













多云架構落地設計和實施方案
“不要把雞蛋放在同一個籃子里”是一條知名的商業準則,在云平臺選擇上,很多公司也遵循這樣的準則。基于多云平臺構筑“業務中臺”并不是一件簡單的事情,需要構建一種快速繼承、可持續迭代的路徑,幫助整體方案落地。本文以實際項目案例為例,分析項目的架構設計、實施步驟,以及多云架構面臨的挑戰和機遇。
總體思路
不同云廠商提供的云服務不盡相同,相同的云服務在功能、性能上也會有或多或少的差異。越是深度使用某個云廠商的云服務,越是難于遷移到其他云廠商。選擇自己構建云服務,則技術門檻,維護成本很高。確定多云架構以后,首先需要在技術棧的選型上做好折中。一個基本的原則是通過業務架構的靈活性,去適配不同的云廠商,盡可能的使用云廠商提供的優秀特性,提升運行于該云平臺的業務系統的可靠性,提升整體業務的競爭力。
上面的思路和一些客戶常見的思路有顯著差別。有些客戶選擇采用開源軟件,搭建自己的 PaaS 平臺;有些客戶則完全采用云廠商的技術棧,開發兩套業務系統。這兩種方式是兩個極端,前者開發和運維難度高,往往由于技術風險評估不足,項目無法如期交付,或者產品競爭力太弱,沒有云廠商提供的服務好。后者則需要維護兩套系統,代碼重復度高,還會被云廠商完全綁定,失去談判的籌碼,業務發展靈活性降低。還有些客戶期望云廠商提供足夠兼容性的框架支持,在不改造現有業務系統的邏輯的情況下實現多云部署,云廠商這方面的努力通常由于客戶系統的復雜性和多樣性得不到落地。
開發框架選擇和架構設計
開發框架設計是多云架構的核心,也是抽象程度最高的部分。華為云主推 ServiceComb 作為微服務框架,阿里云主推 HSF、Dubbo 作為微服務框架,其他國外的云廠商,多數選擇 Spring Cloud 作為微服務框架,另外還有其他不同的語言和框架選擇。雖然 mesher 等技術為多語言協同工作提供了良好的支持,但是為了最大限度的利用框架特性,幫助快速構建穩定可靠的業務系統,選擇一個微服務開發框架仍然是必不可少的。
基于總體思路,多云架構期望在華為云上使用 ServiceComb 運行時,在阿里云上使用 HSF 運行時,并且支持 Spring Cloud 運行時。完成這個目標,首先需要對微服務運行框架的運行時和主要組成部分有所了解。對于多數中臺系統,對于框架運行時的依賴,一般都是 RPC 框架,以及基于 RPC 框架做的服務治理能力,包括服務注冊發現、熔斷容錯、限流等機制。將業務邏輯核心代碼,與微服務框架能力進行解耦,是設計的第一步。
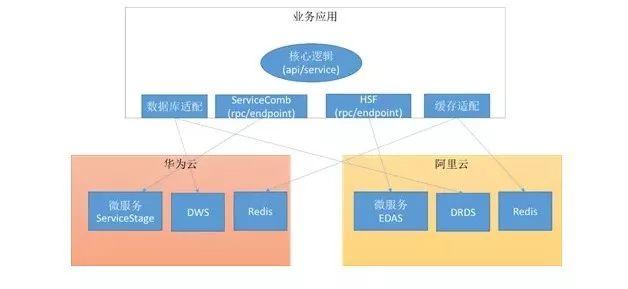
上面的圖形展現了基本的邏輯架構。
業務核心:技術選型上使用 Spring、Spring Boot。ServiceComb、HSF 和 Spring Cloud 等微服務框架的技術底座,都可以基于 Spring、 Spring Boot 技術棧來構建。
在邏輯架構下,需要將微服務代碼進行分層,包含下面三個主要目錄:
- microservice-api:定義微服務的接口。該目錄包含接口定義(interface)、數據結構定義(models)。為了支持不同的微服務框架,對于接口定義和數據結構定義會有一定的要求。
- microservice-service:業務邏輯實現代碼。
- microservice-endpoint-servicecomb:發布為 ServiceComb 的微服務項目。
- microservice-endpoint-hsf:發布為 HSF 的微服務項目。
- microservice-endpoint-springcloud:發布為 Spring Cloud 的微服務項目。
這個代碼分層實施的核心關鍵是 api 設計,以及業務邏輯實現和服務發布解耦。api 設計需要滿足不同的微服務框架的設計要求。這里涉及到 RPC 編解碼的基礎。RPC 編解碼通常分為語言無關(跨平臺)和語言相關(不跨平臺)。比如 HSF、Dubbo 的缺省編解碼是語言有關的,只能夠支持 JAVA 程序之間的通信,ServiceComb 缺省采用 Jackson 編解碼,或者 protobuffer 編解碼,這兩種方式都基于 Open API 2.0 進行定義,可以做到語言無關,Spring Cloud 則相對復雜一些,它是一種混合型的編碼格式,可以通過靈活的序列化定制,滿足多樣性需要,也可以嚴格遵循 Jackson 和 Open API 標準。通常語言無關的編解碼可以完全包含語言無關的編解碼要求,因此 api 定義的時候,需要做到語言無關,才能夠保證 api 能夠在不同的微服務開發框架下得到最好的實現。基于本文是描述工程實踐,不詳細探討關于跨平臺設計的原理,下面列出一些接口設計的準則:
