













并發原理之MESI與內存屏障
現代的CPU比內存系統快很多,2006年的cpu可以在一納秒之內執行10條指令,但是需要多個十納秒去從內存讀取一個數據,這里面產生了至少兩個數量級的速度差距。在這樣的問題下,cpu cache應運而生。
cache處于cpu與內存之間,讀寫速度比內存快很多,但也比較昂貴。
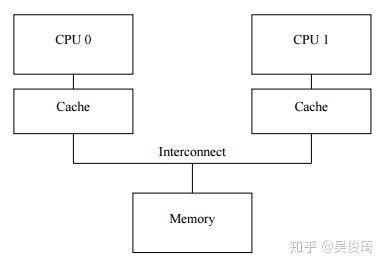
cache是以cache line為基本單位來進行讀寫的,cache line的大小是2的冪次,從16字節到256字節不等。
上圖就是一個cpu cache的架構示意圖,總共有32個cache line,每個cache line是256字節。cacheline的起始地址低8位都是0,使用內存地址的9-12位數據來進行hash。
當cpu在cache里尋找數據時,如果數據不存在,則會產生一個cache miss,這時候cpu需要等待數據從內存讀回,這需要耗費很長時間,但是因為讀取之后會存儲到cache中,所以以后的讀取就會變得非常快。為了減少cache miss造成的性能損失,現代的cpu單核可以超線程,一個線程等待的時候,另一個線程就能執行指令了。
為什么會有cache miss,一種是數據預熱,機器剛啟動的時候,cache是沒有數據的,還有一種情況是cache不足,需要淘汰舊的數據。
我們用的最多的緩存一致性協議是MESI,四個字母分別表示modified, exclusive, shared, invalid,這是cache line的四種狀態,
modified:數據是被該cpu獨占的,其他cpu沒有存儲該數據。
exclusive:這個狀態跟modified很類似,只是該狀態下,cache的數據已經同步到主存了,所以即使丟棄也無所謂。
shared:數據存在于多個cpu cache里,每個cpu對該數據只能讀,而不能簡單地寫
invalid:該cache line是空的
Read:read消息會帶上cache line的物理內存地址向其他cpu獲取數據
Read Response:如果其他cpu有這個cache line,并且處于modified,那么該cpu必須返回該消息,因為其他cpu的cache line和主存都沒有最新的數據
Invalidate:invalidate消息會帶上cache line的物理內存地址,來讓其他cache把相應的數據從cache line里去除掉
Invalidate Acknowledge:如果一個cpu收到Invalidate消息,那么它必須在刪除數據之后返回該消息
Read Invalidate:該消息是Read和Invalidate的組合,所以它需要一個Read Response和多個Invalidate Acknowledge
Writeback:modified狀態的cache line寫到主存,可以用來騰出空間給其他數據
