什么是“錕斤拷”?我竟答不上來......
周末女朋友出去逛街了,我自己一個人在家看綜藝節目,突然,女朋友給我打來電話。





過了一會,女朋友回來了,她拿出手機,給我看了她在超市拍的照片:





要想知道什么是亂碼,需要先從計算機編碼說起。
字符編碼和 ASCII
我們經常看一些諜戰劇,諜戰劇里敵特、地下黨員以及八路軍各部間發送情報的時候,一般都是通過電報發送的。
電報在傳遞的過程中,需要發報員用電鍵發出長短不一的電碼,收報員就會聽到電報機發出的滴滴滴答答答的聲音。
其實電報發出的聲音都是"滴"和"答"的組合,"答"的聲音是"滴"的三倍長。
發報員要先通過一種方式,將想要發送的情報轉成電報的滴答聲,收報員在聽到滴答聲之后,再將它們翻譯成正常的文字。這個過程就是字符編碼和字符解碼。
諜戰劇中將情報轉成電報的"滴"和"答"聲主要通過摩爾斯電碼,這是一種通過不同的排列順序來表達不同的英文字母、數字和標點符號的字符編碼方式。
莫爾斯電碼由短的和長的電脈沖(稱為點和劃)所組成。點和劃的時間長度都有規定,以一點為一個基本單位,一劃等于三個點的長度。正好對應上電報的"滴"和"答"。

就像電報只能發出"滴"和"答"聲一樣,計算機只認識 0 和 1 兩種字符,但是,人類的文字是多種多樣的,如何把人類的文字轉換成計算機認識的 01 字符呢,這個過程同樣需要通過字符編碼。
字符編碼(Character encoding)是一套法則,使用該法則能夠對自然語言的字符的一個集合(如字母表或音節表),與其他東西的一個集合(如號碼或電脈沖)進行配對。
和摩爾斯電碼功能類似,上個世紀 60 年代,美國制定了一套字符編碼,對英語字符與二進制位之間的關系,做了統一規定,這被稱為 ASCII 碼,一直沿用至今。
ASCII(American Standard Code for Information Interchange,美國信息交換標準代碼)是基于拉丁字母的一套計算機編碼系統。
它主要用于顯示現代英語,其中共有 128 個字符,包含了所有的大寫和小寫字母,數字 0 到 9、標點符號, 以及在美式英語中使用的特殊控制字符等。
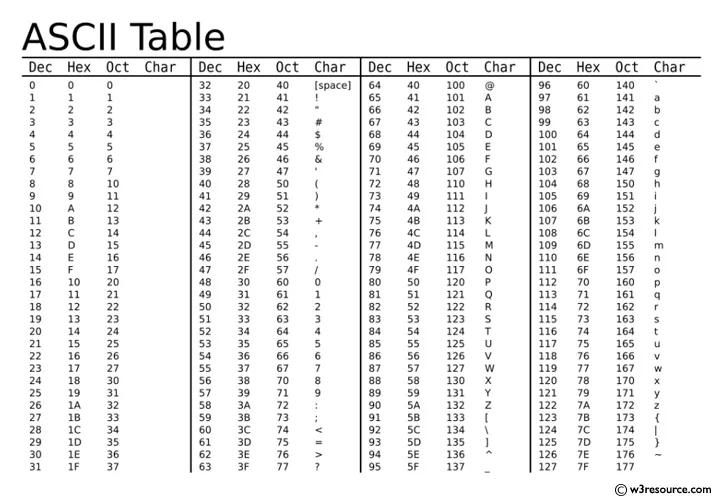



由于 ASCII 只有 128 個字符,雖然對于英文字符都可以表示了,但是世界上還有很多其他的文字他是沒辦法表示的,所以需要一種更加全面的字符編碼。
在介紹其他的字符編碼之前,我們先來說一下一個計算機領域通用的字符集。
Unicode
Unicode(中文:萬國碼、國際碼、統一碼、單一碼)是計算機科學領域里的一項業界標準。
它對世界上大部分的文字系統進行了整理、編碼,使得計算機可以用更為簡單的方式來呈現和處理文字。
Unicode 至今仍在不斷增修,每個新版本都加入更多新的字符。目前最新的版本為 2019 年 5 月公布的 12.1,這一版本只新增了 1 個字符,即日本新年號令和的合字。

Unicode 備受認可,并廣泛地應用于計算機軟件的國際化與本地化過程。有很多新科技,如可擴展置標語言(Extensible Markup Language,簡稱:XML)、Java 編程語言以及現代的操作系統,都采用 Unicode 編碼。
Unicode 是一套通用的字符集,包含世界上的大部分文字,也就是說,Unicode 是可以表示中文的。


