舍棄了數據一致性,各節點上的數據有可能是不一致的(會最終一致)。
- Eureka 采用純 Java 實現,除實現了注冊中心基本的服務注冊和發現之外,極大的滿足注冊中心的可用性,即使只有一臺服務可用,也可以保證注冊中心的可用性。
- 本文將聚焦到 Eureka 的內部實現原理,先從微服務架構的部署圖介紹 Eureka 的總體架構,然后剖析服務信息的存儲結構,最后探究跟服務生命周期相關的服務注冊機制、服務續約機制、服務注銷機制、服務剔除機制、服務獲取機制、和服務同步機制。
Eureka 總體架構
下面是 Eureka 注冊中心部署在多個機房的架構圖,這正是他高可用性的優勢(Zookeeper 千萬別這么部署)。
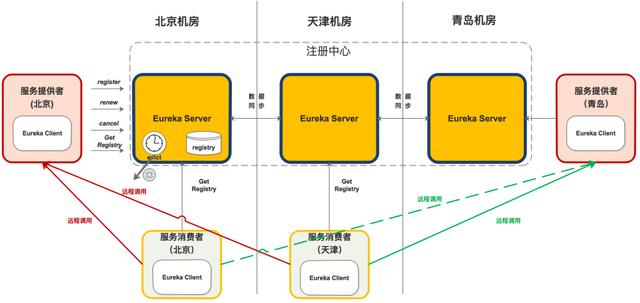
從組件功能看:
- 黃色注冊中心集群,分別部署在北京、天津、青島機房;
- 紅色服務提供者,分別部署北京和青島機房;
- 淡綠色服務消費者,分別部署在北京和天津機房;
從機房分布看:
- 北京機房部署了注冊中心、服務提供者和服務消費者;
- 天津機房部署了注冊中心和服務消費者;
- 青島機房部署了注冊中心和服務提供者;
組件調用關系
服務提供者
- 啟動后,向注冊中心發起 register 請求,注冊服務
- 在運行過程中,定時向注冊中心發送 renew 心跳,證明“我還活著”。
- 停止服務提供者,向注冊中心發起 cancel 請求,清空當前服務注冊信息。
服務消費者
- 啟動后,從注冊中心拉取服務注冊信息
- 在運行過程中,定時更新服務注冊信息。
- 服務消費者發起遠程調用:
- a> 服務消費者(北京)會從服務注冊信息中選擇同機房的服務提供者(北京),發起遠程調用。只有同機房的服務提供者掛了才會選擇其他機房的服務提供者(青島)。
- b> 服務消費者(天津)因為同機房內沒有服務提供者,則會按負載均衡算法選擇北京或青島的服務提供者,發起遠程調用。
注冊中心
啟動后,從其他節點拉取服務注冊信息。
運行過程中,定時運行 evict 任務,剔除沒有按時 renew 的服務(包括非正常停止和網絡故障的服務)。
運行過程中,接收到的 register、renew、cancel 請求,都會同步至其他注冊中心節點。
本文將詳細說明上圖中的 registry、register、renew、cancel、getRegistry、evict 的內部機制。
數據存儲結構
既然是服務注冊中心,必然要存儲服務的信息,我們知道 ZK 是將服務信息保存在樹形節點上。而下面是 Eureka 的數據存儲結構:
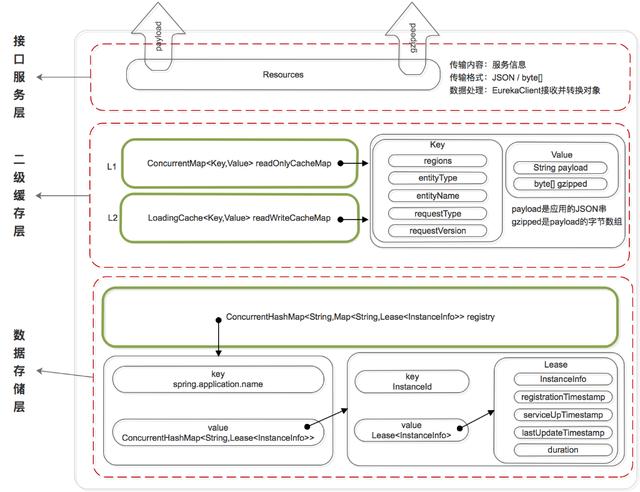
Eureka 的數據存儲分了兩層:數據存儲層和緩存層。
