













CPU緩存與內(nèi)存屏障,你了解嗎?
CPU緩存
CPU緩存是位于CPU與內(nèi)存之間的臨時存儲器,它的容量比內(nèi)存小的多,但是交換速度比內(nèi)存快得多。高速緩存主要是為了解決CPU運算速度與內(nèi)存讀寫速度不匹配的矛盾,因為CPU運算速度比內(nèi)存快得多,這樣會使CPU花費很長時間等待數(shù)據(jù)或者將數(shù)據(jù)寫入內(nèi)存,當CPU調(diào)用大量數(shù)據(jù)時,可以先從緩存中調(diào)用,從而加快讀取速度。
CPU多級緩存
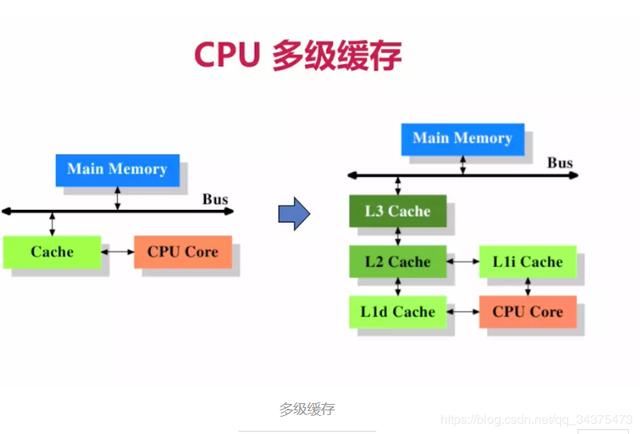
在CPU緩存出現(xiàn)不久,隨著系統(tǒng)越來越復雜,高速緩存和主內(nèi)存之間的速度被拉大,直到加入了另一級緩存,新加入的這級緩存比第一緩存更大,并且更慢,而且經(jīng)濟上不合適,所以有了二級緩存,甚至是三級緩存。每一級緩存中所儲存的全部數(shù)據(jù)都是下一級緩存的一部分,這三種緩存的技術(shù)難度和制造成本是相對遞減的,所以其容量也是相對遞增的。當CPU要讀取一個數(shù)據(jù)時,首先從一級緩存中查找,如果沒有找到再從二級緩存中查找,如果還是沒有就從三級緩存或內(nèi)存中查找。一般來說,每級緩存的命中率大概都在80%左右,也就是說全部數(shù)據(jù)量的80%都可以在一級緩存中找到,只剩下20%的總數(shù)據(jù)量才需要從二級緩存、三級緩存或內(nèi)存中讀取,由此可見一級緩存是整個CPU緩存架構(gòu)中最為重要的部分。
CPU緩存一致性
多核CPU的情況下有多個一級緩存,如何保證緩存內(nèi)部數(shù)據(jù)的一致,不讓系統(tǒng)數(shù)據(jù)混亂。這里就引出了一個一致性的協(xié)議MESI。
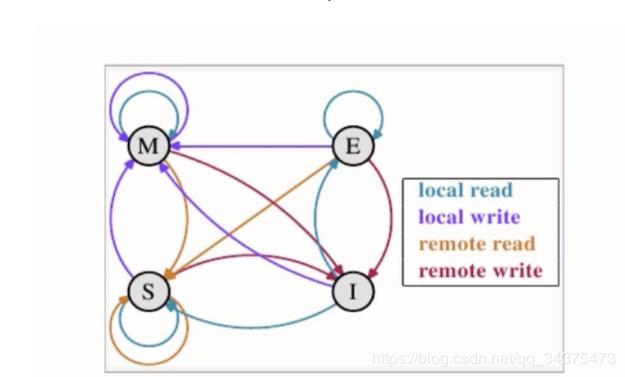
CPU中每個緩存行使用四種狀態(tài)進行標記
M(被修改,Modified):
該緩存行只緩存在該CPU緩存中,并 且是被修改過的,與主內(nèi)存數(shù)據(jù)不一 致,緩 存行的數(shù)據(jù)需要在未來某個時 間點寫回主內(nèi)存。當被寫回主內(nèi)存 之后,該緩存行就會變成獨享狀態(tài)。
E(獨享的,Exclusive)
該緩存行只被緩存在該CPU緩存中,并且與主存數(shù)據(jù)一致,可以在任何時刻當有其他CPU讀取該內(nèi)存時變成共享(shared)狀態(tài),同樣的,當CPU修改該緩存內(nèi)容時,該狀態(tài)可以變成M狀態(tài)。
S(共享的,Shared)
該狀態(tài)意味著該緩存行可能被多個CPU緩存,并且各個緩存與主內(nèi)存數(shù)據(jù)一致,當有一個CPU修改該緩存行時,其他CPU中該緩存行可以被作廢(變成無效狀態(tài)(Invalid))
I(無效的,Invalid)
該緩存是無效的(可能有其他CPU修改了 該緩存行)。