- 使用簡單的類型(比如 Integer, String, Boolean 等)定義參數或者返回值。或者使用包含簡單類型的,符合 Java Bean 規范的 POJO Bean 定義參數或者返回值。
- 盡可能不使用 interface, abstract class, 存在多個實現的基類,模板類作為參數或者返回值。
- 不使用運行環境強相關的對象作為接口參數或者返回值。比如 HttpServletRequest,RpcContext,InvocationContext,ResonseEntity 等。
上面的原則從使用者的視角來看,是非常容易理解的。接口語義清晰,沒有歧義,直接通過接口定義就能夠理解接口的參數個數以及如何傳遞,不需要提供額外的文檔或者查看源代碼。有利于通過接口定義生成文檔、swagger 定義。
在實際項目中,開發者需要理解 microservice-api 是微服務之間的接口定義,接口設計需要考慮數據的序列化和反序列化。這個不同于內部接口設計。為了降低業務實現邏輯的重復度,增強內聚性,內部接口設計會更多的使用抽象、繼承進行邏輯封裝。內部接口的數據結構,還會包含一些額外的控制邏輯。比如數據庫訪問層的數據結構,提供懶加載等機制,當訪問到 getter 方法的時候,實際上調用的是代理對象的 getter 方法。因此,需要有一些數據結構轉換邏輯,將內部的數據結構轉換為外部接口的數據結構,以保持服務之間接口和內部接口的界限清晰,防止將內部數據結構作為參數或者返回值,導致內部信息泄露,造成不可預期的處理結果。
api 示例
- interface LoginService {
- SessionInfo login(String username, String password);
- }
- public class SessionInfo {
- private String sessionId;
- private String username;
- }
service 示例
- @Service
- @Primary
- public class LoginServiceImpl implements LoginService {
- public SessionInfo login(String username, String password) {
- // do login
- }
- }
ServiceComb Endpoint 示例
服務端:
- @RpcSchema(schemaId = “LoginServiceEndpoint”)
- public class LoginServiceEndpoint implements LoginService {
- @Autowired
- private LoginService service;
- public SessionInfo login(String username, String password) {
- return service.login(username, password);
- }
- }
客戶端:
- @Bean
- public LoginService getLoginService() {
- return Invoker.createProxy(SERVICE_NAME, "LoginServiceEndpoint", LoginService.class);
- }
或者
- @RpcReference(microserviceName=SERVICE_NAME, schemaId=”LoginServiceEndpoint”)
- private LoginService loginService;
HSF Endpoint 示例
服務端:
- @HSFProvider(serviceInterface = LoginService.class,serviceVersion = "1.0.0")
- public class LoginServiceEndpoint implements LoginService {
- @Autowired
- private LoginService service;
