













MySQL如何優化大分頁查詢?

一 背景
大部分開發和DBA同行都對分頁查詢非常非常了解,看帖子翻頁需要分頁查詢,搜索商品也需要分頁查詢。那么問題來了,遇到上千萬或者上億的數據量怎么快速的拉取全量,比如大商家拉取每月千萬級別的訂單數量到自己獨立的ISV做財務統計;或者擁有百萬千萬粉絲的公眾大號,給全部粉絲推送消息的場景。本文講講個人的優化分頁查詢的經驗,拋磚引玉。
二 分析
在講如何優化之前我們先來看看一個比較常見錯誤的寫法
- SELECT * FROM tablewhere kid=1342 and type=1 order id asc limit 149420 ,20;
該SQL是一個非常典型的排序+分頁查詢:
- order by col limit N,M
MySQL 執行此類SQL時需要先掃描到N行,然后再去取M行。對于此類操作,獲取前面少數幾行數據會很快,但是隨著掃描的記錄數越多,SQL的性能就會越差,因為N的值越大,MySQL需要掃描越多的數據來定位到具體的N行,這樣耗費大量的 IO 成本和時間成本。一圖勝千言,我們使用簡單的圖來解釋為什么 上面的sql 的寫法掃描數據會慢。
t 表是一個索引組織表,key idxkidtype(kid,type) 。
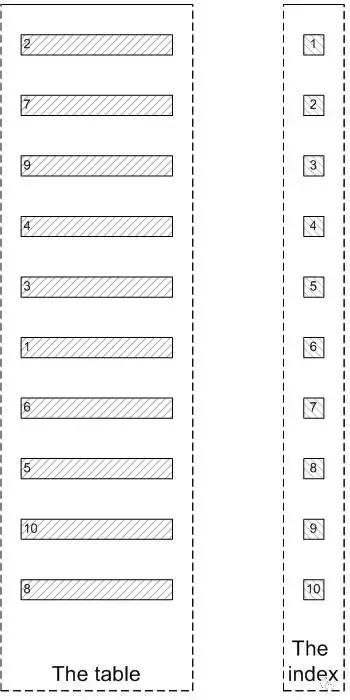
符合kid=3 and type=1 的記錄有很多行,我們取第 9,10行。
- select * from t where kid =3 and type=1 order by id desc 8,2;
MySQL 是如何執行上面的sql 的?對于Innodb表,系統是根據 idxkidtype 二級索引里面包含的主鍵去查找對應的行。對于百萬千萬級別的記錄而言,索引大小可能和數據大小相差無幾,cache在內存中的索引數量有限,而且二級索引和數據葉子節點不在同一個物理塊兒上存儲,二級索引與主鍵的相對無序映射關系,也會帶來大量的隨機IO請求,N值越大越需要遍歷大量索引頁和數據葉,需要耗費的時間就越久。
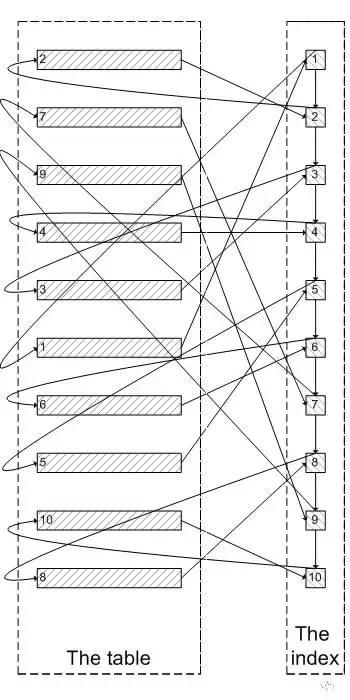
鑒于上面的大分頁查詢耗費時間長的原因,我們思考一個問題,是否需要完全遍歷“無效的數據”?如果我們需要limit 8,2;我們跳過前面8行無關的數據頁遍歷,可以直接通過索引定位到第9,第10行,這樣操作是不是更快了?依然是一圖勝千言,通過這其實也是 延遲關聯的 核心思思:通過使用覆蓋索引查詢返回需要的主鍵,再根據主鍵關聯原表獲得需要的數據,而不是通過二級索引獲取主鍵再通過主鍵去遍歷數據頁。
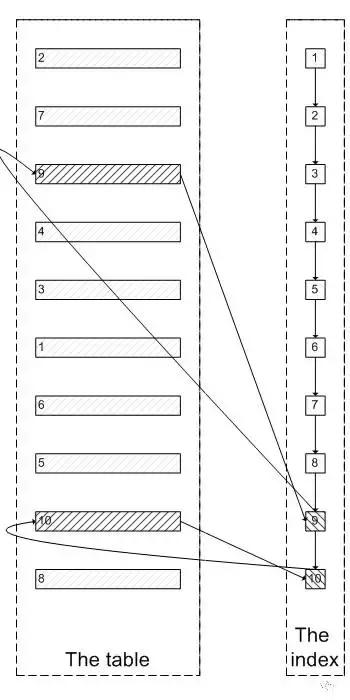
通過上面的原理分析,我們知道通過常規方式進行大分頁查詢慢的原因,也知道了提高大分頁查詢的具體方法 ,下面我們討論一下在線上業務系統中常用的解決方法。
三 實踐出真知
針對limit 優化有很多種方式:
1 前端加緩存、搜索,減少落到庫的查詢操作。比如海量商品可以放到搜索里面,使用瀑布流的方式展現數據,很多電商網站采用了這種方式。
2 優化SQL 訪問數據的方式,直接快速定位到要訪問的數據行。
3 使用書簽方式 ,記錄上次查詢最新/大的id值,向后追溯 M行記錄。
對于第二種方式 我們推薦使用"延遲關聯"的方法來優化排序操作,何謂"延遲關聯" :通過使用覆蓋索引查詢返回需要的主鍵,再根據主鍵關聯原表獲得需要的數據。
3.1 延遲關聯
優化前
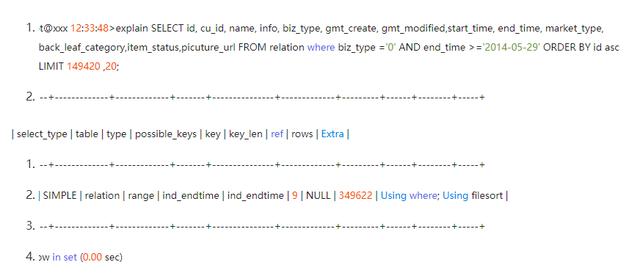
其執行時間:

