Oracle和MySQL的JDBC到底有多慢?
經(jīng)常聽(tīng)人說(shuō),數(shù)據(jù)庫(kù)的IO性能不佳,但說(shuō)歸說(shuō),并沒(méi)有感性認(rèn)識(shí)。我們現(xiàn)在就來(lái)實(shí)際測(cè)試一下,常用的Oracle和MySQL的JDBC讀取性能如何。
之所以測(cè)試JDBC,是因?yàn)榇蟛糠謶?yīng)用是JAVA寫的,也就只能用JDBC來(lái)訪問(wèn)數(shù)據(jù)。這里僅測(cè)試用JDBC讀出數(shù)據(jù),并產(chǎn)生成Java的記錄對(duì)象(畢竟到了這一步才能在應(yīng)用中使用),不作任何計(jì)算。
1. 數(shù)據(jù)來(lái)源
使用TPCH生成的數(shù)據(jù),選用其中的customer表來(lái)做測(cè)試,數(shù)據(jù)記錄為3000萬(wàn)行,8個(gè)字段。它生成的原始文本文件名為customer.tbl,文件大小為4.9G。利用數(shù)據(jù)庫(kù)提供的數(shù)據(jù)導(dǎo)入工具將此文件數(shù)據(jù)導(dǎo)入到Oracle和MySQL的數(shù)據(jù)表中。
2. 測(cè)試環(huán)境
在一臺(tái)Intel服務(wù)器上完成測(cè)試,2個(gè)Intel2670 CPU,主頻2.6G,共16核,內(nèi)存64G。數(shù)據(jù)庫(kù)表數(shù)據(jù)及文本文件均存儲(chǔ)在同一塊SSD硬盤上。
所有測(cè)試均在服務(wù)器本機(jī)上完成,沒(méi)有消耗網(wǎng)絡(luò)傳輸時(shí)間。
3. 數(shù)據(jù)庫(kù)讀數(shù)測(cè)試
通過(guò)Oracle提供的JDBC接口,用SQL語(yǔ)句執(zhí)行數(shù)據(jù)讀取。
Java寫起來(lái)麻煩,用SPL腳本執(zhí)行測(cè)試:

MySQL的測(cè)試代碼類似,不再贅述。
測(cè)試結(jié)果(時(shí)間單位:秒)