我們現在來看一下MESI各種狀態之間的遷移:
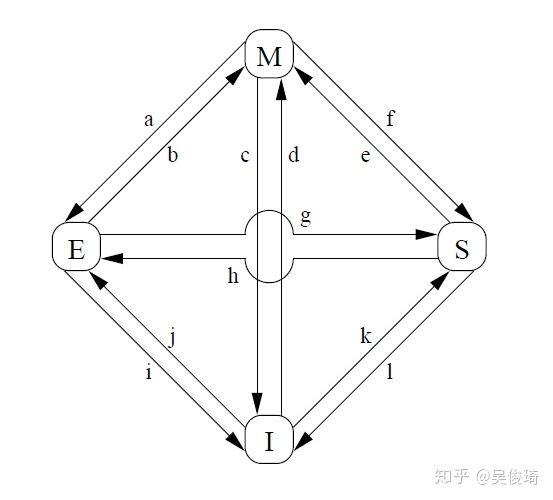
a) cpu把cacheline 回寫到內存,此時該cpu對這個cacheline還是有獨占權
b) cacheline 被cpu修改,該操作不需要cpu之間通信
c) cpu收到read invalidate之后,本地cacheline失效
d) cacheline 被本地cpu修改,需要和其他cpu通信,發出read invalidate 獲取最新的數據
e) cacheline 被本地cpu修改,需要向其他cpu發出invalidate請求
f) 其他cpu發來read請求
g) 其他cpu發來read請求
h) cpu意識到它馬上要寫數據到cacheline,所以提前發出invalidate消息給其他cpu
i) 其他cpu發來read invalidate
j) cpu在寫數據之前發出read invalidate消息給其他cpu,之后就處于e狀態,該狀態很快就可能變成m狀態
k) cpu發出read請求
l) 收到invalidate請求
雖然MESI協議能保證讀寫內存的高性能,但還是有點問題:
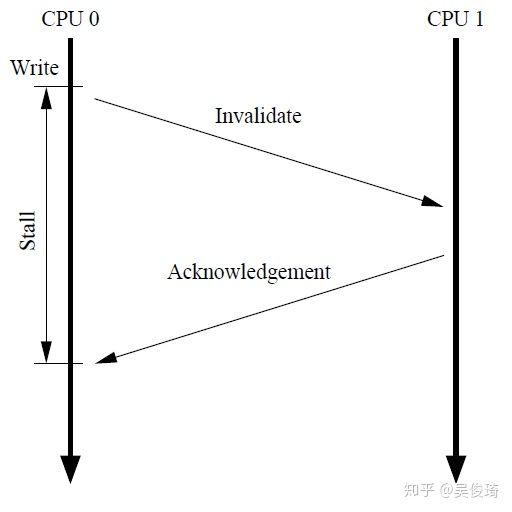
當cpu0要寫數據到本地cache的時候,如果不是M或者E狀態,需要發送一個invalidate消息給cpu1,只有收到cpu1的acknowledgement才能寫數據到cache中,在這個過程中cpu0需要等待,這大大影響了性能。一種解決辦法是在cpu和cache之間引入store buffer,當發出invalidate之后直接把數據寫入store buffer。當收到acknowledgement之后可以把store buffer中的數據寫入cache。現在的架構圖是這樣的:
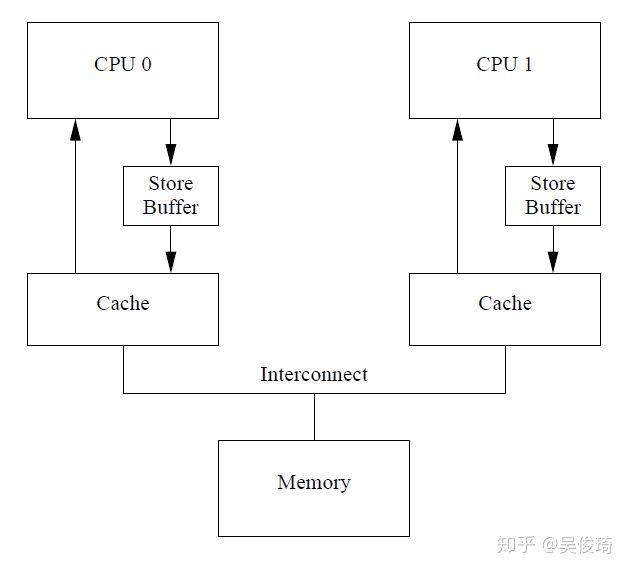
現在這樣的架構引入了復雜性,看下面的例子:
cpu0cache里面有個b,初值為0,cpu1cache有個a,初值為0,現在cpu0運行代碼
- a=1;
- b=a+1;
- assert(b==2)
cpu0執行a=1的時候發現本地cache沒有a,所以發送read invalidate給cpu1,然后把a=1寫入store buffer
cpu1收到read invalidate之后把a傳給cpu0并且本地cacheline置為無效
cpu0開始執行b=a+1
cpu0收到cpu1的read response,發現a=0
cpu0執行a+1,得到1賦給b
cpu0執行最后一句,失敗
這里關鍵的問題是cpu會把自己的操作看做是全局的內存操作,但其實操作storebuffer沒有操作到主存,所以我們需要在查cache的時候還得查一下store buffer,這種技術叫做store forwarding.
