大數據干貨:Hadoop 面試中 7 個必問問題及答案
1.什么是Hadoop?
Hadoop是一個開源軟件框架,用于存儲大量數據,并發處理/查詢在具有多個商用硬件(即低成本硬件)節點的集群上的那些數據。總之,Hadoop包括以下內容:
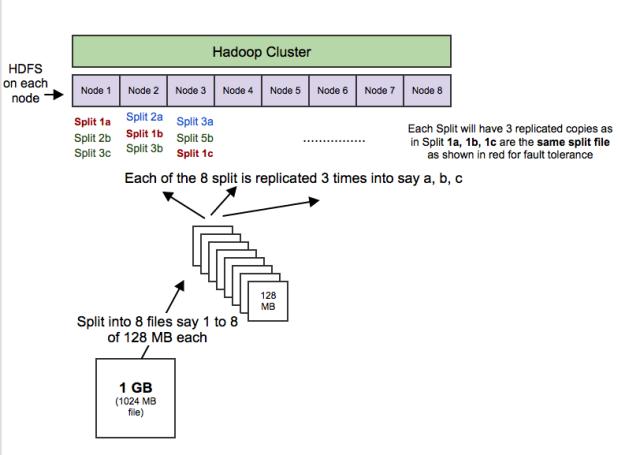
HDFS(Hadoop Distributed File System,Hadoop分布式文件系統):HDFS允許你以一種分布式和冗余的方式存儲大量數據。例如,1 GB(即1024 MB)文本文件可以拆分為16 * 128MB文件,并存儲在Hadoop集群中的8個不同節點上。每個分裂可以復制3次,以實現容錯,以便如果1個節點故障的話,也有備份。HDFS適用于順序的“一次寫入、多次讀取”的類型訪問。
MapReduce:一個計算框架。它以分布式和并行的方式處理大量的數據。當你對所有年齡> 18的用戶在上述1 GB文件上執行查詢時,將會有“8個映射”函數并行運行,以在其128 MB拆分文件中提取年齡> 18的用戶,然后“reduce”函數將運行以將所有單獨的輸出組合成單個最終結果。
YARN(Yet Another Resource Nagotiator,又一資源定位器):用于作業調度和集群資源管理的框架。
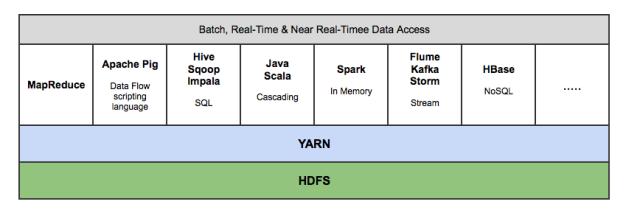
Hadoop生態系統,擁有15多種框架和工具,如Sqoop,Flume,Kafka,Pig,Hive,Spark,Impala等,以便將數據攝入HDFS,在HDFS中轉移數據(即變換,豐富,聚合等),并查詢來自HDFS的數據用于商業智能和分析。某些工具(如Pig和Hive)是MapReduce上的抽象層,而Spark和Impala等其他工具則是來自MapReduce的改進架構/設計,用于顯著提高的延遲以支持近實時(即NRT)和實時處理。
2.為什么組織從傳統的數據倉庫工具轉移到基于Hadoop生態系統的智能數據中心?
Hadoop組織正在從以下幾個方面提高自己的能力:
現有數據基礎設施:
- 主要使用存儲在高端和昂貴硬件中的“structured data,結構化數據”
- 主要處理為ETL批處理作業,用于將數據提取到RDBMS和數據倉庫系統中進行數據挖掘,分析和報告,以進行關鍵業務決策。
- 主要處理以千兆字節到兆字節為單位的數據量
基于Hadoop的更智能的數據基礎設施,其中
- 結構化(例如RDBMS),非結構化(例如images,PDF,docs )和半結構化(例如logs,XMLs)的數據可以以可擴展和容錯的方式存儲在較便宜的商品機器中。
- 可以通過批處理作業和近實時(即,NRT,200毫秒至2秒)流(例如Flume和Kafka)來攝取數據。
- 數據可以使用諸如Spark和Impala之類的工具以低延遲(即低于100毫秒)的能力查詢。
- 可以存儲以兆兆字節到千兆字節為單位的較大數據量。
這使得組織能夠使用更強大的工具來做出更好的業務決策,這些更強大的工具用于獲取數據,轉移存儲的數據(例如聚合,豐富,變換等),以及使用低延遲的報告功能和商業智能。
3.更智能&更大的數據中心架構與傳統的數據倉庫架構有何不同?
