













快手聯手英偉達部署業界最先進GPU計算基礎架構
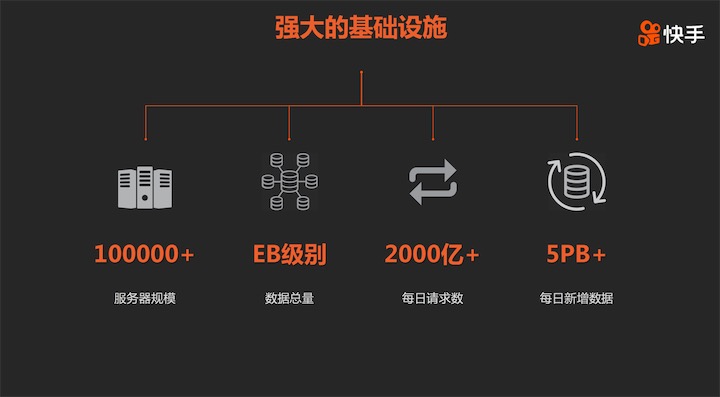
日活超過2億的快手,庫存短視頻超過130億條,仍以每日超過1500萬條短視頻上傳的速度新增,擁有海量超大數據應用場景。快手基礎設施的規模已經處于國內互聯網公司頭部行列。目前快手服務器規模已經超過十萬臺,數據總量達到EB級別,每天新增數據超過5PB。
為保障千億級別數據量的處理和基礎設施穩定、高效運行,快手服務器選型和業務優化團隊(以下簡稱“快手SAT團隊”)選用合作伙伴英偉達新一代圖靈架構的TESLA T4/V100,在業內率先完成計算架構的全新升級。
據了解,快手SAT團隊的成員經驗豐富,人均工作經驗在10年左右,專注于硬件方面的成員大多來自于海內外大型服務器或者硬件廠商,專注于軟件方面的成員大多數來自國內頭部互聯網企業。正是這樣的一個軟硬結合的團隊,給快手超過2億 的日活量級提供了堅實的保障。
據快手SAT團隊研發人員介紹,快手大數據應用場景如視頻推薦平臺、音視頻理解、風控、商業化廣告、強化學習等都是公司的核心業務,多個業務場景數據處理需求量大,英偉達推出新的特斯拉架構產品之后,SAT團隊將TESLA T4/V100 GPU的引入列為首要任務,使用新一代的GPU,搭配現有的計算平臺(CPU、FPGA等),將TESLA T4引入到新的套餐上,同時以最快速度適配給公司內的核心業務,保障硬件基礎架構走在業界前列。
GPU架構優化性能提升2倍成本節省30%
針對快手快速增長的業務需求,既需要盡可能的滿足業務靈活多變的需求,又不能使得套餐數量過于發散,同時要兼顧成本優化目標,所面臨的問題十分復雜。為平衡需求和復雜性,快手SAT團隊最終決定引入了2個GPU套餐,搭配虛擬化容器,滿足不同業務場景下的不同需求。
GPU服務器特別是多卡GPU服務器在實際計算中,普遍會面臨CPU性能成為瓶頸的問題。為了解決CPU性能瓶頸、GPU利用率不高的問題,快手SAT團隊聯合算法團隊,通過在Resnet50/SSD上將Resize、Augment等從CPU端遷移至GPU端的方法,將CPU的loading逐步遷移到GPU上,進一步利用了GPU強大的計算能力,解放了CPU,達到了CPU和GPU之間的均衡計算效果。
GPU之間的性能均衡是另一個問題。部分業務場景的模型體積非常巨大,單GPU顯存往往沒有辦法存下整個模型,這時候通常會將模型存在內存中,由CPU來進行相對應的運算操作,快手SAT團隊通過優化CPU親和性,避免了負載不均和查找路徑較遠的問題。
