用Python爬取前程無憂網大數據崗位信息并分析!找到最合適你的
作者:一枚程序媛呀
近期秋招進入高峰期,28號學校有一個秋招大型招聘會,本來想在網上爬一下自己專業的招聘崗位,結果檢索結果寥寥無幾(攤手),于是我就無奈的爬取并分析了一波我準備轉行的大數據行業的就業行情。
近期秋招進入高峰期,28號學校有一個秋招大型招聘會,本來想在網上爬一下自己專業的招聘崗位,結果檢索結果寥寥無幾(攤手),于是我就無奈的爬取并分析了一波我準備轉行的大數據行業的就業行情。
爬蟲的基本思路
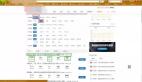
- 在前程無憂官網檢索“大數據”的結果中,每條檢索結果詳情對應的URL存在a標簽的href屬性中,通過組合選擇器可以找到每條檢索結果詳情的URL。
- 前程無憂的招聘崗位信息數據固定的放在HTML的各個標簽內,通過id選擇器、標簽選擇器和組合選擇器可以諸如公司名、崗位名稱和薪資等11個字段的數據。
- 基于上述1和2,可以通過解析檢索“大數據”得到的URL得到其HTML,再從此HTML中的具體位置的a標簽得到每個崗位的詳情對應的URL;然后解析每個崗位的詳情對應的URL得到其HTML,再從結果HTML的具體位置找到每個崗位的詳情。具體位置怎么確定呢?通過組合選擇器!
前程無憂爬蟲具體代碼
直接貼代碼容易破壞我的排版,具體代碼見:https://github.com/cugwhzenith/SpiderOf51job.git,其中SpiderOf51job.py就是爬蟲代碼,關鍵點的操作見注釋。其他的代碼是對爬蟲代碼的處理。
爬蟲結果
爬蟲結果我是以csv的格式存儲的,看起來不太直觀,所以我打算用wordcloud和直方圖來可視化爬蟲的結果。

爬蟲結果處理
一般來說,應聘者對一個工作的地點、工作名稱、薪資和需要的技術最為關心,剛好上述爬蟲的結果包含了這四個字段。
1、薪資結果的處理。在爬蟲結果中,薪資在第二列,一般是諸如“1-2萬/月”、“20萬/年”和“500/天”的結果,先判斷每個結果的最后一個字符是“年”、“月”和“天”的哪一個,確定處理的邏輯之后,再用re.sub函數將除了數字之外的字符替換為空格,最后對結果求均值就到了了每個結果的均值。具體處理見wordcloudPlotSalary.py 。
2、需要的技術的處理。考慮到大數據要使用的技術絕大多數由外國人開發,如實我把大數據要使用的技術這一字段的中文全部替換為空格,然后用jieba剔除掉一些無意義的助詞,就得到了大數據要使用的技術的詞云圖。具體代碼見wordcloudPlotJobinfo.py 。

3、工作地點和職位名稱的處理和上述2類似參見wordcloudPlotPlace.py和wordcloudPlotName.py,此處不再贅余,直接放結果。
工作地點詞云:

職位名稱詞云:

總結
- 前程無憂上大數據相關崗位出現頻率最高的是:大數據開發工程師
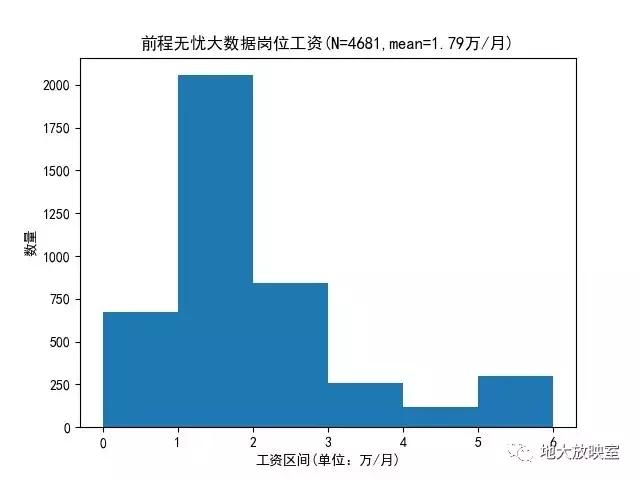
- 開出的平均工資:18K/月
- 大數據就業崗位最多的城市是:上海、廣州和深圳、
- 大數據工作最吃香的技能是:Hadoop、SQL和Python
責任編輯:未麗燕
來源:
今日頭條