傳統的企業數據倉庫架構
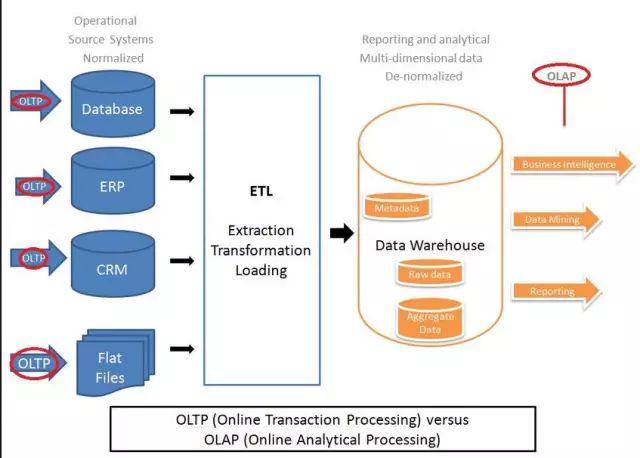
基于Hadoop的數據中心架構
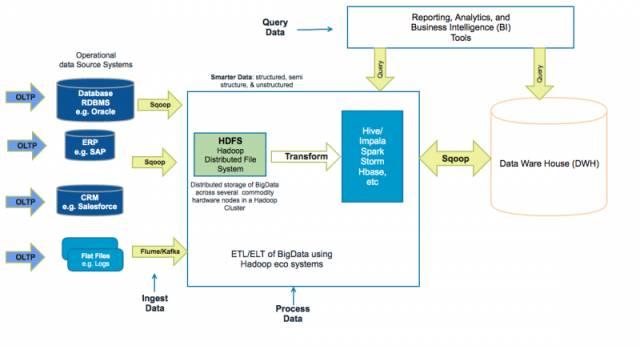
4.基于Hadoop的數據中心的好處是什么?
隨著數據量和復雜性的增加,提高了整體SLA(即服務水平協議)。例如,“Shared Nothing”架構,并行處理,內存密集型處理框架,如Spark和Impala,以及YARN容量調度程序中的資源搶占。
縮放數據倉庫可能會很昂貴。添加額外的高端硬件容量以及獲取數據倉庫工具的許可證可能會顯著增加成本。基于Hadoop的解決方案不僅在商品硬件節點和開源工具方面更便宜,而且還可以通過將數據轉換卸載到Hadoop工具(如Spark和Impala)來補足數據倉庫解決方案,從而更高效地并行處理大數據。這也將釋放數據倉庫資源。
探索新的渠道和線索。Hadoop可以為數據科學家提供探索性的沙盒,以從社交媒體,日志文件,電子郵件等地方發現潛在的有價值的數據,這些數據通常在數據倉庫中不可得。
更好的靈活性。通常業務需求的改變,也需要對架構和報告進行更改。基于Hadoop的解決方案不僅可以靈活地處理不斷發展的模式,還可以處理來自不同來源,如社交媒體,應用程序日志文件,image,PDF和文檔文件的半結構化和非結構化數據。
5.大數據解決方案的關鍵步驟是什么?
提取數據,存儲數據(即數據建模)和處理數據(即數據加工,數據轉換和查詢數據)。
提取數據
從各種來源提取數據,例如:
- RDBM(Relational Database Management Systems)關系數據庫管理系統,如Oracle,MySQL等。
- ERPs(Enterprise Resource Planning)企業資源規劃(即ERP)系統,如SAP。
- CRM(Customer Relationships Management)客戶關系管理系統,如Siebel,Salesforce等
- 社交媒體Feed和日志文件。
- 平面文件,文檔和圖像。
并將其存儲在基于“Hadoop分布式文件系統”(簡稱HDFS)的數據中心上。可以通過批處理作業(例如每15分鐘運行一次,每晚一次,等),近實時(即100毫秒至2分鐘)流式傳輸和實時流式傳輸(即100毫秒以下)去采集數據。
Hadoop中使用的一個常用術語是“Schema-On-Read”。這意味著未處理(也稱為原始)的數據可以被加載到HDFS,其具有基于處理應用的需求在處理之時應用的結構。這與“Schema-On-Write”不同,后者用于需要在加載數據之前在RDBM中定義模式。
存儲數據
數據可以存儲在HDFS或NoSQL數據庫,如HBase。HDFS針對順序訪問和“一次寫入和多次讀取”的使用模式進行了優化。HDFS具有很高的讀寫速率,因為它可以將I / O并行到多個驅動器。HBase在HDFS之上,并以柱狀方式將數據存儲為鍵/值對。列作為列家族在一起。HBase適合隨機讀/寫訪問。在Hadoop中存儲數據之前,你需要考慮以下幾點:
- 數據存儲格式:有許多可以應用的文件格式(例如CSV,JSON,序列,AVRO,Parquet等)和數據壓縮算法(例如snappy,LZO,gzip,bzip2等)。每個都有特殊的優勢。像LZO和bzip2的壓縮算法是可拆分的。
- 數據建模:盡管Hadoop的無模式性質,模式設計依然是一個重要的考慮方面。這包括存儲在HBase,Hive和Impala中的對象的目錄結構和模式。Hadoop通常用作整個組織的數據中心,并且數據旨在共享。因此,結構化和有組織的數據存儲很重要。
- 元數據管理:與存儲數據相關的元數據。
- 多用戶:更智能的數據中心托管多個用戶、組和應用程序。這往往導致與統治、標準化和管理相關的挑戰。
處理數據
Hadoop的處理框架使用HDFS。它使用“Shared Nothing”架構,在分布式系統中,每個節點完全獨立于系統中的其他節點。沒有共享資源,如CPU,內存以及會成為瓶頸的磁盤存儲。Hadoop的處理框架(如Spark,Pig,Hive,Impala等)處理數據的不同子集,并且不需要管理對共享數據的訪問。 “Shared Nothing”架構是非常可擴展的,因為更多的節點可以被添加而沒有更進一步的爭用和容錯,因為每個節點是獨立的,并且沒有單點故障,系統可以從單個節點的故障快速恢復。
6.你會如何選擇不同的文件格式存儲和處理數據?