快手的訓練模型要求精度較高,之前普遍使用FP32,模型較大,目前正在慢慢使用混合精度來替代原來方案,性能得到明顯提升。 在實際使用中,快手SAT團隊也發現AMP(自動混合精度)雖然使用起來簡單,但并不能適配所有業務。所以需要快手SAT團隊和業務團隊一起嘗試不同方法,結合FP32、AMP以及手動混合精度等手段為業務方的訓練提供計算性能。
推理模型相對于訓練模型,普遍存在batchsize較小的問題,需要對內存進行頻繁的讀寫訪問,同時推理相較于訓練,要求的精度沒有那么高。為解決這些問題,同時為更好的利用新架構中的Tensor Core的性能,快手SAT團隊引入了TensorRT,幫助業務快速使用在GPU上,使得運行速度大大提升,編譯后的代碼所占內存的大小大大縮減。
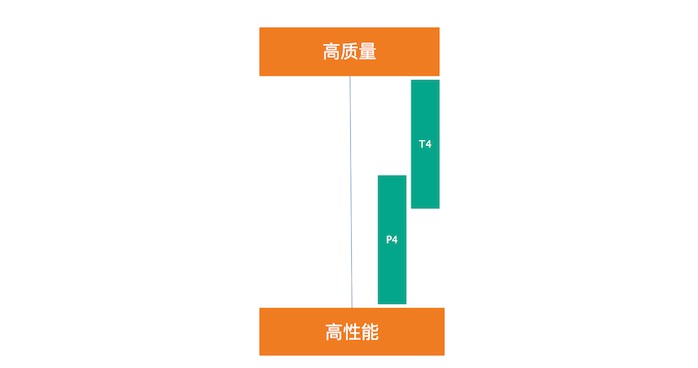
解碼H264:T4 / P4 = 2.6 倍左右; 解碼Hevc:T4/P4 = 4倍左右。在Hevc下的高性能,得益于T4的2個nvdec引擎,解碼Hevc時比H264投入的計算單元更多
T4的Fast Preset 與 P4的Slow preset在質量和并發數量上大致相當
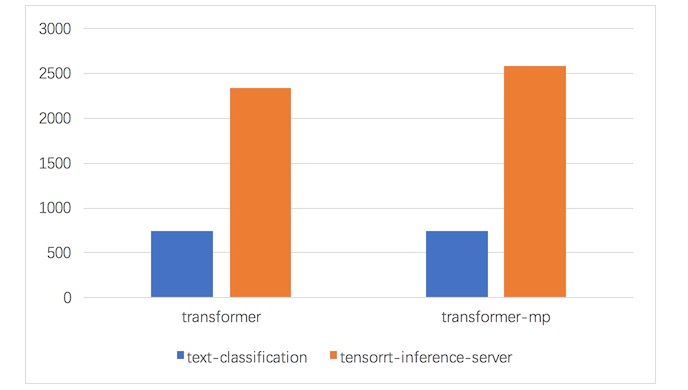
使用TensorRT-Inference-Server,對比text-classification,性能提升2倍左右
從以上對比圖中可以看出,通過現階段GPU計算架構的優化,業務的性能平均增長了2倍,成本較之前節省了30%以上。
軟硬結合,優化落地
為了讓新產品的特性更好的助力快手的業務,快手SAT團隊提供了一整套的流程方案。了解業務使用需求后,通過分析目前的瓶頸點和高頻使用資源,合理選擇硬件產品,將這些產品快速集成在套餐之中。新硬件往往伴隨著一些新的框架和指令集的支持,例如TESLA T4對于FP16的支持,使得T4的性能大幅提升。參考這些新特性,業務部門將代碼優化后部署上線。通過Vtune/Nsight等工具對代碼進行分析,優化低效的部分,最終呈現效果后上線灰度,追求高效迅捷,使得快手一直走在技術的前沿。
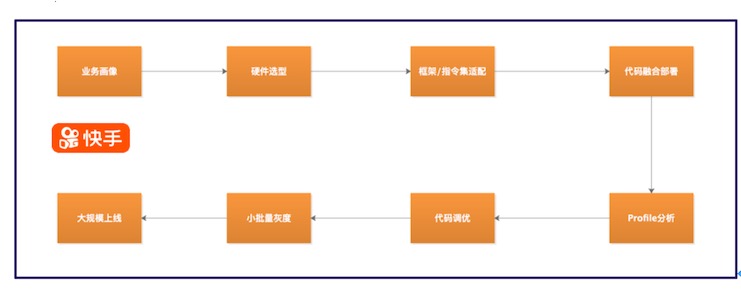
(圖示:快手選型上線流程)
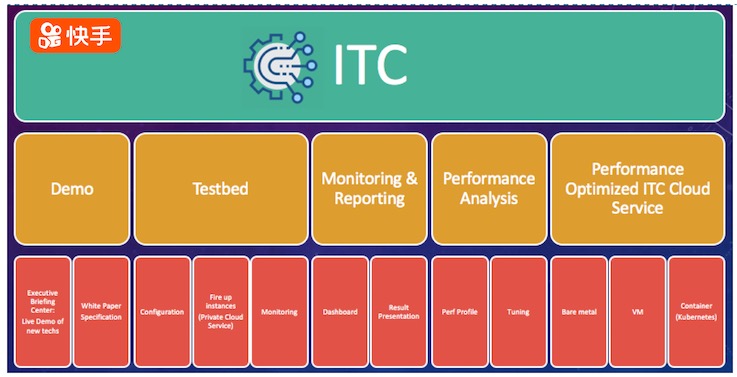
(圖示:快手新硬件/新技術引入平臺模塊)
自定義監控,防范故障于未然
如果說使用是第一步的話,那么運維就是第二步。快手SAT團隊針對GPU的監控,一共做了三件事,一是自主開發的GPU使用率監控,二是自定義的GPU故障監控,三是GPU的故障預判。