第二次可能由于操作系統(tǒng)有了硬盤緩存,所以更快。因?yàn)槲覀冎饕菫榱藴y(cè)試JDBC的讀取時(shí)間,所以就以第二次為準(zhǔn),減少數(shù)據(jù)庫(kù)本身從硬盤讀數(shù)的影響。每秒讀出行數(shù)也是按第二次時(shí)間來(lái)計(jì)算的,也就是說(shuō),Oracle每秒能讀出10萬(wàn)行多數(shù)據(jù),MySQL大概接近8萬(wàn)行。當(dāng)然這個(gè)值和表的字段數(shù)及類型都有關(guān)(customer表有8個(gè)字段),只是一種參考。
4. 文本文件對(duì)比
只從上面的數(shù)據(jù)量還沒(méi)有太多感性認(rèn)識(shí),我們?cè)僮x一下文本文件來(lái)對(duì)比。辦法是一樣的,從文件中讀出數(shù)據(jù),并解析出記錄,不作任何計(jì)算。
編寫如下SPL腳本執(zhí)行測(cè)試:
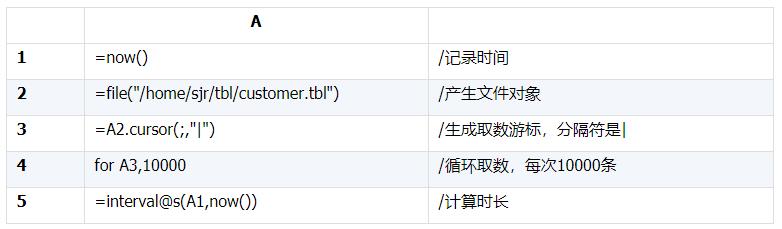
測(cè)試結(jié)果是42秒!
這意味著,讀取文本要比讀取Oracle快281/42=6.69倍,比MySQL要快381/42=9.07倍!
我們知道,文本解析是個(gè)非常麻煩的事情,但即使這樣,從文本文件讀取數(shù)據(jù)還是遠(yuǎn)遠(yuǎn)快于從數(shù)據(jù)庫(kù)中讀數(shù)。Oracle和MySQL的IO實(shí)在是太慢了!
5. 二進(jìn)制方式
我們進(jìn)一步再看使用二進(jìn)制方式的存儲(chǔ)格式的讀取性能,并和文本比對(duì)。
為了對(duì)比明顯,這次換一個(gè)更大的表,用TPCH中的orders表,有3億行數(shù)據(jù),9個(gè)字段。
文本讀取的代碼和上面類似,讀取時(shí)間測(cè)試為438秒。
然后,我們將這個(gè)文本文件轉(zhuǎn)換成SPL組表,再寫代碼測(cè)試:
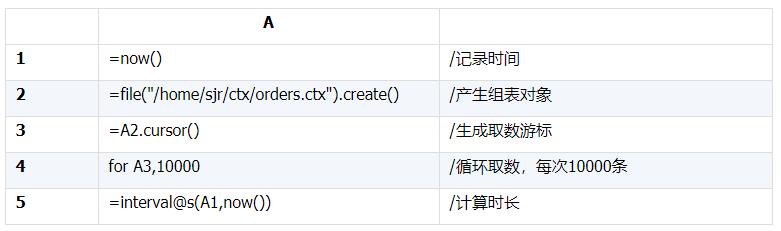
測(cè)試結(jié)果是164秒,大概僅僅是文本讀取的三分之一。
這是情理之中的事情,因?yàn)槎M(jìn)制數(shù)據(jù)不再需要解析,可以直接產(chǎn)生對(duì)象,計(jì)算量少了很多,因而要更快。
需要說(shuō)明的是,組表文件雖然采用列存格式,但在這里讀出了所有列,并沒(méi)有比文本少取任何內(nèi)容,沒(méi)有占列存的便宜。事實(shí)上,因?yàn)樽x所有列,使用列存還會(huì)吃點(diǎn)虧,如果采用SPL集文件(一種行存格式)還會(huì)更快。
6. 并行提速
從文件中取數(shù)還很容易實(shí)現(xiàn)并行,文本和組表都容易寫出并行程序。還是用上面的orders表為例來(lái)測(cè)試,使用4線程取數(shù)。
文本取數(shù)代碼:

組表取數(shù)代碼:

用SPL很容易實(shí)現(xiàn)數(shù)據(jù)分段和并行計(jì)算。
測(cè)試結(jié)果為:
文本 119秒
組表 43秒
與串行相比,接近了線性提升,將CPU的多核充分利用起來(lái)了。
數(shù)據(jù)庫(kù)中的數(shù)據(jù)則不容易簡(jiǎn)單地實(shí)施分段并行,需要用WHERE條件去拼,結(jié)果很難說(shuō)清到底是并行不力還是WHERE執(zhí)行損失太多,測(cè)試結(jié)果的參考意義就打折扣了,這里就不再做了。
7. 結(jié)論
數(shù)據(jù)庫(kù)(Oracle和MySQL)的JDBC性能非常非常差!比文本文件還要差5倍以上。而采用二進(jìn)制數(shù)據(jù)時(shí),會(huì)比文本再提高3倍的讀取性能。也就是說(shuō),合理格式的二進(jìn)制文件會(huì)比數(shù)據(jù)庫(kù)有15倍以上的優(yōu)勢(shì)。再考慮到并行因素,比數(shù)據(jù)庫(kù)快出幾十上百倍也是完全可能的。
在關(guān)注性能且數(shù)據(jù)量較大時(shí),千萬(wàn)不要把數(shù)據(jù)讀出數(shù)據(jù)庫(kù)計(jì)算!
如果實(shí)在需要讀出后再計(jì)算(有時(shí)SQL很難寫出復(fù)雜的過(guò)程計(jì)算),就不要再用數(shù)據(jù)庫(kù)存儲(chǔ)了(大數(shù)據(jù)都是歷史,基本也不再改了,可以事先讀出),用文本都比數(shù)據(jù)庫(kù)強(qiáng),用二進(jìn)制當(dāng)然更好(推薦使用SPL組表,哈哈)。切不要把時(shí)間浪費(fèi)在讀數(shù)這種非計(jì)算任務(wù)上了。