UTF-8,UTF-16,UTF-32
Unicode 雖然統一了全世界字符的編碼,但沒有規定如何存儲。這么做是有考慮的:如果 Unicode 統一規定,每個符號就要用 3 個或 4 個字節表示,因為字符太多,只能用這么多字節才能表示完全。
一旦這么規定,那么每個英文字母前都必然有 2 到 3 個字節是 0,因為所有英文字母在 ASCII 中都有,都可以用 1 個字節表示,剩余字節位置就要補充 0。
如果這樣,文本文件的大小會因此大出二三倍,這對于存儲來說是極大的浪費。
為了解決這個問題,就出現了一些中間格式的字符集,他們被稱為通用轉換格式,即 UTF(Unicode Transformation Format)。
常見的 UTF 格式有:
- UTF-7
- UTF-7.5
- UTF-8
- UTF-16
- UTF-32
UTF-8:使用 1 至 4 個字節為每個字符編碼,UTF-16:使用 2 或 4 個字節為每個字符編碼,UTF-32:使用 4 個字節為每個字符編碼。
所以我們可以說,UTF-8、UTF-16 等都是 Unicode 的一種實現方式。
舉個例子,Unicode 規定了 1 個中文字符 "我"對應的 Unicode 是 "\u6211",但是,在 UTF-8 和 UTF-16 等不同的實現方式下,這個二進制 Code 的存儲方式是不一樣的。
UTF-8 使用可變長度字節來儲存 Unicode 字符,例如 ASCII 字母繼續使用 1 字節儲存,重音文字、希臘字母或西里爾字母等使用 2 字節來儲存,而常用的漢字就要使用 3 字節。輔助平面字符則使用 4 字節。



GBK,GB2312,GB18030
因為 UTF-8 是 Unicode 的一種實現,所以他包含了世界上的所有文字的編碼,他采用的是 1-4 字節進行編碼。
對于那些排在前面優先納入的文字,可能就優先使用 1 字節、2 字節存儲了,對于后納入的文字,就要使用 3 字節或者 4 字節存儲了。
正是因為他太全了,所以那些晚一些納入的字符,在 UTF-8 中的存儲所占的字節數可能就會多一些,那他的存儲空間要求就會很大。
對于常用的漢字,在 UTF-8 中采用 3 字節進行編碼,但是如果有一種只包含中文和 ASCII 的編碼的話,就不需要使用 3 個字節,可能 2 個字節就夠了。
對于大部分網站來說,基本都是只服務一個國家或者地區的,比如一個中國的網站,一般會出現簡體字和繁體字以及一些英文字符,很少會出現日語或者韓文的。
也是出于這樣的考慮,中國國家標準總局于 1981 年制定并實施了 GB 2312-80 編碼,即中華人民共和國國家標準簡體中文字符集。
后來廠商微軟利用 GB 2312-80 未使用的編碼空間,收錄 GB 13000.1-93 全部字符制定了 GBK 編碼。
有了標準中文字符集,如果是一個純中文網站,就可以采用這種編碼方式,這樣可以大大節省一些存儲空間的。
常用的中文編碼有 GBK,GB2312,GB18030 等,最常用的是 GBK。
GB2312(1980 年),16 位字符集,收錄有 6763 個簡體漢字,682 個符號,共 7445 個字符:
- 優點:適用于簡體中文環境,屬于中國國家標準,通行于大陸,新加坡等地。
- 缺點:不兼容繁體中文,其漢字集合過少。
GBK(1995 年),16 位字符集,收錄有 21003 個漢字,883 個符號,共 21886 個字符:
- 優點:適用于簡繁中文共存的環境,為簡體 Windows 所使用,向下完全兼容 GB2312,向上支持 ISO-10646 國際標準 ;所有字符都可以一對一映射到 Unicode 2.0 上。
- 缺點:不屬于官方標準和 big5 之間需要轉換;很多搜索引擎都不能很好地支持 GBK 漢字。
GB18030(2000 年),32 位字符集;收錄了 27484 個漢字,同時收錄了藏文、蒙文、維吾爾文等主要的少數民族文字:
優點:可以收錄所有你能想到的文字和符號,屬于中國最新的國家標準。
缺點:目前支持它的軟件較少。


亂碼
我們還拿前面介紹過的發電報的例子來說,假設有以下場景:發報員使用“美式摩爾斯電碼”將情報轉換成電報,收報員接收到電報之后,通過“現代國際摩爾斯電碼”進行破譯。那么得到的情報內容就可能完全看不懂,這就是亂碼了。
就像在計算機領域,我們把一串中文字符通過 UTF-8 進行編碼傳輸給別人,別人拿到這串文字之后,通過 GBK 進行解碼,得到的內容就會是“錕屆瀿錕斤拷雮傡錕斤拷直錕斤拷錕”,這就是亂碼。
如以下代碼:
- public static void main(String[] args) throws UnsupportedEncodingException {
- String s = "漫話編程!";
- byte[] bytes = s.getBytes(Charset.forName("GBK"));
- System.out.println("GBK編碼,GBK解碼:" + new String(bytes, "GBK"));
- System.out.println("GBK編碼,GB18030解碼:" + new String(bytes, "GB18030"));
- System.out.println("GBK編碼,UTF-8解碼:" + new String(bytes, "UTF-8"));
- }
輸出結果:
- GBK編碼,GBK解碼:漫話編程!
- GBK編碼,GB18030解碼:漫話編程!
- GBK編碼,UTF-8解碼:????????
可以看到,將中文字符,通過 GBK 編碼,再使用 UTF-8 解碼,得到的字符就是一串問號,這就是亂碼了。



