













架構漫談:從架構的角度看如何寫好代碼
軟件架構實際上包括了:代碼架構,以及承載代碼運行的硬件部署架構。實際上,硬件部署架構最終還是由代碼的架構來決定。因為代碼架構不合理,是無法把一個運行單元分拆出多個來的,那么硬件架構能分拆的就非常的有限,整個系統(tǒng)最終很難長的更大。
所以我們經(jīng)常會聽說,重寫代碼,推翻原有架構,重新設計等等說法,來說明架構的進化。這實際上就是當初為了完成任務,沒有充分思考所帶來的后果。這也并不是架構進化的事情,而是個人對問題領域的逐漸深入理解的過程。所以有必要再討論一下,代碼的架構應該是怎樣的。
本文會在之前幾篇文章的基礎上,進一步探討如何把架構的思考進行落地,細化到我們代碼的實踐當中,盡量不要讓代碼成為系統(tǒng)長大的瓶頸,降低架構分拆的成本。
在前面我們提到,軟件實際上是對現(xiàn)實生活的模擬,虛擬化。這是一個非常重要的前提,直接決定了我們的代碼應該分為幾部分。結合每個部署單元所承擔的責任,可以明確的拆分為兩個不同的責任:
表達業(yè)務邏輯的代碼。很多人把這部分叫做Domain Logic,或者叫Domain Model。這部分實際是來源于生活的,必須保持和現(xiàn)實生活中的切分一致,并非人為的抽象而成。
對用戶提供訪問并保存業(yè)務邏輯運行結果的代碼。計算機的狀態(tài)保存有一個缺陷,本機保留業(yè)務運行結果有很大的問題,一般都在外存儲設備上保存,也便于擴展。
所以單個部署單元的代碼可以分為兩個部分,如下圖所示:
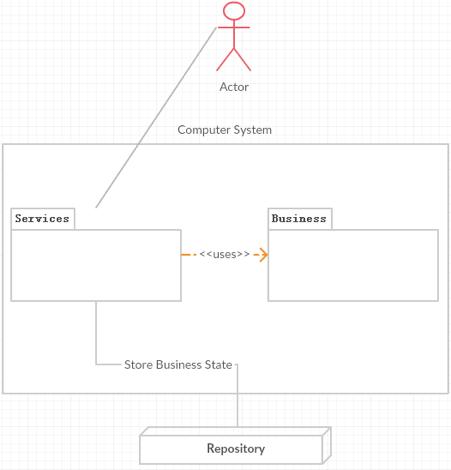
從這個圖中可以看出,軟件代碼的相關利益人為運行時的訪問人員和存儲設備。而service的代碼是最復雜的,需要服務于三方,代碼人員的負擔是最重的。為了把這三方的變化對service的影響降到最低,對于service還必須進一步的分拆為三個部分,讓每一個部分都能夠獨立的變化,這樣這三方的變化就不會產生連鎖響應,降低成本。如下圖所示:
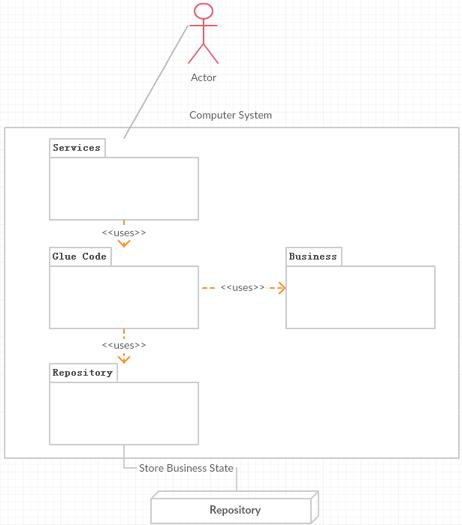
這樣,就劃分成了幾個責任:
Service就專注于user的需求,并組合Glue Code提供的服務完成需求。
Glue Code專注于組合business的調用,管理Business里面對象的生命周期,并且通過Repository保存或加載Business的狀態(tài)
Business專注于實現(xiàn)業(yè)務的核心模型。
Repository專注于數(shù)據(jù)的保存,并和存儲設備一一對應。
大家注意看,還是樹形架構。并且左側的主要需要計算機的相關理論知識,并且要直接面對用戶的需求。右側的更多的需要面對業(yè)務的核心。只要這幾塊的開發(fā)人員互相商量好了接口定義,這幾個部分的開發(fā)就可以并行的進行,極大的提升開發(fā)的效率,縮短開發(fā)的時間。要做好這幾部分,還需要注意,邏輯只允許存在于Business中,Service、Glue Code、Repository都不允許存在業(yè)務邏輯。為什么呢?首先我們來看看什么叫業(yè)務邏輯。
什么叫業(yè)務邏輯?