Eureka Client 在拉取服務信息時,先從緩存層獲取(相當于 Redis),如果獲取不到,先把數據存儲層的數據加載到緩存中(相當于 Mysql),再從緩存中獲取。值得注意的是,數據存儲層的數據結構是服務信息,而緩存中保存的是經過處理加工過的、可以直接傳輸到 Eureka Client 的數據結構。
Eureka 這樣的數據結構設計是把內部的數據存儲結構與對外的數據結構隔離開了,就像是我們平時在進行接口設計一樣,對外輸出的數據結構和數據庫中的數據結構往往都是不一樣的。
數據存儲層
這里為什么說是存儲層而不是持久層?因為 rigistry 本質上是一個雙層的 ConcurrentHashMap,存儲在內存中的。
- 第一層的 key 是spring.application.name,value 是第二層 ConcurrentHashMap;
- 第二層 ConcurrentHashMap 的 key 是服務的 InstanceId,value 是 Lease 對象;
- Lease 對象包含了服務詳情和服務治理相關的屬性。
二級緩存層
Eureka 實現了二級緩存來保存即將要對外傳輸的服務信息,數據結構完全相同。
- 一級緩存:ConcurrentHashMap<Key,Value> readOnlyCacheMap,本質上是 HashMap,無過期時間,保存服務信息的對外輸出數據結構。
- 二級緩存:Loading<Key,Value> readWriteCacheMap,本質上是 guava 的緩存,包含失效機制,保存服務信息的對外輸出數據結構。
既然是緩存,那必然要有更新機制,來保證數據的一致性。下面是緩存的更新機制:
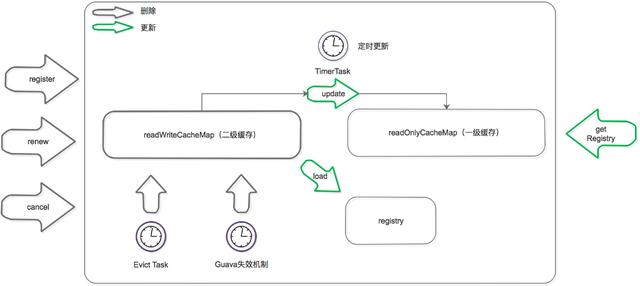
更新機制包含刪除和加載兩個部分,上圖黑色箭頭表示刪除緩存的動作,綠色表示加載或觸發加載的動作。
刪除二級緩存:
Eureka Client 發送 register、renew 和 cancel 請求并更新 registry 注冊表之后,刪除二級緩存;
Eureka Server 自身的 Evict Task 剔除服務后,刪除二級緩存;
二級緩存本身設置了 guava 的失效機制,隔一段時間后自己自動失效;
加載二級緩存:
Eureka Client 發送 getRegistry 請求后,如果二級緩存中沒有,就觸發 guava 的 load,即從 registry 中獲取原始服務信息后進行處理加工,再加載到二級緩存中。
Eureka Server 更新一級緩存的時候,如果二級緩存沒有數據,也會觸發 guava 的 load。
更新一級緩存:
- Eureka Server 內置了一個 TimerTask,定時將二級緩存中的數據同步到一級緩存(這個動作包括了刪除和加載)。