優化后:

執行時間:

優化后 執行時間 為原來的1/3 。
3.2 使用書簽的方式
首先要獲取復合條件的記錄的最大 id和最小id(默認id是主鍵)
- select max(id) as maxid ,min(id) as minid from t where kid=2333 and type=1;
其次 根據id 大于最小值或者小于最大值 進行遍歷。
- select xx,xx from t where kid=2333 and type=1 and id >=min_id order by id asc limit 100;
- select xx,xx from t where kid=2333 and type=1 and id <=max_id order by id desc limit 100;
案例
當遇到延遲關聯也不能滿足查詢速度的要求時
- SELECT a.id as id, clientid, adminid, kdtid, type, token, createdtime, updatetime, isvalid, version FROM t1 a, (SELECT id FROM t1 WHERE 1 and client_id = 'xxx' and is_valid= '1' order by kdt_id asc limit 267100,100 ) b WHERE a.id = b.id;

使用延遲關聯查詢數據510ms ,使用基于書簽模式的解決方法減少到10ms以內 絕對是一個質的飛躍。
- SELECT * FROM t1 where clientid='xxxxx' and isvalid=1 and id<47399727 order by id desc LIMIT 100;

四 小結
從我們的優化經驗和案例上來講,根據主鍵定位數據的方式直接定位到主鍵起始位點,然后過濾所需要的數據 相對比延遲關聯的速度更快些,查找數據的時候少了二級索引掃描。但是 優化方法沒有銀彈,沒有一勞永逸的方法。比如下面的例子
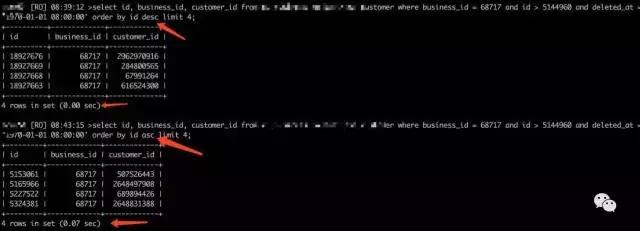
order by id desc 和 order by asc 的結果相差70ms ,生產上的案例有limit 100 相差1.3s ,這是為什么呢?留給大家去思考吧。
最后,其實我相信還有其他優化方式,比如在使用不到組合索引的全部索引列進行覆蓋索引掃描的時候使用 ICP 的方式 也能夠加快大分頁查詢。以上是我在優化分頁查詢方面的經驗總結,拋磚引玉,有興趣的朋友可以多交流,分享你們的優化經驗案例。

















