XLNet作者與AMiner核心開發者聯手用AI賦能企業銷售
原創【51CTO.com原創稿件】近幾年,諸多互聯網公司紛紛搭建數據、技術、AI、組織等各種中臺,我們耳邊也充斥著五花八門的中臺概念。然萬變不離其宗,中臺化核心目的是降本增效,大多分為兩方面,一方面是合并業務之間重復部分,另一方面是為新老業務賦能。
近日,人工智能創業公司循環智能Recurrent的兩位聯合創始人,CMU計算機博士楊植麟和清華大學計算機博士張宇韜接受了51CTO專訪,他們學有所成,學以致用,運用自然語言理解、語音識別,語義理解,數據分析與挖掘等前沿技術將模型算法、人、 數據進行打通,旨在助力企業,打造以服務過程和轉化結果為核心的AI銷售中臺。
學有所成 把技術運用到實際場景
2016年,楊植麟和張宇韜本科時期在同一個實驗室,一起研究數據挖掘、處理相關技術,當時就想把所研技術落地到現實場景中,故成立了循環智能,鎖定方向為企業服務領域,為銷售以及服務行業的溝通過程,提供基于AI技術的優化升級。
當問及為何選擇銷售場景,他們說,銷售離商業模式更近些,銷售和客戶之間溝通過程中,會產生大量存量非結構化數據,這些本來沒有價值的數據,可以通過一系列技術變成有參考價值的解決方案,提升銷售效率或轉化質量。如果從更大的角度講,是想用技術去賦能溝通,溝通包含很多種,如企業與客戶、企業與企業、C端消費者之間、線下場景等。
兩人在技術領域各有所長。楊植麟成為自回歸預訓練模型 XLNet的第一作者,XLNet 在二十個任務上超過了BERT的表現,并在十八個任務上取得當前最佳效果(state-of-the-art),包括機器問答、自然語言推斷、情感分析和文檔排序。而張宇韜曾作為核心開發者研發了全球知名的科技大數據分析平臺AMiner,產品服務于BATH等科技巨頭及國家科技部等政府科研管理機構。
學以致用 打造AI銷售中臺
時至今日,循環智能完成了由真格基金領投,金沙江創投、靖亞資本、華山資本跟投的A輪融資,此前獲得金沙江創投、靖亞資本、華山資本的PreA輪融資,半年融資總額達千萬美元,依然專注于銷售和客戶之間的溝通,但已有了成熟產品組成的的閉環解決方案。
如下圖,為循環智能落地案例,AI銷售中臺于銷售端,可以銷匹配最佳線索,于客戶端,可以做畫像分析和挖掘,同時也可以做全量、全渠道的銷售質檢。