- public SessionInfo login(String username, String password) {
- return service.login(username, password);
- }
- }
客戶端:
- @HSFConsumer
- private LoginService loginService;
從上面的代碼示例看,Endpoint 層需要做到盡可能邏輯簡單,實現邏輯全部交給 Service 層,只包含接口聲明,或者包含必要的數據結構轉換邏輯。上面的方式演示了 RPC 的接口聲明,還可以加上 REST 標簽(Spring MVC,或者 JAX RS),來支持 REST 接口。
遺留系統的改造策略
大部分公司都會存在現有系統運行于某一個云上,把現有系統推倒重來,進行全新設計,通常不是一個好主意。遺留系統的改造需要遵循持續迭代,繼承性改造的思路。
以阿里云系統改造為華為云系統為例,將原來基于 HSF 開發的微服務應用改造為基于 ServcieComb 開發的微服務應用。
按照前面的總體思路,首先需要將原來項目強依賴于 HSF 的代碼部分分離出來,建立下面的目錄結構:
- microservice-api:定義微服務的接口。該目錄包含接口定義(interface)、數據結構定義(models)。為了支持不同的微服務框架,對于接口定義和數據結構定義會有一定的要求。
- microservice-service:業務邏輯實現代碼。
- microservice-endpoint-hsf:發布為 HSF 的微服務項目。
這個過程相對而言是簡單的,不涉及任何業務邏輯的調整,只是代碼目錄結構的變化和 POM 依賴關系的調整。調整完成后,可以對現有功能進行簡單自動化驗證,保證項目自動化測試用例能夠通過。調整后的項目功能和遺留系統是一致的,擁有一個始終無損的運行系統,對于功能比較、問題發現都是非常有幫助的。
項目調整后,就可以增加華為云的項目:
- microservice-endpoint-servicecomb:發布為 ServiceComb 的微服務項目。
這個項目可以復制 microservice-endpoint-hsf,將 POM 依賴改為 ServiceComb 的內容,并將發布的接口(Endpoint)調整為 ServiceComb 的發布方式。
項目調整后,就可以一份代碼構建出兩個可執行 jar 包,兩個 jar 包分別在華為云和阿里云部署。
這個過程的工作量需要通過原來代碼本身的復雜度、api 接口的規范性、代碼規模等進行評估。如果原來代碼結構復雜,api 定義不規范,工作量會顯著增加。對于良好組織的代碼,這個過程則會非常容易。實際改造的一些項目,有些一天時間即可完成,有些則花費了一、兩個月時間。獲取到產品的業務結構、代碼規模和通過簡單的識別現有代碼的技術棧和開發方式,能夠幫助有效的評估工作量。
遺留系統改造的核心工作在于 microservice-api 中接口定義的梳理。由于 HSF 不是一個跨語言的開發框架,因此在接口定義里面使用的數據結構 ServiceComb 可能存在不支持的情況。采用一個支持跨語言的框架的接口定義作為基準(一般的,可以將接口定義通過 IDL、WSDL 或者 Open API 描述的接口定義,比如 gRPC、WebService、ServiceComb,),其他框架都實現這個接口,是微服務架構適配的核心關鍵。
數據庫適配
業務系統都會使用數據庫。各個云廠商支持的數據庫形式多樣,有 MySQL、Postgre、Oracle 等,此外還有分布式數據庫,以及分庫分表等特性,數據倉庫支持等。雖然在連接池管理、事務管理、ORM 框架等方面有大量的開源開發框架,比如 dbcp、spring transaction、MyBatis 等,它們仍然沒法覆蓋所有的應用場景。適配多云架構對于業務代碼開發有如下建議:
盡可能使用符合 ANSI SQL Standard 的 SQL 語句。比如 MySQL 在大小寫、Column 引用、Limit、Group by 語句等方面都有自己的特殊用法。為了更好的適配多云數據庫,應該避免使用特殊用法,除非對于業務價值具備明顯的價值,而且沒有對等的解決方案。
選用一個被廣泛采用的 ORM 框架。比如 MyBatis、JPA 等。這些框架被廣泛支持,對于多數據庫支持得到比較充分的驗證。在使用數據庫有差異的地方,提供了非常良好的擴展機制。比如使用 MyBatis,可以使用 DatabaseProvider 接口,來屏蔽語法差異。在使用 JDBC 或者 JDBCTempate 拼接 URL 的地方,則可以通過接口的不同實現,返回不同的 SQL 語句。