- 關于緩存的實現參考 ResponseCacheImpl
服務注冊機制
服務提供者、服務消費者、以及服務注冊中心自己,啟動后都會向注冊中心注冊服務(如果配置了注冊)。下圖是介紹如何完成服務注冊的:
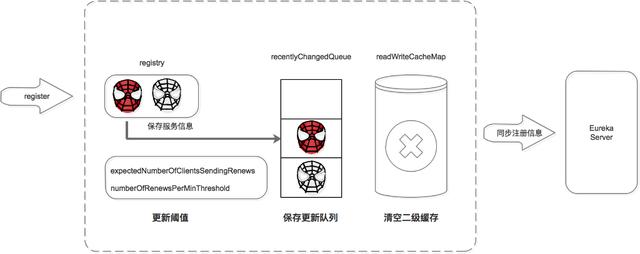
注冊中心服務接收到 register 請求后:
- 保存服務信息,將服務信息保存到 registry 中;
- 更新隊列,將此事件添加到更新隊列中,供 Eureka Client 增量同步服務信息使用。
- 清空二級緩存,即 readWriteCacheMap,用于保證數據的一致性。
- 更新閾值,供剔除服務使用。
- 同步服務信息,將此事件同步至其他的 Eureka Server 節點。
服務續約機制
服務注冊后,要定時(默認 30S,可自己配置)向注冊中心發送續約請求,告訴注冊中心“我還活著”。
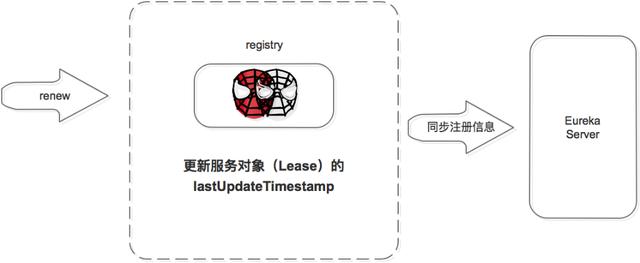
注冊中心收到續約請求后:
- 更新服務對象的最近續約時間,即 Lease 對象的 lastUpdateTimestamp;
- 同步服務信息,將此事件同步至其他的 Eureka Server 節點。
- 剔除服務之前會先判斷服務是否已經過期,判斷服務是否過期的條件之一是續約時間和當前時間的差值是不是大于閾值。
服務注銷機制
服務正常停止之前會向注冊中心發送注銷請求,告訴注冊中心“我要下線了”。
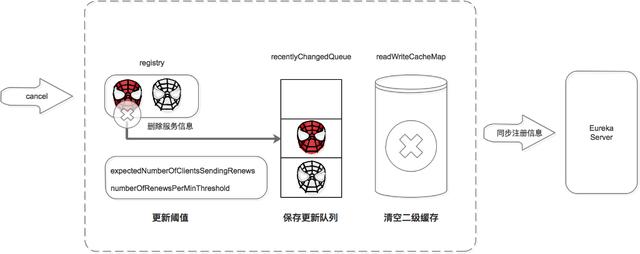
注冊中心服務接收到 cancel 請求后:
- 刪除服務信息,將服務信息從 registry 中刪除;
- 更新隊列,將此事件添加到更新隊列中,供 Eureka Client 增量同步服務信息使用。
- 清空二級緩存,即 readWriteCacheMap,用于保證數據的一致性。
- 更新閾值,供剔除服務使用。
- 同步服務信息,將此事件同步至其他的 Eureka Server 節點。
- 服務正常停止才會發送 Cancel,如果是非正常停止,則不會發送,此服務由 Eureka Server 主動剔除。
服務剔除機制
Eureka Server 提供了服務剔除的機制,用于剔除沒有正常下線的服務。
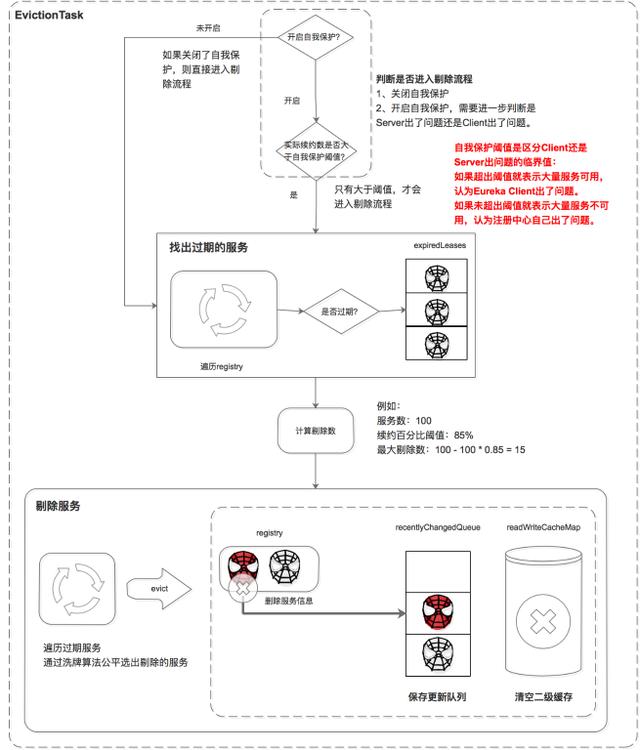
服務的剔除包括三個步驟,首先判斷是否滿足服務剔除的條件,然后找出過期的服務,最后執行剔除。
判斷是否滿足服務剔除的條件
有兩種情況可以滿足服務剔除的條件:
- 關閉了自我保護