在一個典型系統(tǒng)中,可能會有幾個緩存共享主存總線,每個相應的CPU會發(fā)出讀寫請求,而緩存的目的就是減少CPU讀寫共享主存的次數(shù)。
一個緩存除在I狀態(tài)外都可以滿足cpu的讀請求,一個invalid的緩存行必須從主存中讀取來滿足該CPU的請求。
一個寫請求必須是在M或E狀態(tài)才能被執(zhí)行,如果緩存行處于S狀態(tài),必須先將其它緩存中該緩存行變成Invalid狀態(tài)(也即是不允許不同CPU同時修改同一緩存行,即使該緩存行中不同位置也不允許)。
一個處于M狀態(tài)的緩存行必須時刻監(jiān)控所有試圖讀取該緩存行相對主內(nèi)存的操作,這種操作必須在緩存將該緩存行寫回主內(nèi)存并將狀態(tài)變成S之前被延遲執(zhí)行。
一個處于S狀態(tài)的緩存行也必須時刻監(jiān)聽其他緩存行使該緩存行無效或者獨享緩存行的請求,并將該緩存行變成無效。
一個處于E狀態(tài)的緩存行也時刻監(jiān)聽其他緩存讀主存中該緩存行的操作,一旦有這種操作,該緩存行需要變成S狀態(tài)。
對于M和E狀態(tài)而言總是精確的,他們在和該緩存行的真正狀態(tài)是一致的。而s狀態(tài)可能是非一致的,如果一個緩存將處于S狀態(tài)的緩存行作廢,而另一個緩存實際可能已經(jīng)獨享了該緩存,但是該緩存卻不會將該緩存行升遷為E狀態(tài),這是因為其他緩存不會廣播他們作廢掉該緩存行的通知。
同樣由于緩存并沒有保存該緩存行的copy的數(shù)量,因此(即使有這種通知)也沒有辦法確定自己是否已經(jīng)獨享了該緩存行。
CPU亂序執(zhí)行
處理器為提高運算速度而做出的違背代碼原有順序的優(yōu)化。
例如:a=10,b=20,result=a+b,正常順序先執(zhí)行a,再執(zhí)行b,最后執(zhí)行a+b,但假如a不在緩存中,b在緩存中,因為a不在緩存中,需要從主內(nèi)存讀取,這樣b=20的操作就需要等待a執(zhí)行完,CPU為了提高效率,先執(zhí)行b=20,再執(zhí)行a=10,最后執(zhí)行a+b,提高執(zhí)行效率。
內(nèi)存屏障
CPU亂序執(zhí)行在單線程環(huán)境下是一種很好的優(yōu)化手段,但是在多線程環(huán)境下,就會出現(xiàn)數(shù)據(jù)不一致的問題,因此就可以通過內(nèi)存屏障這個機制來處理這個問題。
1.寫內(nèi)存屏障(Store Memory Barrier):在指令后插入Store Barrier,能讓寫入緩存中最新數(shù)據(jù)更新寫入主內(nèi)存中,讓其他線程可見。強制寫入主內(nèi)存,這種顯示調(diào)用,不會讓CPU去進行指令重排序
2.讀內(nèi)存屏障(Load Memory Barrier):在指令后插入Load Barrier,可以讓高速緩存中的數(shù)據(jù)失效,強制重新從主內(nèi)存中加載數(shù)據(jù)。也是不會讓CPU去進行指令重排。
















