學習Kafka,先從這四個基礎概念入手
Kafka 創建背景
Kafka 是一個消息系統,原本開發自 LinkedIn,用作 LinkedIn 的活動流(Activity Stream)和運營數據處理管道(Pipeline)的基礎。現在它已被多家不同類型的公司 作為多種類型的數據管道和消息系統使用。
活動流數據是幾乎所有站點在對其網站使用情況做報表時都要用到的數據中最常規的部分。活動數據包括頁面訪問量(Page View)、被查看內容方面的信息以及搜索情況等內容。這種數據通常的處理方式是先把各種活動以日志的形式寫入某種文件,然后周期性地對這些文件進行統計分析。運營數據指的是服務器的性能數據(CPU、IO 使用率、請求時間、服務日志等等數據)。運營數據的統計方法種類繁多。
近年來,活動和運營數據處理已經成為了網站軟件產品特性中一個至關重要的組成部分,這就需要一套稍微更加復雜的基礎設施對其提供支持。
Kafka 簡介
Kafka 是一種分布式的,基于發布 / 訂閱的消息系統。主要設計目標如下:
- 以時間復雜度為 O(1) 的方式提供消息持久化能力,即使對 TB 級以上數據也能保證常數時間復雜度的訪問性能。
- 高吞吐率。即使在非常廉價的商用機器上也能做到單機支持每秒 100K 條以上消息的傳輸。
- 支持 Kafka Server 間的消息分區,及分布式消費,同時保證每個 Partition 內的消息順序傳輸。
- 同時支持離線數據處理和實時數據處理。
- Scale out:支持在線水平擴展。
Kafka 基礎概念
概念一:生產者與消費者
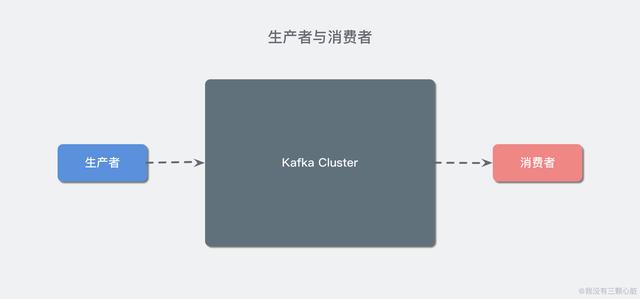
對于 Kafka 來說客戶端有兩種基本類型:生產者(Producer)和消費者(Consumer)。除此之外,還有用來做數據集成的 Kafka Connect API 和流式處理的 Kafka Streams 等高階客戶端,但這些高階客戶端底層仍然是生產者和消費者API,它們只不過是在上層做了封裝。
這很容易理解,生產者(也稱為發布者)創建消息,而消費者(也稱為訂閱者)負責消費or讀取消息。
概念二:主題(Topic)與分區(Partition)
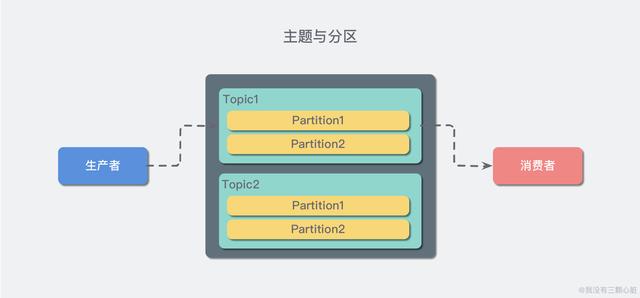
在 Kafka 中,消息以主題(Topic)來分類,每一個主題都對應一個「消息隊列」,這有點兒類似于數據庫中的表。但是如果我們把所有同類的消息都塞入到一個“中心”隊列中,勢必缺少可伸縮性,無論是生產者/消費者數目的增加,還是消息數量的增加,都可能耗盡系統的性能或存儲。
我們使用一個生活中的例子來說明:現在 A 城市生產的某商品需要運輸到 B 城市,走的是公路,那么單通道的高速公路不論是在「A 城市商品增多」還是「現在 C 城市也要往 B 城市運輸東西」這樣的情況下都會出現「吞吐量不足」的問題。所以我們現在引入分區(Partition)的概念,類似“允許多修幾條道”的方式對我們的主題完成了水平擴展。
概念三:Broker 和集群(Cluster)
一個 Kafka 服務器也稱為 Broker,它接受生產者發送的消息并存入磁盤;Broker 同時服務消費者拉取分區消息的請求,返回目前已經提交的消息。使用特定的機器硬件,一個 Broker 每秒可以處理成千上萬的分區和百萬量級的消息。(現在動不動就百萬量級..我特地去查了一把,好像確實集群的情況下吞吐量挺高的..摁..)
若干個 Broker 組成一個集群(Cluster),其中集群內某個 Broker 會成為集群控制器(Cluster Controller),它負責管理集群,包括分配分區到 Broker、監控 Broker 故障等。在集群內,一個分區由一個 Broker 負責,這個 Broker 也稱為這個分區的 Leader;當然一個分區可以被復制到多個 Broker 上來實現冗余,這樣當存在 Broker 故障時可以將其分區重新分配到其他 Broker 來負責。下圖是一個樣例:
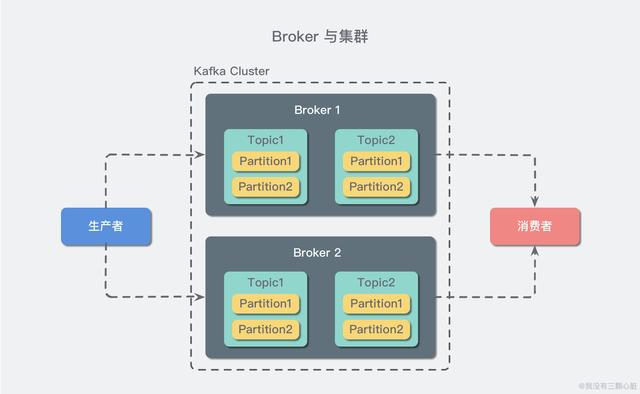
Kafka 的一個關鍵性質是日志保留(retention),我們可以配置主題的消息保留策略,譬如只保留一段時間的日志或者只保留特定大小的日志。當超過這些限制時,老的消息會被刪除。我們也可以針對某個主題單獨設置消息過期策略,這樣對于不同應用可以實現個性化。
概念四:多集群
隨著業務發展,我們往往需要多集群,通常處于下面幾個原因:
- 基于數據的隔離;
- 基于安全的隔離;
- 多數據中心(容災)
當構建多個數據中心時,往往需要實現消息互通。舉個例子,假如用戶修改了個人資料,那么后續的請求無論被哪個數據中心處理,這個更新需要反映出來。又或者,多個數據中心的數據需要匯總到一個總控中心來做數據分析。
上面說的分區復制冗余機制只適用于同一個 Kafka 集群內部,對于多個 Kafka 集群消息同步可以使用 Kafka 提供的 MirrorMaker 工具。本質上來說,MirrorMaker 只是一個 Kafka 消費者和生產者,并使用一個隊列連接起來而已。它從一個集群中消費消息,然后往另一個集群生產消息。