設計決策的關鍵之一是基于以下方面關注文件格式:
- 使用模式,例如訪問50列中的5列,而不是訪問大多數列。
- 可并行處理的可分裂性。
- 塊壓縮節省存儲空間vs讀/寫/傳輸性能
- 模式演化以添加字段,修改字段和重命名字段。
CSV文件
CSV文件通常用于在Hadoop和外部系統之間交換數據。CSV是可讀和可解析的。 CSV可以方便地用于從數據庫到Hadoop或到分析數據庫的批量加載。在Hadoop中使用CSV文件時,不包括頁眉或頁腳行。文件的每一行都應包含記錄。CSV文件對模式評估的支持是有限的,因為新字段只能附加到記錄的結尾,并且現有字段不能受到限制。CSV文件不支持塊壓縮,因此壓縮CSV文件會有明顯的讀取性能成本。
JSON文件
JSON記錄與JSON文件不同;每一行都是其JSON記錄。由于JSON將模式和數據一起存儲在每個記錄中,因此它能夠實現完整的模式演進和可拆分性。此外,JSON文件不支持塊級壓縮。
序列文件
序列文件以與CSV文件類似的結構用二進制格式存儲數據。像CSV一樣,序列文件不存儲元數據,因此只有模式進化才將新字段附加到記錄的末尾。與CSV文件不同,序列文件確實支持塊壓縮。序列文件也是可拆分的。序列文件可以用于解決“小文件問題”,方式是通過組合較小的通過存儲文件名作為鍵和文件內容作為值的XML文件。由于讀取序列文件的復雜性,它們更適合用于在飛行中的(即中間的)數據存儲。
注意:序列文件是以Java為中心的,不能跨平臺使用。
Avro文件
適合于有模式的長期存儲。Avro文件存儲具有數據的元數據,但也允許指定用于讀取文件的獨立模式。啟用完全的模式進化支持,允許你通過定義新的獨立模式重命名、添加和刪除字段以及更改字段的數據類型。Avro文件以JSON格式定義模式,數據將采用二進制JSON格式。Avro文件也是可拆分的,并支持塊壓縮。更適合需要行級訪問的使用模式。這意味著查詢該行中的所有列。不適用于行有50+列,但使用模式只需要訪問10個或更少的列。Parquet文件格式更適合這個列訪問使用模式。
Columnar格式,例如RCFile,ORC
RDBM以面向行的方式存儲記錄,因為這對于需要在獲取許多列的記錄的情況下是高效的。如果在向磁盤寫入記錄時已知所有列值,則面向行的寫也是有效的。但是這種方法不能有效地獲取行中的僅10%的列或者在寫入時所有列值都不知道的情況。這是Columnar文件更有意義的地方。所以Columnar格式在以下情況下工作良好
- 在不屬于查詢的列上跳過I / O和解壓縮
- 用于僅訪問列的一小部分的查詢。
- 用于數據倉庫型應用程序,其中用戶想要在大量記錄上聚合某些列。
RC和ORC格式是專門用Hive寫的而不是通用作為Parquet。
Parquet文件
Parquet文件是一個columnar文件,如RC和ORC。Parquet文件支持塊壓縮并針對查詢性能進行了優化,可以從50多個列記錄中選擇10個或更少的列。Parquet文件寫入性能比非columnar文件格式慢。Parquet通過允許在最后添加新列,還支持有限的模式演變。Parquet可以使用Avro API和Avro架構進行讀寫。
所以,總而言之,相對于其他,你應該會更喜歡序列,Avro和Parquet文件格式;序列文件用于原始和中間存儲,Avro和Parquet文件用于處理。