- <if test="_databaseId == 'mysql' ">
- limit #{stratRow},#{rowCount}
- </if>
- <if test="_databaseId == 'postgresql' ">
- limit #{rowCount} offset #{stratRow}
- </if>
分布式數據庫、分庫分表、分析型數據庫對于業務開發存在不同的限制。比如對于唯一索引使用的限制、對于分庫分表鍵的修改限制等。對于這些場景,盡可能符合這些限制,調整業務實現方式,避免為了滿足某個不重要的場景需要,陷入一些分布式場景無法解決的問題當中去,而無法適配其他云廠商的數據庫。
緩存適配
各個廠商均支持 Redis 作為緩存,但是在 Redis 發展路徑上,有不同的分支。一個分支是 Proxy 集群模式,一個分支是 Redis 的原生集群方式。Redis 提供的客戶端 API 也存在兩套,一個是 Jedis,一個是 JedisCluster,兩套支持的命令集合不盡相同。比如 Proxy 集群模式能夠非常好的支持所有的 Jedis 命令,而 Redis 的原生集群方式只支持 JedisCluster 命令。很多客戶常用的 pipeline 指令,在 Redis 原生集群方式下不支持。
Proxy 集群能夠更好的屏蔽底層服務的差異,在沒有特殊需要的情況下,建議用戶使用 Proxy 集群模式,云廠商需要通過 Proxy 集群模式提供對于 Jedis 不同指令的支持。用戶也可以選擇 Redis 的原生集群,這個在不同的云產生也都提供了支持,用戶可以在業務場景上避免使用原生集群不支持的命令,這樣就可以在多云環境上部署。
總結起來,緩存的多云支持的最佳實踐:及時升級 Client API 版本,使用比較新的 Client API,并且只使用 JedisCluster 提供的指令集合。
消息中間件適配
相對于數據庫和緩存,消息中間件的適配的標準性更弱一點。雖然早期 JAVA 提出了 JMS 等標準,但是目前主流的消息中間件都沒有提供 JMS 接口的實現。阿里的 RocketMQ、華為基于 Kafka 的 DMS 的接口均不一致。而且消息中間件的服務質量并不一樣,比如在消息有序投遞、重復投遞等方面是通過消息中間件配置提供的,而不受客戶端接口控制。有些客戶的業務邏輯依賴于特定消息中間件的機制,因此需要對消息中間件使用的接口、接口行為進行抽象,分析其他云廠商的中間件能否提供對應的接口實現并滿足對應的服務質量要求,有時候需要業務代碼做一些補償,以彌補不同中間件服務質量的差異。
其他中間件適配
其他中間件包括日志服務器、定時任務服務、對象存儲服務等等。適配的總體思路一致,這里不詳細描述里面的細節。
多云架構的挑戰和建議
和做協議標準一樣,多云架構除了給客戶帶來商業上的靈活性,還會促進業務系統軟件架構的改善,提升整體的軟件質量。因為多云架構需要對使用的技術點進行權衡,技術選型上更多采用相對中立和標準的方案,這些方案被廣泛驗證,相對于使用一些私有特性來說,更加穩定,同時可以促進項目開發人員之間的技術交流和能力繼承。在給客戶做多云架構落地的實踐中,通過架構交流,幫助客戶梳理了整體的架構演進方向,還發現了很多歷史問題,對于客戶的代碼質量提升起到了很大作用。
多云架構也面臨特別多的挑戰。首先是短期內企業維護成本的增加和技術成本的增加,需要投入專家解決前期的架構適配問題,為系統持續演進搭好框架。多云系統運行,還會增加業務數據同步,不同云上系統如何進行協同的問題。只有當客戶多云系統相對獨立,沒有數據共享和業務交互的場景才比較簡單。多云系統還會影響到客戶的交付效率,不同云的持續交付方式存在較大的差異,運維人員的體驗不同,會降低日常的效率。
因此,多云架構更多的是準備“備胎”,客戶的主要業務還是以單一云廠商提供。多云架構給客戶對比不同云廠商的服務質量提供了非常準確的參考,客戶能夠更加準確的選擇優質的供應商。
微服務框架層的抽象是做多云架構最難抽象的部分,也是多數開發者最難把握的一層。ServiceComb 微服務開發框架作為參考接口規范,可以非常好的適配到 HSF、Spring Cloud 等框架。在接口定義的時候,可以采用它作為基線,先測試 ServiceComb,再測試 HSF 和 Spring Cloud 等適配,對于新接口開發、歷史系統遷移都是一個非常好的中間產品。