錕斤拷的前世今生
因為 Unicode 是一直在更新的,在這個過程中,肯定有一些比較新的字符他是無法表示的。
或者即使 Unicode 發布了新版納入了某個文字,但是很多軟件系統并未升級也會有這樣的問題。
就像生活中一些手機廠商新出的那些 emoji 表情,在自己的手機上可以正常顯示,發到其他品牌的手機上可能就無法顯示。這其實也是字符集不支持導致的。
發生以上情況時,無法顯示的時候也需要有一個字符來表示的,在 Unicode 中,這個字符就是 � ,他也是 Unicode 中定義的一個特殊字符。
也就是"0xFFFD REPLACEMENT CHARACTER",所有無法表示的字符都會通過這個字符來表示。
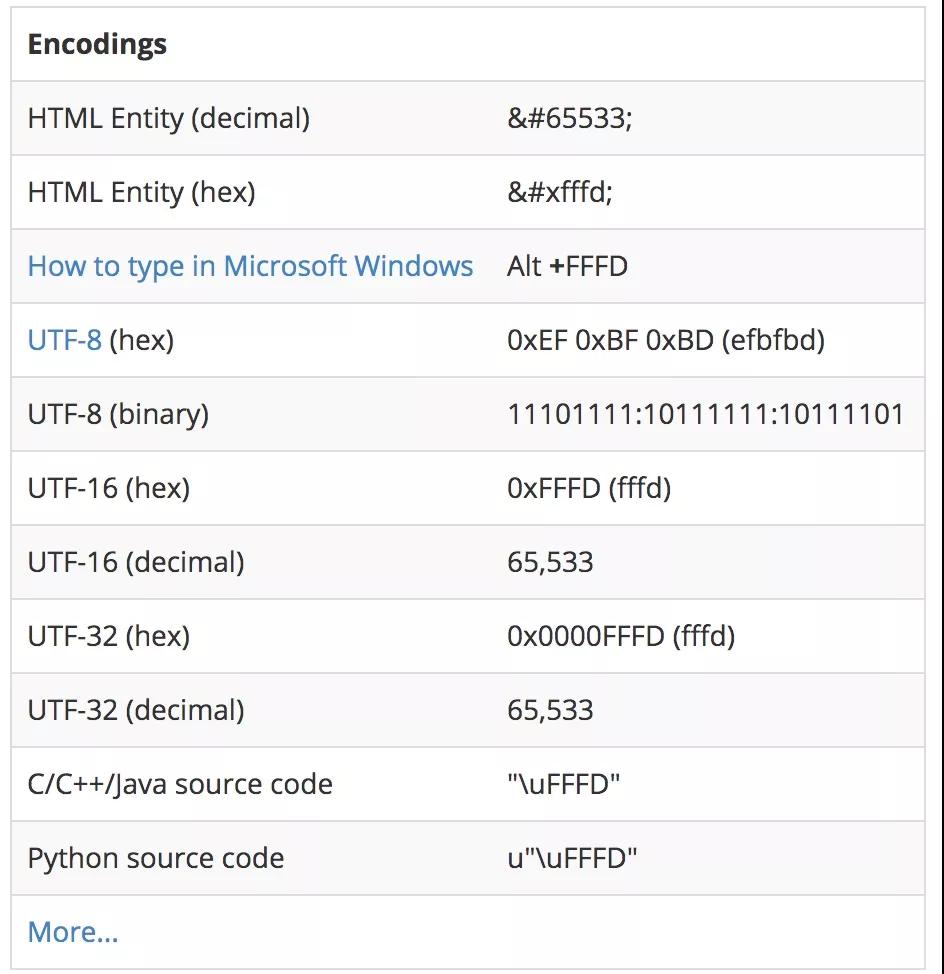
Unicode 官方有關于這個符號的介紹,從上表中可以看到,他的 10 進制表示是 65533,在 UTF-8 下,他的 16 進制形式是'0xEF 0xBF 0xBD'(三個字節)。
如果有兩個連續的字符都無法顯示,如"� �" ,那么在 UTF-8 編碼下,16 進制表示為:
- 0xEF 0xBF 0xBD
- 0xEF 0xBF 0xBD
以上這段編碼,如果放到 GBK 中進行解碼的話,因為 GBK 中一個漢字兩個字節,那么結果就是:
- 0xEF 0xBF, 0xBD 0xEF, 0xBF 0xBD
即:
- 0xEFBF
- 0xBDEF
- 0xBFBD
那么,如果展示出來,就是:錕(0xEFBF),斤(0xBDEF),拷(0xBFBD)。
所以,以后再見到錕斤拷,第一時間想到 UTF-8 和 GBK 的轉換問題準沒錯。
除了錕斤拷以外,還有兩組比較經典的亂碼,分別是"燙燙燙"和"屯屯屯",這兩個亂碼產生自 VC,這是 Debug 模式下 VC 對內存的初始化操作。
VC 會把棧中新分配的內存初始化為 0xcc,而把堆中新分配的內存初始化為 0xcd。把 0xcc 和 0xcd 按照字符打印出來,就是燙和屯了。