













CI做到90%的行覆蓋率,真能發現BUG嗎?
這么多的CASE,花了大量時間和資源去運行,真能發現BUG嗎?CI做到90%的行覆蓋率,能發現問題嗎?測試用例越來越多,刪一些,會不會就發現不了問題了?今天,我們談談如何評估測試用例的有效性?

我們的測試用例有兩個比較關鍵的部分:
1)調用被測代碼:例如下面的RuleService.getLastRuleByClientId(ClientId)。2)進行結果Check:例如下面的AssertEqual(OrderId,"ABCD1234")。
- TestCaseA
- ...
- RuleService.createRuleByClientId(ClientId,RuleDO);
- StringOrderId=RuleService.getLastRuleByClientId(ClientId);
- ...
- TestCaseB
- ...
- RuleService.createRuleByClientId(ClientId,RuleDO);
- StringOrderId=OrderService.getLastOrderByClientId(ClientId);
- AssertEqual(OrderId,"ABCD1234");
- ...
我們希望一組測試用例不僅能夠“觸發被測代碼的各種分支”,還能夠做好結果校驗。
- 當業務代碼出現問題的時候,測試用例可以發現這個問題,我們就認為這一組測試用例是有效的。
- 當業務代碼出現問題的時候,測試用例沒能發現這個問題,我們就認為這一組測試用例是無效的。
我們對測試用例有效性的理論建模是:
>> 測試有效性 = 被發現的問題數 / 出現問題的總數
為什么要評估測試用例的有效性?