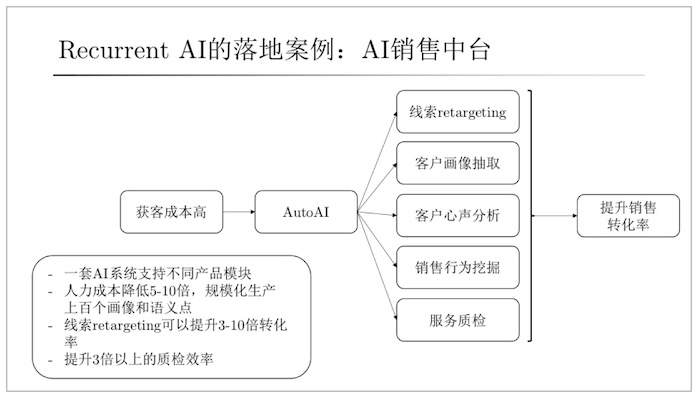
那么,這樣一個落地案例背后都需要哪些技術支持呢?自然少不了NLP,自然語言理解、語義、語氣、聲紋等識別,以及推薦系統等等。
下面介紹一下循環智能自研的語音產品和架構,如下圖所示,為自研端到端識別引擎架構圖。

銷售與客戶之間的溝通語音,可通過識別引擎得到原始識別結果,通過持續試錯,最終得到正確結果。
下圖為基于上下文的語義理解畫像模型。
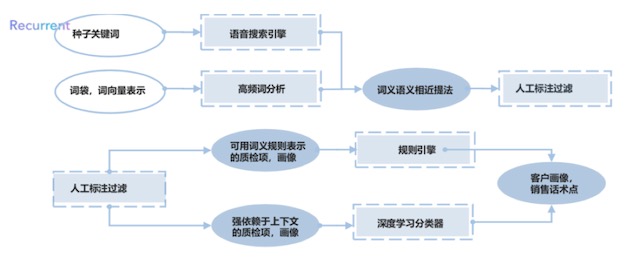
楊植麟和張宇韜表示,針對基于關鍵詞的質檢模型和畫像抽取模型在很多質檢項下會有大量錯報漏的現象, 循環智能的質檢模型將種子關鍵詞放入基于tfidf和詞向量的語音搜索引擎找到詞義和語義的相近提法(Mention),同時通過高頻詞分析獲得與質檢項相近的提法,降低漏報率。可以用規則引擎總結表示的提法,將這些提法總結成規則引擎;對于不可以用規則窮盡的提法,利用基于深度學習的文本分類,通過理解上下文語義判斷是否命中質檢項,降低錯報率。
如下圖所示,為易擴展的分布式AI架構。
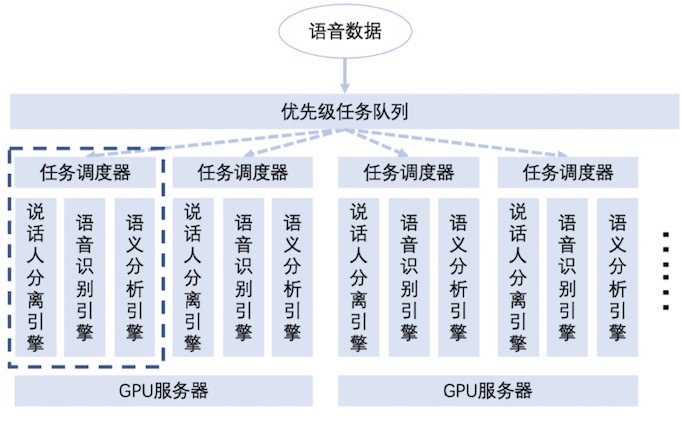
采用語音分析任務的優先級調度機制,確保高優先級任務處理的實時性。采用分布式語音、語義分析引擎,可實現計算資源的彈性擴展,數據處理能力隨計算資源線性提升。采用智能化任務調度管理,實現語音識別任務的最優化組裝,最大程度利用GPU的計算資源。這樣一來,語音識別速度可以提升三倍。
雖然這套自主知識產權的語音識別引擎,是基于原創的Transformer-XL網絡架構,可以實現語音至文本的端到端學習。但怎么去壓縮硬件成本,特別是在實時語音識別產品壓縮硬件成本,還是技術上的挑戰。如果能夠把成本壓縮下來,很多場景都能解鎖需求 ,當下也可以做實時但是成本過高,很少有客戶能夠接受。
AI銷售中臺核心競爭力:模型算法、人、 數據進行打通
當問及行業定制化的問題,他們這樣說,從原始數據到最終的價值整個鏈條是一個生產線,這個生產線可以根據新行業批量生產標準,之后再導入新行業的數據,及一些對這個行業理解放在系統中,再有標準的人員參與到這個過程中,就可以自動去完成從數據到價值。
本質上是最底層把非結構化的數據去做結構化,實現整個生產線最核心的價值,也就是提供一套生產線,把從非結構化的數據無論是語音還是文本,最終變成一個結構化可以被分析的數據。
