對于管理員或用戶而言,命令行不僅是可以完成所有任務(wù)的工具,而且還是可以永遠開發(fā)的高度定制的工具。
最近,有一篇有關(guān)CLI中一些有用技巧的翻譯文章。但是我覺得翻譯人員沒有足夠的CLI經(jīng)驗,也沒有遵循所描述的技巧,因此許多重要的事情可能會被遺漏或誤解。
根據(jù)個人經(jīng)驗,在Linux Shell中有12種技巧。
注意:本文中的所有腳本和示例都經(jīng)過了盡可能地簡化,因此也許您會發(fā)現(xiàn)一些看起來完全沒用的技巧–也許就是這個原因。但無論如何,請在評論中分享您的想法!
1.使用可變擴展名分割字符串
人們經(jīng)常使用cut甚至awk只是通過模式或使用分隔符減去字符串的一部分。
另外,許多人使用$ {VARIABLE:start_position:length}進行子字符串bash操作,這非常快。
但是bash提供了一種使用#,##,%和%%來處理文本字符串的強大方法-它稱為bash變量擴展。
使用此語法,您可以在無需執(zhí)行外部命令的情況下減少模式的需要,因此它將非常快速地工作。
下面的示例顯示了如何使用cut或變量擴展從字符串中獲取第三列(shell),其中用冒號«username:homedir:shell»分隔的值(我們使用*: mask和##命令,這意味著:將所有字符向左剪切,直到找到最后一個冒號為止):
- $ STRING="username:homedir:shell"
- $ echo "$STRING"|cut -d ":" -f 3
- shell
- $ echo "${STRING##*:}"
- shell
第二個選項不啟動子進程(cut),并且根本不使用管道,這樣可以更快地工作。而且,如果您在管道幾乎不移動的Windows上使用bash子系統(tǒng),則速度差異會很大。
讓我們看一下Ubuntu上的示例:循環(huán)執(zhí)行我們的命令1000次
- $ cat test.sh
- #!/usr/bin/env bash
- STRING="Name:Date:Shell"
- echo "using cut"
- time for A in {1..1000}
- do
- cut -d ":" -f 3 > /dev/null <<<"$STRING"
- done
- echo "using ##"
- time for A in {1..1000}
- do
- echo "${STRING##*:}" > /dev/null
- done
結(jié)果
- $ ./test.sh
- using cut
- real 0m0.950s
- user 0m0.012s
- sys 0m0.232s
- using ##
- real 0m0.011s
- user 0m0.008s
- sys 0m0.004s
差別是幾十倍!
當(dāng)然,上面的例子太人為了。在實際示例中,我們將不使用靜態(tài)字符串,而是要讀取真實文件。對于“ cut ”命令,我們只將/etc /passwd重定向到它。在##的情況下,我們必須創(chuàng)建一個循環(huán)并使用內(nèi)部的' read '命令讀取文件。那么誰將贏得這場案子呢?
- $ cat test.sh
- #!/usr/bin/env bash
- echo "using cut"
- time for count in {1..1000}
- do
- cut -d ":" -f 7 </etc/passwd > /dev/null
- done
- echo "using ##"
- time for count in {1..1000}
- do
- while read
- do
- echo "${REPLY##*:}" > /dev/null
- done </etc/passwd
- done
結(jié)果
還有兩個示例:
在等號后提取值:
- $ VAR="myClassName = helloClass"
- $ echo ${VAR##*= }
- helloClass
提取括號中的文本:
- $ VAR="Hello my friend (enemy)"
- $ TEMP="${VAR##*\(}"
- $ echo "${TEMP%\)}"
- enemy
2. Bash自動補全
bash-completion軟件包幾乎是每個Linux發(fā)行版的一部分。您可以在/etc/bash.bashrc或/etc/profile.d/bash_completion.sh中啟用它,但是通常默認(rèn)情況下已啟用它。通常,自動完成是新手首先遇到的Linux Shell上的第一個便捷時刻。
但是并非所有人都使用所有bash補全功能這一事實,在我看來完全是徒勞的。例如,不是所有人都知道,自動完成功能不僅適用于文件名,而且適用于別名,變量名,函數(shù)名,甚至適用于某些帶有參數(shù)的命令。如果您深入研究自動完成腳本(實際上是shell腳本),甚至可以為自己的應(yīng)用程序或腳本添加自動完成。
但是,讓我們回到別名。
您無需編輯PATH變量或在指定目錄中創(chuàng)建文件即可運行別名。您只需要將它們添加到配置文件或啟動腳本中,然后在任何位置執(zhí)行它們即可。
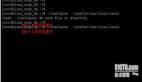
通常,我們在* nix中使用小寫字母表示文件和目錄,因此創(chuàng)建大寫別名非常方便-在這種情況下,bash-completion 幾乎會用單個字母來猜測您的命令:
- $ alias TAsteriskLog="tail -f /var/log/asteriks.log"
- $ alias TMailLog="tail -f /var/log/mail.log"
- $ TA[tab]steriksLog
- $ TM[tab]ailLog
3.使用選項卡進行Bash自動補全-第2部分
對于更復(fù)雜的情況,可能您想將個人腳本放入$ HOME / bin。
但是我們在bash中有功能。
函數(shù)不需要路徑或單獨的文件。(注意)bash補全也可以與函數(shù)一起使用。
讓我們在.profile中創(chuàng)建函數(shù)LastLogin (不要忘記重新加載.profile):
- function LastLogin {
- STRING=$(last | head -n 1 | tr -s " " " ")
- USER=$(echo "$STRING"|cut -d " " -f 1)
- IP=$(echo "$STRING"|cut -d " " -f 3)
- SHELL=$( grep "$USER" /etc/passwd | cut -d ":" -f 7)
- echo "User: $USER, IP: $IP, SHELL=$SHELL"
- }
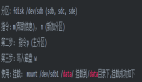
在控制臺中(請注意,函數(shù)名的首字母大寫以加快bash的完成速度):
- $ L[tab]astLogin
- User: saboteur, IP: 10.0.2.2, SHELL=/bin/bash
4.1.敏感數(shù)據(jù)
如果您在控制臺中的任何命令前放置空格,則它將不會出現(xiàn)在命令歷史記錄中,因此,如果您需要在命令中放置純文本密碼,這是使用此功能的一種好方法—在下面的示例中回顯«hello 2»將不會出現(xiàn)在歷史記錄中:
- $ echo "hello"
- hello
- $ history 2
- 2011 echo "hello"
- 2012 history 2
- $ echo "my password secretmegakey" # there are two spaces before 'echo'
- my password secretmegakey
- $ history 2
- 2011 echo "hello"
- 2012 history 2
它是可選的
4.2.命令行參數(shù)中的敏感數(shù)據(jù)
您想在git中存儲一些shell腳本以在服務(wù)器之間共享它們,或者它可能是應(yīng)用程序啟動腳本的一部分。并且您希望此腳本將連接到數(shù)據(jù)庫或執(zhí)行其他需要憑據(jù)的操作。
當(dāng)然,將憑據(jù)存儲在腳本本身中是個壞主意,因為git是不安全的。
通常,您可以使用已經(jīng)在目標(biāo)環(huán)境上定義的變量,并且腳本本身將不包含密碼。
例如,您可以在具有700個權(quán)限的每個環(huán)境上創(chuàng)建小腳本,并使用主腳本中的source命令調(diào)用它:
- secret.sh
- PASSWORD=LOVESEXGOD
- myapp.sh
- source ~/secret.sh
- sqlplus -l user/"$PASSWORD"@database:port/sid @mysqfile.sql
但這并不安全。
如果其他人可以登錄到您的主機,則他只需執(zhí)行ps命令并查看帶有整個命令行參數(shù)(包括密碼)的sqlplus進程。因此,安全工具通常應(yīng)該能夠直接從文件中讀取密碼/密鑰/敏感數(shù)據(jù)。
例如,安全ssh甚至沒有任何選項可以在命令行中提供密碼。但是他可以從文件讀取ssh密鑰(并且可以在ssh密鑰文件上設(shè)置安全權(quán)限)。
非安全wget具有選項“ --password”,該選項使您可以在命令行中提供密碼。wget一直在運行,每個人都可以執(zhí)行ps命令并查看您提供的密碼。
另外,如果您有很多敏感數(shù)據(jù),并且想通過git控制它,那么唯一的方法就是加密。因此,您只需將每個主密碼以及所有其他可以加密并放入git的數(shù)據(jù)輸入到每個目標(biāo)環(huán)境。而且,您可以使用openssl CLI界面從命令行使用加密的數(shù)據(jù)。以下是從命令行進行加密和解密的示例:
文件secret.key包含主密鑰-單行:
- $ echo "secretpassword" > secret.key; chmod 600 secret.key
讓我們使用aes-256-cbc加密字符串:
- $ echo "string_to_encrypt" | openssl enc -pass file:secret.key -e -aes-256-cbc -a
- U2FsdGVkX194R0GmFKCL/krYCugS655yLhf8aQyKNcUnBs30AE5lHN5MXPjjSFML
您可以將此加密的字符串放入git或其他任何位置存儲的任何配置文件中-沒有secret.key,幾乎不可能對其進行解密。
要解密執(zhí)行同一命令,只需將-e替換為-d即可:
- $ echo 'U2FsdGVkX194R0GmFKCL/krYCugS655yLhf8aQyKNcUnBs30AE5lHN5MXPjjSFML' | openssl enc -pass file:secret.key -d -aes-256-cbc -a
