數據科學家為什么這么貴?
導讀
- 數據科學家為什么這么貴?這篇文章通過一些統計數據告訴你為什么
當你聽到“數據科學家”這個頭銜時,你會想到什么?可能不是一個衣衫襤褸、表情嚴肅的白領,對吧?
也許這就是為什么《哈佛商業評論》(Harvard Business Review)將“數據科學家”稱為“21世紀最性感的工作”。他們寫道,“如果‘性感’意味著擁有非常搶手的稀有品質,那么數據科學家已經在那里了。”他們很難招到,也很貴,而且由于他們的服務市場競爭非常激烈,很難留住他們。
數據科學家是受過訓練的專業技術人員,他們對數據世界的發現充滿了好奇心。盡管“數據科學家”一詞最近在Linkedin上很流行,但這個領域本身并不新鮮。在《哈佛商業評論》發表這篇文章時,已有數千名數據科學家在初創企業和公司工作。此外,使計算機與人類一樣智能的目標已經追求了近四分之一個世紀。數據科學家最近如此受歡迎有多種原因。其一,當收集數據成為時髦依賴,公司多年來一直收集越來越多的數據,由大型技術公司的成功很大程度上是得益于他們收集的數據,其次,技術的進步使得這些數據集合成為資產。
現在有大量現成的數據等待分析:
現在所有行業的大多數大公司都可以獲得大量的數據,但是許多公司并沒有以一種有效和富有成效的方式使用這些數據。然而,企業現在開始意識到,它們需要利用目前通過企業數據庫可以訪問的大量數據。多少數據?從2013年的4.4萬億gb增加到2020年的44萬億gb。
數據的數量和種類為有能力使用它的人和收集它的企業創造了機會。然而,該行業正面臨著技能和專業知識的短缺,而這些技能和專業知識是處理那些尋求利用其豐富數據的公司日益增長的需求所必需的。甚至那些在大學里學習計算機科學和技術的人也被迫在工作場所從事要求很高的數據分析工作。
數據科學人才結構性短缺:
根據加州大學河濱分校的統計數據,1/3的美國新聞與世界報道全球100所頂級大學提供數據科學學位。在這29所大學中,只有6所提供本科水平的數據科學課程,其余的是研究生學位。這些數據科學項目的平均班級規模只有23名學生。加州大學(University of California)預測,在已經為數不多的提供數據科學課程的大學中,小班授課不太可能“在縮小全球數據科學人才缺口方面產生有意義的影響”。在簡單的經濟術語中,需求超過了供給,在這種情況下,遠遠超過了供給。2017年,IBM預測,到2020年,每年對新數據科學家、數據開發人員和數據工程師的需求將達到近70萬個職位空缺。因此,一所大學僅有23個學生班級,而所有提供數據科學課程的大學大約有700名畢業生,將無法滿足快速增長的對數據科學人才的需求。
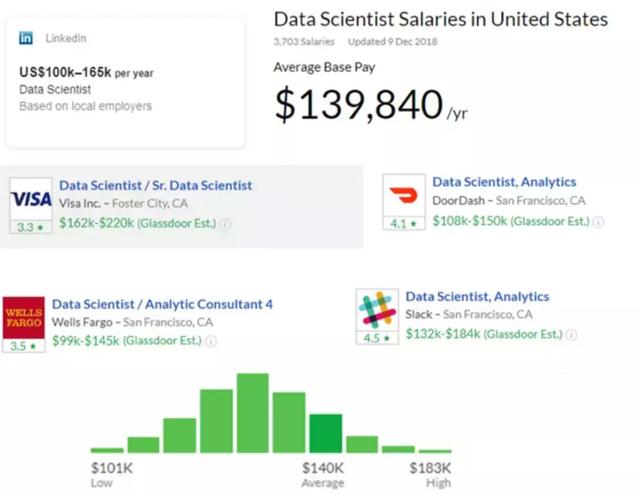
2018年,初級數據科學家的平均工資為11.5萬美元,管理10至15人團隊的人可以要求高達35萬美元的工資。與此同時,數據科學家的平均工作年限從2014年的9年降至2015年的6年。到2019年,全球對數據科學家的需求預計將超過供應的50%。超過40%的公司認為他們招聘數據科學家的無能阻礙了他們的競爭力,難怪超過60%的公司內部培訓他們的員工。
Andrew Ng
有兩種方法可以填補這一空白:
有兩種主要方法可以幫助緩解這種技能短缺。首先,人工智能超級明星Andrew NG支持的一種方法是使用非傳統的方法來培訓更多的數據科學家,比如大規模在線開放課程(MOOCs)。雖然這對于當前的開發人員和其他以數據為中心的員工來說是一種“提高技能”的好方法,但它還不是更大問題的解決方案。我說“還沒有”,是因為這從根本上要求改變行為。雇主還沒有對這種教育給予足夠的重視,許多雇主在招聘時仍然只看名牌大學。雖然這種心態正在緩慢地改變,但它來得不夠快,不足以在中短期內解決問題。
第二種方法是讓更多沒有數據科學技能的人能夠輕松地將這些復雜的技術應用到公司數據中。本質上,讓人工智能和機器學習解決自己的問題。通過使用過去幾年開發的技術(包括這里的MindsDB),可以模擬數據科學家,這樣即使是非技術人員也可以通過幾行代碼或幾次單擊來執行數據分析。
這兩種解決方案并不是相互排斥的,它們將協同幫助企業以更有意義的方式使用數據,從而推動成本節約和/或推動增長和收入。為了有效地實現這一目標,企業內部需要進行文化變革,從而制定更好的招聘政策,更好地使用工具和軟件,這些工具和軟件可以解決企業面臨的許多數據問題,而不需要擴大員工數量,也不需要聘請昂貴的數據科學家。