如下圖,人也是生產流程中非常重要的節點。
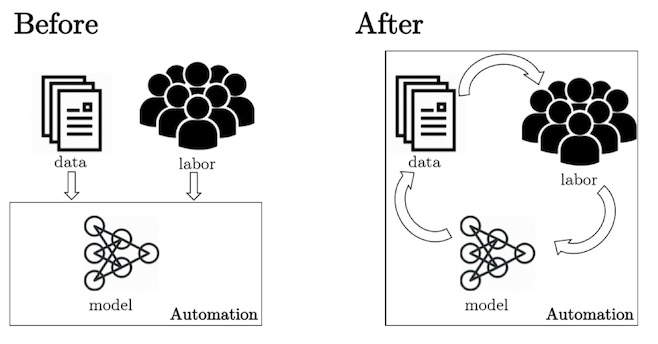
所有知識都是通過人輸入,把人整合到標準流程中,人通過調整這個系統去對每個行業去做定制化,把人包含在系統里面,故沒有定制化這種說法。
他們還介紹了,在自然語言理解方面,應用了世界領先的自然語言理解算法XLNet,實現了精準自然語言理解,對溝通對話數據進行精確畫像挖掘和心聲分析,準確率遠在傳統方法方法之上。基于深度學習的自研推薦系統,從溝通數據中提取豐富的結構化畫像,并和XLNet等深度學習方法進行有效融合。在傳統行為數據之外又引入了溝通數據,信息密度更大,表現更好。
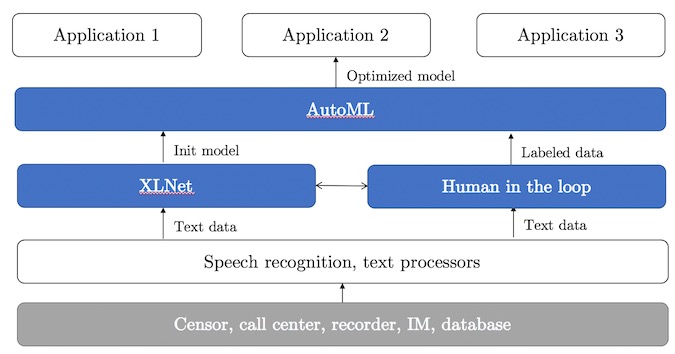
寫在最后:
當問及把AI技術真正落地到現實產品中會遇到哪些難點,楊植麟和張宇韜表示,AI模型主要關注效果層面,如何實現較高準確率或召回率是個問題,在落地時,如何得到工程化系統中更高的考慮性能方面,如成本,服務器,高并發,高吞吐量等也是個問題。如何把非結構化數據結構化,把海量文本數據過濾中間噪音和真正業務結構進行關聯,也是個問題。
當問及有哪些競爭對手,楊植麟和張宇韜表示,競爭對手主要來源于三類:可以提供標準化API接口的大廠,傳統行業做營銷的2B公司以及轉型做AI銷售中臺項目的機器人公司。
《被訪者簡介》
楊植麟:循環智能聯合創始人,產品和AI負責人,曾效力于Facebook AI Research和Google Brain,與多名圖靈獎得主合作發表論文,其發明的算法在三十余項AI標準任務上取得世界第一,是XLNet第一作者,獲阿里巴巴天池推薦系統競賽全球第二名、Nvidia先鋒研究獎,是連續入選2017-2018NLP一作排行榜的全球三人之一。楊植麟2015年本科畢業于清華大學,2019年博士畢業于卡內基梅隆大學,師從蘋果AI負責人Ruslan。
張宇韜:循環智能 聯合創始人、CTO。清華大學計算機博士,師從清華大學計算機系副系主任、數據挖掘頂級專家唐杰教授,曾作為核心開發者研發了全球知名的科技大數據分析平臺AMiner,產品服務于BATH等科技巨頭及國家科技部等政府科研管理機構。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】