首先這個定義的前提是指軟件代碼中的邏輯,不是現(xiàn)實生活中的邏輯。在軟件代碼中,不需縮進和計算的順序調用,包括縮進的代碼目的是catch exception的,都不算邏輯,除此以外都是邏輯。以下用嚴格的順序調用來指代這種代碼。因為順序調用是計算機的特性,由編譯器來決定的,當然最本質的是因為我們計算的基礎都是圖靈機。在現(xiàn)實生活中,順序調用也是邏輯,大家不要和我們這里說的業(yè)務邏輯相混淆。
為什么說除了Business代碼中有邏輯以外,其他地方不能有邏輯呢? 我們每個部分分別分析:
如果service里面不是嚴格的順序調用,有很多分支,那么說明這個service做了兩件或者兩件以上的事情。必須把這個service分拆,確保每個service只做一件事情。因為如果不這么分拆的話,一旦這個service中的某各部分發(fā)生變動,其他的部分的執(zhí)行必定會受影響。而確定到底有哪些影響的溝通成本非常高,其他相關利益方?jīng)]有動力去配合,我們往往不會投入精力仔細評估。最后上線會出很多不可預料的問題,最終會導致?lián)p失用戶的利益,并且肯定會導致返工,損壞自己的利益。如果是有計算的邏輯的話,比如受益計算,訂單金額計算等,那么這部分應該是Business代碼需要完成的,不能交給service代碼來實現(xiàn)。
Glue Code里面如果不是嚴格的順序調用,同理會和service一樣遇到同樣的問題。
Repository里面如果不是嚴格的順序調用,包括存儲訪問的代碼里面(比如SQL),會導致邏輯進入到存儲設備中。存儲設備的主要目的是拿來存儲的,一旦變成了邏輯計算的主體,就會導致存儲設備無法通過增加機器的方式橫向擴展長大。這個時候就沒有架構了,只能換性能更好的機器,這個叫scale up。只有scale out才能算架構。
以上都會導致架構無法快速的橫向擴展和分拆,并且增加了修改的成本,這些是不符合開發(fā)人員以及業(yè)務的利益的。
這么做的好處有哪些呢?
Service、Glue Code、Repository里面的代碼是嚴格的順序調用,那么這些代碼只要做連通性測試即可,不需要單元測試。因為這些代碼都需要和很多上下文打交道,很難做單元測試。這樣才算是真正的組合。
Business不訪問任何上下文,不訪問任何具體的設備,所以這部分代碼是非常容易寫單元測試的,并且單元測試必須100%覆蓋。因為其他地方?jīng)]有業(yè)務邏輯,所以一旦有問題,就可以斷定是Model的問題,單元測試肯定可以發(fā)現(xiàn)。如果單元測試沒有發(fā)現(xiàn)問題,那么單元測試一定有問題。線上問題的模擬也就變得非常的簡單,單元測試也能夠得到進一步的補充。
Repository很容易按照存儲設備本身的最小訪問粒度來完成工作,比如DB,完全可以做到單表訪問。因為這個時候存儲設備只關心存取數(shù)據(jù),完全和業(yè)務沒有關系。做表的分拆也是非常容易的事情,存儲設備通過增加機器就可以橫向擴展長大。很多人會擔心說,沒有了join,訪問DB的次數(shù)是不是更多了,會導致性能下降? 按照現(xiàn)在網(wǎng)絡的條件,網(wǎng)絡訪問和Disk IO訪問的差距已經(jīng)不大了,合理的設計下,多訪問幾次DB并不會導致這個問題。另外如果多臺DB的話,還能通過并行加速訪問。
由于Service、Glue Code、Repository代碼簡單了,才可以讓我們的開發(fā)人員投入更多的時間研究業(yè)務,畢竟這部分才是軟件所真正服務的對象。
我們再來看一個實際的例子,如下圖所示:
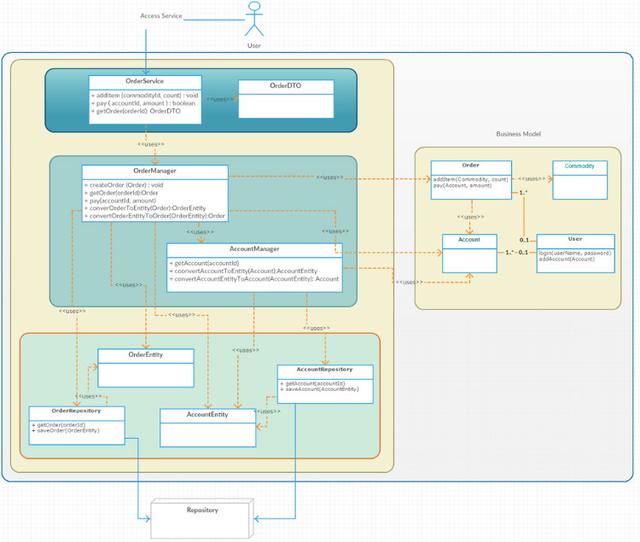
Manager類實際就是Glue Code。有幾個注意點需要說明一下:
不能把Business Model當做數(shù)據(jù)對象來處理,Model關心的實際上是業(yè)務行為,數(shù)據(jù)只是是這些行為的結果。所以Glue Code需要把Model轉換為Entity,Entity和存儲設備里面的存儲粒度一一對應。比如在DB中,每個Entity對應一張表,并且跟著表的變化而變化,這樣就保證存儲的變更不會影響Model。同樣Service和用戶之間的數(shù)據(jù)交互,也是不會和Model之間相關的,確保用戶的需求變化,不會影響到Model。因為用戶的需求變化是最頻繁的,沒有邏輯,可以讓我快速的滿足業(yè)務的需求。
在Service這里,最好不要考慮代碼重用。因為當多個不同的角色訪問同一個接口,一旦某個角色的需求發(fā)生了變化,就會要求開發(fā)人員去修改。而這個修改往往會影響到其他的角色,需要這些角色一起配合來確定是否受影響,但是這些角色因為沒有需求,往往不會配合。這樣就給開發(fā)人員造成了很多不必要的溝通,成本是非常高的。最終都會導致線上Bug,影響最終的用戶。所以盡量給不同的角色不同的Service,避免重用,降低溝通成本。很多人會說這樣Service不就太多了嗎? 這樣Service注冊,查找等管理需求就出現(xiàn)了,Service治理中心就是來解決這個問題的。因為Service里面沒有邏輯,所以開發(fā)和管理非常的簡單,可以快速應對業(yè)務的變化。我們只有更快地變,更容易的變,才能更好地應對變。
Business Model是必須要重用的,一旦發(fā)現(xiàn)重用出現(xiàn)問題,那么說明Business Model的識別出現(xiàn)了問題,這是一個我們要重新思考Model的信號。Business Model必須是一個完美的樹狀,如果不是,也說明Model的識別出了問題。
在實際操作中,Service、Glue Code、Repository不能有邏輯,實際上和很多人的觀念是沖突的,認為這個根本做不到。做到這一點需要很多的學習成本,但是一定可以做得到。當發(fā)現(xiàn)做不到的時候,可以斷定是業(yè)務的分析出了問題。比如不該合并的合并了,不該計算的計算了。這個問題一定有辦法解決的,做不到都是理由,無非是想早點把自己的工作結束罷了。雖然剛開始會比較困難,一旦把這個觀念變成自覺,開發(fā)的質量和效率馬上就能高好幾個級別。
我的游泳教練曾和我說過這些話,我至今記憶猶新:“業(yè)余選手,越想從水里浮起來,就越想把頭抬起來,身體反而沉下去。只有克服恐懼,把頭往水里壓下去,身體才能夠從水里浮起來。真正專業(yè)的習慣往往是和我們日常的行為相反的”。
我們真正想快速的完成代碼工作,就要克服自己對時間的恐懼,真正的去研究業(yè)務的問題,相關stakeholder的利益,把這個變成我們的習慣。寫代碼的時候讓該出現(xiàn)邏輯的地方出現(xiàn)邏輯,讓不該出現(xiàn)的地方不能出現(xiàn)。一旦不該出現(xiàn)的地方出現(xiàn)了邏輯,那么要馬上意識到,這個地方是一個坑,這個問題一定和業(yè)務的分析不透徹有關系。
很多人可能會把這個做法和Martin Fowler曾經(jīng)提出過充血模型和貧血模型來比較,和Domain Driven Design來比較,其實沒有必要。這個分拆完全是從軟件所解決的問題,根據(jù)軟件架構推導出來的,很多地方和兩位前輩的觀點是一致的,但是并不完全等同。
以上只是針對單一的Service部署單元的分析,擴展開去,對于其他的部署單元也是類似的。每個單元的下一級都可以認為是Repository,每個單元的上一級都可以認為是User。這些實踐在我自己的項目中都有用到,非常的有效,迭代的速度非常的快。很多人擔心Business Model建不好,其實沒關系,剛開始可以粗糙一點,后續(xù)可以慢慢的完善。這個架構已經(jīng)隔離好了每個部分的變化對其他部分的影響,變化成本都在可控的范圍之內。

