監控GPU的使用率,可以使得業務更加了解自己的負載情況,也可以驗證前面選型配置的合理性。通常來說業內大多使用smi中的GPU-Util參數來判斷GPU的使用情況,但快手在實際使用中發現,判斷GPU的使用率是一個較為復雜的問題,GPU-Util反應的只是單位時間內GPU的整體使用情況,并不能清晰地反應GPU的負載情況。針對這種情況,快手SAT團隊手動開發了一套使用率監控腳本,從SM單元、編解碼單元采樣值、帶寬負載、讀寫時間比等多個維度進行分析,最終得出GPU的綜合使用率。
故障的監控,是一個比較老生常談的問題,在任何硬件產品上都會遇到,GPU因為其較高的功耗和溫度,以及業務對其的強依賴性,最初快手SAT團隊設置了非常多的監控指標,這些監控指標都是通過GPU設備的API提煉抽取出來的,但是隨著監控實例的增加,告警的數量也隨之大幅提高。這些告警里包括持續告警、波動告警、關聯告警,當然這些告警的出現,使得快手發現了問題,但是也給快手的運維人員造成了極大的困擾。為了解決告警泛濫的問題,快手SAT團隊對監控參數進行分析整合,針對不同業務使用GPU時的不同需求,制定業務生死標準:影響業務生存的標準優先報,在單位時間內發生的告警只報一個。
故障的預判,是為了避免有可能發生的故障對業務帶來損失,這個預判的準確性是關鍵。故障的預判在很多情況下都是一個導火索,是一個隨著時間的推移慢慢變成現象級的過程。快手SAT團隊在故障的預判方面針對GPU設定了十余個監控參數,通過對這些積累下來的數據進行訓練,得到一個閾值,再使用這個閾值進行故障預判。通過這個訓練預測不斷循環的過程,使得故障的預判越來越精準。
后續規劃
隨著快手日活量不斷增加,用戶數據不斷豐富,模型的數量越來越多,越來越復雜,在空間的占用上呈幾何級數增長。目前快手SAT團隊正在做幾件事:引入大容量低成本NVM與GPU組成異構計算+異構存儲服務器;搭配100G/200G/400G RDMA,做CPU offload的架構,提高分布式計算的效率;將存儲資源和計算資源解耦分離。
快手選型上線流程和英偉達企業級技術支持團隊已經有了一年多的合作經驗,以TESLA GPU引入為契機,快手SAT團隊整理規范了GPU服務器引入和應用優化一整套的科學體系,并在實踐中獲得了較好的業務收益,為公司節省了大量的時間成本,同時計算力更加出色的GPU計算架構也為未來快手關鍵業務線上線更加復雜的模型打下了堅實的基礎。快手系統運營部硬件研發團隊誠聘新技術硬件研發工程師,歡迎每一個對技術有追求的技術人。
