- string_to_encrypt
5. grep命令
所有人都應(yīng)該知道grep命令。并且對正則表達式要友好。通常,您可以編寫如下內(nèi)容:
- tail -f application.log | grep -i error
甚至像這樣:
- tail -f application.log | grep -i -P "(error|warning|failure)"
但是不要忘記grep有很多很棒的選擇。例如-v,它會還原您的搜索并顯示除“ info”消息以外的所有消息:
- tail -f application.log | grep -v -i "info"
其他內(nèi)容:
選項-P非常有用,因為默認(rèn)情況下,grep使用相當(dāng)過時的«基本正則表達式:»,并且-P啟用PCRE,甚至不知道分組。
-i忽略大小寫。
--line-buffered立即解析行,而不是等待到達標(biāo)準(zhǔn)的4k緩沖區(qū)(對于tail -f | grep非常有用)。
如果您非常了解正則表達式,則使用--only-matching / -o可以真正實現(xiàn)剪切文本的出色功能。只需比較以下兩個命令以提取myuser的shell:
- $ grep myuser /etc/passwd| cut -d ":" -f 7
- $ grep -Po "^myuser(:.*){5}:\K.*" /etc/passwd
第二個命令看起來更編譯,但是它只運行grep而不是grep和cut,因此執(zhí)行時間會更少。
6.如何減少日志文件的大小
在* nix中,如果刪除應(yīng)用程序當(dāng)前正在使用的日志文件,則不能僅刪除所有日志,還可以阻止應(yīng)用程序在重新啟動之前編寫新日志。
由于文件描述符不是打開文件名而是打開iNode結(jié)構(gòu),因此應(yīng)用程序?qū)⒗^續(xù)將文件描述符寫入沒有目錄條目的文件,并且該文件將在應(yīng)用程序停止后由文件系統(tǒng)自動刪除(您的應(yīng)用程序可以每次想寫一些東西來避免這種問題時都要打開和關(guān)閉日志文件,但這會影響性能)。
因此,如何清除日志文件而不刪除它:
- echo "" > application.log
或者我們可以使用truncate命令:
- truncate --size=1M application.log
提及,該truncate命令將刪除文件的其余部分,因此您將丟失最新的日志事件。另一個示例如何存儲最后1000行:
- echo "$(tail -n 1000 application.log)" > application.log
PS在Linux中,我們有標(biāo)準(zhǔn)的服務(wù)rotatelog。您可以將日志添加到自動截斷/旋轉(zhuǎn)中,也可以使用現(xiàn)有的日志庫來完成(例如Java中的log4j)。
7. watch
在某些情況下,您正在等待事件結(jié)束。例如,當(dāng)另一個用戶登錄到shell(您連續(xù)執(zhí)行who命令)時,或者某人應(yīng)該使用scp或ftp將文件復(fù)制到您的計算機上時,您正在等待完成(重復(fù)ls數(shù)十次)。
在這種情況下,您可以使用
- watch <command>
默認(rèn)情況下,將每隔2秒鐘執(zhí)行一次,且屏幕會預(yù)先清除,直到按Ctrl + C。您可以配置執(zhí)行頻率。
當(dāng)您要觀看實時日志時,此功能非常有用。
8.bash順序
創(chuàng)建范圍非常有用。例如,而不是像這樣:
- for srv in 1 2 3 4 5; do echo "server${srv}";done
- server1
- server2
- server3
- server4
- server5
您可以編寫以下內(nèi)容:
- for srv in server{1..5}; do echo "$srv";done
- server1
- server2
- server3
- server4
- server5
您也可以使用seq命令生成格式化范圍。例如,我們可以使用seq創(chuàng)建值,將根據(jù)寬度(00、01而不是0、1)自動調(diào)整抽動:
- for srv in $(seq -w 5 10); do echo "server${srv}";done
- server05
- server06
- server07
- server08
- server09
- server10
使用命令替換的另一個示例-重命名文件。要獲取不帶擴展名的文件名,我們使用“ basename ”命令:
- for file in *.txt; do name=$(basename "$file" .txt);mv $name{.txt,.lst}; done
甚至還比'%'更短:
- for file in *.txt; do mv ${file%.txt}{.txt,.lst}; done
PS實際上,對于重命名文件,您可以嘗試使用具有許多選項的“ 重命名 ”工具。
另一個示例-讓我們?yōu)樾碌腏ava項目創(chuàng)建結(jié)構(gòu):
- mkdir -p project/src/{main,test}/{java,resources}
結(jié)果

9.tail, multiple files, multiple users...
