探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
概述
今天主要探討下Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)--字節(jié)序和字符集,下面一起來(lái)看看吧~
1、字節(jié)序
Oracle安裝在不同的服務(wù)器架構(gòu)平臺(tái),數(shù)據(jù)文件所采用的字節(jié)序也不相同。字節(jié)序有兩種,Big Endian和Little Endian。比如一般我們Windows或者Linux服務(wù)器用的CPU是Intel/AMD架構(gòu),那么數(shù)據(jù)文件保存格式為L(zhǎng)ittle Endian,如果用的是IBM的Power PC,那么數(shù)據(jù)文件保存格式為Big Endian。
Big Endian和Little Endian具體在保存數(shù)據(jù)時(shí)有什么區(qū)別呢?我們舉例說(shuō)明。
整數(shù)1920如果用4個(gè)字節(jié)(十六進(jìn)制0X00000780)保存,那么在Big Endian的保存方法如下表所示。
據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集") 探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
我們?cè)賮?lái)看看Little Endian的保存方法。
據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集") 探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
根據(jù)上面的內(nèi)容,我們可以知道在Little Endian下,保存整數(shù)1920是反向的
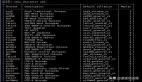
以下列出各個(gè)服務(wù)器平臺(tái)的ENDIAN格式。
據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集") 探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
2、字符集
計(jì)算機(jī)當(dāng)初發(fā)明時(shí)大多用來(lái)處理數(shù)字,后來(lái)慢慢的用來(lái)處理文字。問(wèn)題來(lái)了,計(jì)算機(jī)可不認(rèn)識(shí)全世界這么多文字,甚至連26個(gè)英文字母也不認(rèn)識(shí)。于是美國(guó)國(guó)家標(biāo)準(zhǔn)協(xié)會(huì)ANSI開始制作標(biāo)準(zhǔn),比如用65表示字母A,用66來(lái)表示字母B,包括26個(gè)大小寫字母,數(shù)字和一些符號(hào)(100多個(gè)),這就是最初的ASCII碼。當(dāng)初ASCII碼沒有超過(guò)128個(gè),只用了7位來(lái)表示,最高位留給用作奇偶校驗(yàn)。后來(lái)又被歐洲擴(kuò)展到了8位,可以用來(lái)表示256個(gè)字符。
ASCII碼并沒有包括中文,要讓計(jì)算機(jī)認(rèn)識(shí)中文,中國(guó)的標(biāo)準(zhǔn)化機(jī)構(gòu)也開始制作了一些標(biāo)準(zhǔn)(GBK)。中國(guó)的漢字太多了,用一個(gè)字節(jié)可裝不下這么多(8個(gè)二進(jìn)制位最多表示256個(gè)字符),于是采用了2個(gè)字節(jié)(理論上可以表示65536個(gè)字符),其他國(guó)家和地區(qū)也沒有閑著,比如日本的Shift_JIS編碼,中國(guó)香港臺(tái)灣的BIG5編碼,于是全世界產(chǎn)生了各種各種的字符編碼。
這樣問(wèn)題又來(lái)了,而且是大問(wèn)題。大家都各搞各的,這么多編碼,自己本地傳輸信息當(dāng)然沒有問(wèn)題。但是當(dāng)一個(gè)中國(guó)人發(fā)GBK編碼的中文郵件給日本人,日本人的電腦如果只認(rèn)識(shí)Shift_JIS編碼,那么計(jì)算機(jī)將會(huì)把所有GBK編碼按照Shift_JIS編碼來(lái)解釋,于是日本人看到的是所謂的“亂碼”。之所以叫所謂,因?yàn)橛?jì)算機(jī)自認(rèn)為它并沒有做錯(cuò),那些“亂碼”也是對(duì)應(yīng)的字符,只是不常用,日本人看不懂而已,計(jì)算機(jī)懂的。
于是地球上的標(biāo)準(zhǔn)化組織領(lǐng)導(dǎo)們又開會(huì)討論了,還提出了一個(gè)偉大的想法,這就是UNICODE字符集。這種字符集的想法是用一套字符集把地球上所有的文字都包括進(jìn)來(lái)。當(dāng)然2個(gè)字節(jié)可裝不下全世界的所有字符,采用了4個(gè)字節(jié)(理論上可以表示4294967296個(gè)字符)。用UNICODE字符集實(shí)現(xiàn)的編碼有UTF32/UTF16/UTF8。
上面扯了這么多,那么我們?cè)谛陆〝?shù)據(jù)庫(kù)的時(shí)候,需要選擇數(shù)據(jù)庫(kù)的數(shù)據(jù)庫(kù)字符集(CHARACTER SET)和國(guó)家字符集(NATIONAL CHARACTER SET)。比如我們選擇數(shù)據(jù)庫(kù)字符集為 ZHS16GBK,國(guó)家字符集為AL16UTF16。它表示這個(gè)數(shù)據(jù)庫(kù)里Char,Varchar2采用的是GBK的編碼,而Nchar,Nvarchar2,Nclob采用UTF16編碼。
據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集") 探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
好,下面我們來(lái)做一個(gè)試驗(yàn),看看這些字符集里到底保存了什么內(nèi)容。
SQL> SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER LIKE '%CHARACTERSET%';
SQL> CREATE TABLE TESTCHAR (COL1 VARCHAR2(100),COL2 NVARCHAR2(100));
SQL> INSERT INTO TESTCHAR VALUES('DBSEEKER+廣東省廣州市','DBSEEKER+廣東省廣州市');
SQL> SELECT DUMP(COL1,16),DUMP(COL2,16) FROM TESTCHAR;據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集") 探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集") 探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
在上面我們新建一張表,表有兩個(gè)字段,COL1的字段類型為VARCHAR2使用的是數(shù)據(jù)庫(kù)字符集(ZHS16GBK),COL2的字段類型為NVARCHAR2使用國(guó)家字符集(AL16UTF16)。往兩個(gè)字段插入了同樣的文本內(nèi)容'DBSEEKER+廣東省廣州市'。
接下來(lái),我們DUMP了字段保存的十六進(jìn)制內(nèi)容,觀察到字段COL1的長(zhǎng)度為21個(gè)字節(jié),而字段COL2的長(zhǎng)度為30字節(jié),為什么同樣的文本內(nèi)容保存在VARCHAR2和NVARCHAR2里面,底層的存儲(chǔ)內(nèi)容完全不同呢?
原因就在于COL1和COL2使用了不同的字符集,不同字符集對(duì)應(yīng)相同文字編碼定義也是不一樣的。
COL1使用GBK編碼,各個(gè)字節(jié)對(duì)應(yīng)的字符。
據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集") 探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
COL2使用UTF16編碼,各個(gè)字節(jié)對(duì)應(yīng)的字符。
據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集") 探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
探討Oracle數(shù)據(jù)庫(kù)底層存儲(chǔ)---字節(jié)序和字符集
通過(guò)上面觀察,我們可以知道GBK編碼是變長(zhǎng)的,英文字母用1個(gè)字節(jié)保存,漢字用2個(gè)字節(jié)來(lái)保存。而UTF16則都是用2個(gè)字節(jié)來(lái)保存。Oracle數(shù)據(jù)文件里保存的文本字段內(nèi)容就是各種編碼表相對(duì)應(yīng)的字符編碼。