- 如果開啟了自我保護,需要進一步判斷是 Eureka Server 出了問題,還是 Eureka Client 出了問題,如果是 Eureka Client 出了問題則進行剔除。
這里比較核心的條件是自我保護機制,Eureka 自我保護機制是為了防止誤殺服務而提供的一個機制。Eureka 的自我保護機制“謙虛”的認為如果大量服務都續約失敗,則認為是自己出問題了(如自己斷網了),也就不剔除了;反之,則是 Eureka Client 的問題,需要進行剔除。而自我保護閾值是區分 Eureka Client 還是 Eureka Server 出問題的臨界值:如果超出閾值就表示大量服務可用,少量服務不可用,則判定是 Eureka Client 出了問題。如果未超出閾值就表示大量服務不可用,則判定是 Eureka Server 出了問題。
條件 1 中如果關閉了自我保護,則統統認為是 Eureka Client 的問題,把沒按時續約的服務都剔除掉(這里有剔除的最大值限制)。
這里比較難理解的是閾值的計算:
- 自我保護閾值 = 服務總數 * 每分鐘續約數 * 自我保護閾值因子。
- 每分鐘續約數 =(60S/ 客戶端續約間隔)
最后自我保護閾值的計算公式為:
自我保護閾值 = 服務總數 * (60S/ 客戶端續約間隔) * 自我保護閾值因子。
舉例:如果有 100 個服務,續約間隔是 30S,自我保護閾值 0.85。
自我保護閾值 =100 * 60 / 30 * 0.85 = 170。
如果上一分鐘的續約數 =180>170,則說明大量服務可用,是服務問題,進入剔除流程;
如果上一分鐘的續約數 =150<170,則說明大量服務不可用,是注冊中心自己的問題,進入自我保護模式,不進入剔除流程。
找出過期的服務
遍歷所有的服務,判斷上次續約時間距離當前時間大于閾值就標記為過期。并將這些過期的服務保存到集合中。
剔除服務
在剔除服務之前先計算剔除的數量,然后遍歷過期服務,通過洗牌算法確保每次都公平的選擇出要剔除的任務,最后進行剔除。
執行剔除服務后:
- 刪除服務信息,從 registry 中刪除服務。
- 更新隊列,將當前剔除事件保存到更新隊列中。
- 清空二級緩存,保證數據的一致性。
- 實現過程參考 AbstractInstanceRegistry.evict() 方法。
服務獲取機制
Eureka Client 獲取服務有兩種方式,全量同步和增量同步。獲取流程是根據 Eureka Server 的多層數據結構進行的:
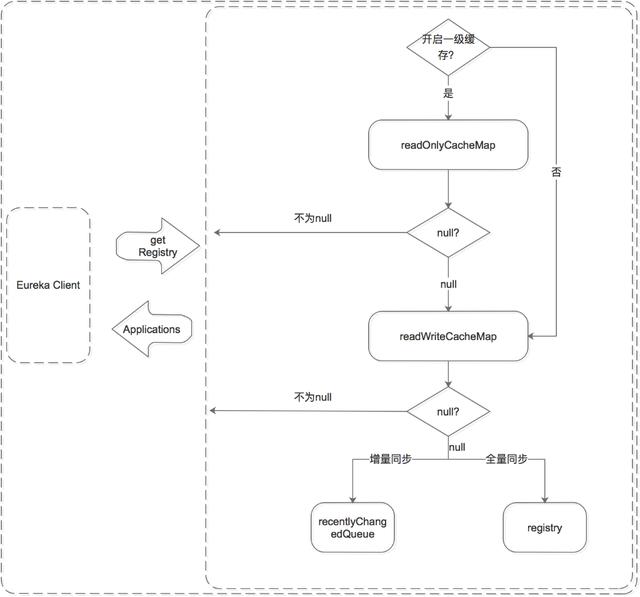
無論是全量同步還是增量同步,都是先從緩存中獲取,如果緩存中沒有,則先加載到緩存中,再從緩存中獲取。(registry 只保存數據結構,緩存中保存 ready 的服務信息。)
- 先從一級緩存中獲取