測試用例有效性評估的方法?
基于故障復盤的模式成本太高,我們希望能夠主動創造問題來評估測試用例的有效性。
我們找到了一種衡量“測試有效性”的方法,變異測試(mutation testing):
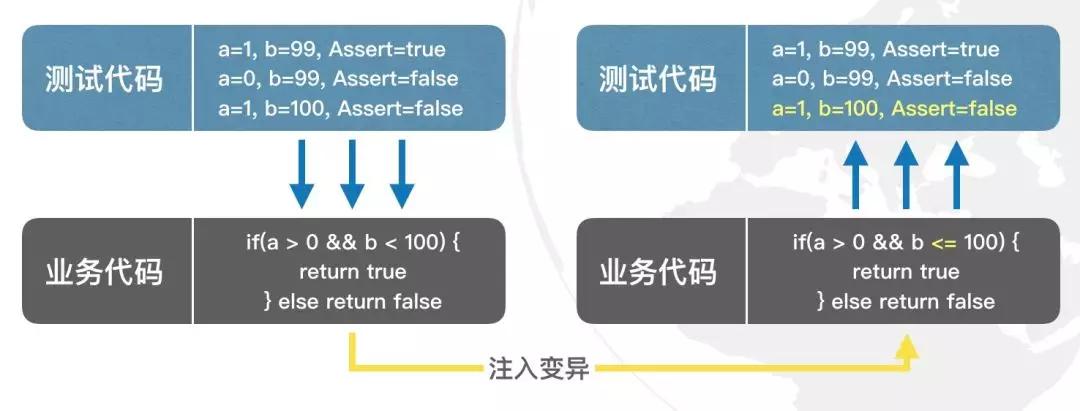
變異測試的例子
我們用了一組測試用例(3個),去測試一個判斷分支。而為了證明這一組測試用例的有效性,我們向業務代碼中注入變異。我們把b<100的條件改成了b<=100。 我們認為:
- 一組Success的測試用例,在其被測對象發生變化后(注入變異后),應該至少有一個失敗。
- 如果這組測試用例仍然全部Success,則這組測試用例的有效性不足。
通過變異測試的方式:讓注入變異后的業務代碼作為“測試用例”,來測試“測試代碼”。
我們實現了多種規則,可以主動的注入下面這些變異:
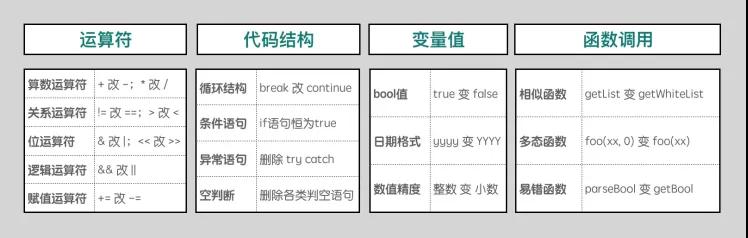
如何優雅的評估測試有效性?
為了全自動的進行測試有效性評估,我們做了一個變異機器人,其主要運作是:
- 往被測代碼中寫入一個BUG(即:變異);
- 執行測試;
- 把測試結果和無變異時的測試結果做比對,判斷是否有新的用例失敗;
- 重復1-3若干次,每次注入一個不同的Bug;
- 統計該系統的“測試有效性” 。
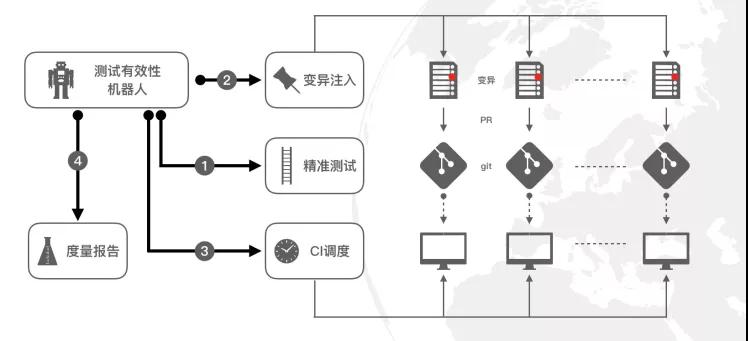
變異機器人的優點:
- 防錯上線:變異是單獨拉代碼分支,且該代碼分支永遠不會上線,不影響生產。
- 全自動:只需要給出系統代碼的git地址,即可進行評估,得到改進報告。
- 高效:數小時即可完成一個系統的測試有效性評估。
- 擴展性:該模式可以支持JAVA以及JAVA以外的多種語系。
- 適用性:該方法不僅適用于單元測試,還適用于其他自動化測試,例如接口測試、功能測試、集成測試。
變異機器人的使用門檻:
- 測試成功率:只會選擇通過率100%的測試用例,所對應的業務代碼做變異注入。
- 測試覆蓋率:只會注入被測試代碼覆蓋的業務代碼,測試覆蓋率越高,評估越準確。
高配版變異機器人
我們正在打造的高配版變異機器人擁有三大核心競爭力:
分鐘級的系統評估效率
為了保證評估的準確性,100個變異將會執行全量用例100遍,每次執行時間長是一大痛點。
高配版變異機器人給出的解法:
- 并行注入:基于代碼覆蓋率,識別UT之間的代碼覆蓋依賴關系,將獨立的變異合并到一次自動化測試中。
- 熱部署:基于字節碼做更新,減少變異和部署的過程。
- 精準測試:基于UT代碼覆蓋信息,只運行和本次變異相關的UT(該方法不僅適用于UT,還適用于其他自動化測試,例如接口測試、功能測試、集成測試)。
學習型注入經驗庫
為了避免“殺蟲劑”效應,注入規則需要不斷的完善。
高配版變異機器人給出的解法:故障學習,基于故障學習算法,不斷學習歷史的代碼BUG,并轉化為注入經驗。可學習型經驗庫目前覆蓋螞蟻金服的代碼庫,明年會覆蓋開源社區。
兼容不穩定環境
集成測試環境會存在一定的不穩定,難以判斷用例失敗是因為“發現了變異”還是“環境出了問題”,導致測試有效性評估存在誤差。
高配版變異機器人給出的解法:
- 高頻跑:同樣的變異跑10次,對多次結果進行統計分析,減少環境問題引起的偶發性問題。
- 環境問題自動定位:接入附屬的日志服務,它會基于用例日志/系統錯誤日志構建的異常場景,自動學習“因環境問題導致的用例失敗”,準確區分出用例是否發現變異。
落地效果如何?
我們在螞蟻金服的一個部門進行了實驗,得出了這樣的數據:
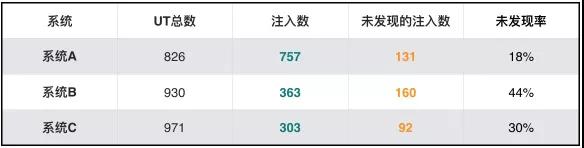
換言之,幾個系統的測試有效性為:系統A 72%,系統B 56%,系統C 70%。
測試有效性(%) = 1 - 未發現注入數 / 注入數
更多的測試有效性度量手段
基于代碼注入的測試有效性度量,只是其中的一種方法,我們日常會用到的方法有這么幾種:
- 代碼注入:向代碼注入變異,看測試用例是否能發現該問題
- 內存注入:修改API接口的返回內容,看測試用例是否能發現該問題
- 靜態掃描:掃描測試代碼里是否做了Assert等判斷,看Assert場景與被測代碼分支的關系
- ... 還有更多其他的度量手段
Meet the testcase again
測試有效性可以作為基石,驅動很多事情向好發展:
- 讓測試用例變得更能發現問題。
- 讓無效用例可被識別、清理。
- 創造一個讓技術人員真正思考如何寫好TestCase的質量文化。
- 測試左移與敏捷的前置條件。
- ......
寫到最后,想起了同事給我講的一個有趣的人生經歷:
“大二期間在一家出版社編輯部實習,工作內容就是校對文稿中的各種類型的錯誤。編輯部考核校對質量的辦法是,人為的事先在文稿中加入各種類型的錯誤,然后根據你的錯誤發現率來衡量,并計算實習工資。”
“你干得咋樣?”
“我學習了他們的規則,寫了個程序來查錯,拿到了第一個滿分”
“厲害了...”
“第二個月就不行了,他們不搞錯別字了,搞了一堆語法、語義、中心思想的錯誤... 我就專心干活兒了”
“...”
殊途同歸,其致一也。





