我已經(jīng)提到了multitail來讀取文件并觀看多個實時日志。但是默認(rèn)情況下未提供該功能,并且安裝某些內(nèi)容的權(quán)限并非始終可用。
但是標(biāo)準(zhǔn)尾巴也可以做到:
- tail -f /var/logs/*.log
還讓您記住有關(guān)用戶的信息,這些用戶使用'tail -f'別名查看應(yīng)用程序日志。
多個用戶可以使用“ tail -f”同時觀看日志文件。他們中有些人的會話不太準(zhǔn)確。由于某種原因,他們可能會將'tail -f'留在背景中而忘記了。
如果重新啟動應(yīng)用程序,則有一些正在運行的“ tail -f”進程正在監(jiān)視不存在的日志文件,該進程可能會掛起幾天甚至幾個月。
通常這不是一個大問題,但不是整齊的。
如果您使用別名來查看日志,則可以使用--pid選項修改此別名:
- alias TFapplog='tail -f --pid=$(cat /opt/app/tmp/app.pid) /opt/app/logs/app.log'
在這種情況下,重新啟動目標(biāo)應(yīng)用程序時,所有尾部將自動終止。
10.創(chuàng)建具有指定大小的文件
dd是使用塊和二進制數(shù)據(jù)的最受歡迎的工具之一。例如,創(chuàng)建1 MB文件并填充零將是:
- dd if=/dev/zero of=out.txt bs=1M count=10
但我建議使用fallocate:
- fallocate -l 10M file.txt
在支持分配功能(xfs,ext4,Btrfs ...)的文件系統(tǒng)上,fallocate將立即執(zhí)行,這與dd工具不同。另外,分配是指實際分配塊,而不是創(chuàng)建備用文件。
11. xargs
很多人都知道流行的xargs命令。但是并非所有人都使用以下兩個選項,因此可以極大地改善腳本。
首先-您可以獲得非常長的參數(shù)列表,并且可能超過命令行長度(默認(rèn)情況下〜4 kb)。
但是您可以使用-n選項限制執(zhí)行,因此xargs將多次運行命令,一次發(fā)送指定數(shù)量的參數(shù):
- $ # lets print 5 arguments and send them to echo with xargs:
- $ echo 1 2 3 4 5 | xargs echo
- 1 2 3 4 5
- $ # now let’s repeat, but limit argument processing by 3 per execution
- $ echo 1 2 3 4 5 | xargs -n 3 echo
- 1 2 3
- 4 5
來吧 處理長列表可能需要很多時間,因為它在單個線程中運行。但是,如果我們有幾個核心,我們可以告訴xargs并行運行:
- echo 1 2 3 4 5 6 7 8 9 10| xargs -n 2 -P 3 echo
在上面的示例中,我們告訴xargs處理3個線程中的list;每個線程每次執(zhí)行將接受并處理2個參數(shù)。如果您不知道自己有多少個內(nèi)核,請使用“ nproc ” 進行優(yōu)化:
- echo 1 2 3 4 5 6 7 8 9 10 | xargs -n 2 -P $(nproc) echo
12.sleep? while? read!
有時您需要等待幾秒鐘。或等待用戶輸入以下內(nèi)容:
- read -p "Press any key to continue " -n 1
但是您只需添加超時選項以讀取命令,腳本就會暫停指定的秒數(shù),但是在交互執(zhí)行的情況下,用戶可以輕松地跳過等待。
- read -p "Press any key to continue (auto continue in 30 seconds) " -t 30 -n 1
因此,您只需忘記睡眠命令即可。