- a> 先判斷是否開啟了一級緩存
- b> 如果開啟了則從一級緩存中獲取,如果存在則返回,如果沒有,則從二級緩存中獲取
- d> 如果未開啟,則跳過一級緩存,從二級緩存中獲取
- 再從二級緩存中獲取
- a> 如果二級緩存中存在,則直接返回;
- b> 如果二級緩存中不存在,則先將數據加載到二級緩存中,再從二級緩存中獲取。注意加載時需要判斷是增量同步還是全量同步,增量同步從 recentlyChangedQueue 中 load,全量同步從 registry 中 load。
服務同步機制
服務同步機制是用來同步 Eureka Server 節點之間服務信息的。它包括 Eureka Server 啟動時的同步,和運行過程中的同步。
啟動時同步
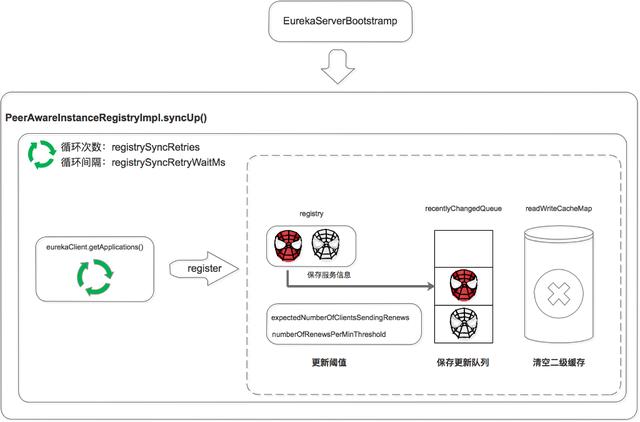
Eureka Server 啟動后,遍歷 eurekaClient.getApplications 獲取服務信息,并將服務信息注冊到自己的 registry 中。
注意這里是兩層循環,第一層循環是為了保證已經拉取到服務信息,第二層循環是遍歷拉取到的服務信息。
運行過程中同步
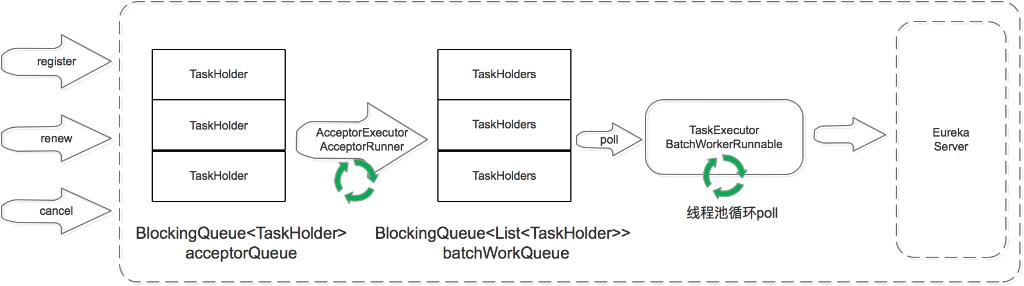
當 Eureka Server 節點有 register、renew、cancel 請求進來時,會將這個請求封裝成 TaskHolder 放到 acceptorQueue 隊列中,然后經過一系列的處理,放到 batchWorkQueue 中。
TaskExecutor.BatchWorkerRunnable是個線程池,不斷的從 batchWorkQueue 隊列中 poll 出 TaskHolder,然后向其他 Eureka Server 節點發送同步請求。
這里省略了兩個部分:
一個是在 acceptorQueue 向 batchWorkQueue 轉化時,省略了中間的 processingOrder 和 pendingTasks 過程。
另一個是當同步失敗時,會將失敗的 TaskHolder 保存到 reprocessQueue 中,重試處理。
寫在最后
對微服務解決方案 Dubbo 和 Spring Cloud 的對比非常多,這里對注冊中心做個簡單對比。
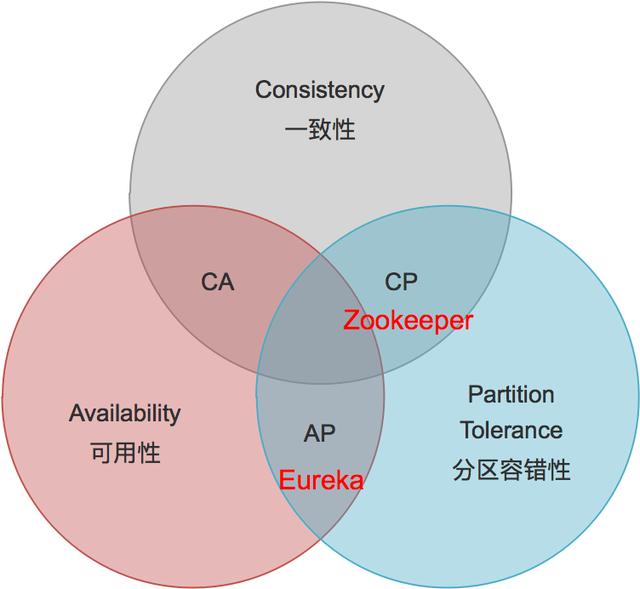
ZookeeperEureka設計原則CPAP優點數據強一致服務高可用缺點網絡分區會影響 Leader 選舉,超過閾值后集群不可用服務節點間的數據可能不一致; Client-Server 間的數據可能不一致;適用場景單機房集群,對數據一致性要求較高云機房集群,跨越多機房部署;對注冊中心服務可用性要求較高。