現在的架構是這樣的:
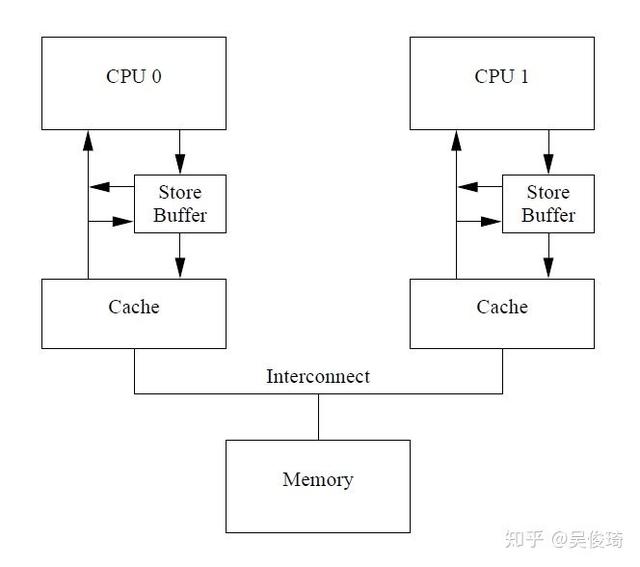
上面是store buffer在一個cpu中碰到的問題,在多個cpu并發的過程中也可能存在問題,看下例:
- void foo(void)
- {
- a = 1;
- b = 1;
- }
- void bar(void)
- {
- while (b == 0) continue;
- assert(a == 1);
- }
同樣的,cpu0cache里面有個b,初值為0,cpu1cache有個a,初值為0,現在cpu0運行foo, cpu1運行bar
cpu0 發現a不在本地cache,發送read invalidate去cpu1,并在store buffer中把a置為1
cpu1 執行while (b == 0)發現b不在本地內存,發送read消息去cpu0
cpu0 在本地cache置b為1
cpu0收到read消息,把cache中的b傳送給cpu1,并把本地狀態置為s
cpu1發現b為1,退出循環,因為這時候cpu1本地cache中a還是1,所以失敗
cpu1收到read invalidate,把a傳輸給cpu0,并置本地cache為invalidate但是太晚了
cpu0收到cpu1關于a的read response,把本地的store buffer移到cache中
第一個問題硬件工程署可以解決,但是第二個很難處理,因為硬件無法知道變量之間的依賴關系,硬件工程師設計了memory barrier(內存屏障),軟件可以使用這個工具來提示cpu變量之間的關系。新的代碼如下:
- void foo(void)
- {
- a = 1;
- smp_mb();
- b = 1;
- }
- void bar(void)
- {
- while (b == 0) continue;
- assert(a == 1);
- }
內存屏障smp_mb()提示cpu在進行smp_mb之后的存儲的時候,會先把store buffer里的數據刷新到cache中。有兩種方式,1:cpu會等到store buffer清空之后再處理其他指令,或者2:之后的所有寫操作都不寫到cache,而是寫到store buffer中,直到smp_mb之前的store buffer中的數據刷新到cache中。
上例中的執行效果如下:
cpu0執行 a=1,發現a不在本地cache中,進而把a=1寫入store buffer,并發出read invalidate消息給cpu1
cpu1執行while (b == 0),發現b不在本地cache中,進而發出read消息給cpu0
cpu0執行smp_mb,把store buffer中的a標記一下
cpu0執行b=1 發現狀態為獨占,所以可以直接寫,但是因為store buffer中有標記過的值,所以把b=1寫入store buffer,但是不標記
cpu0收到read消息,把cache中b的數據0發給cpu1,并把cacheline置為s
cpu1收到b=0,陷入循環中
cpu0收到read invalidate消息,進而把a=1從store buffer寫入cache,這時候可以把store buffer中的b=1寫入cache,但是發現這時候cache中的b屬于s狀態,所以發出invalidate消息給cpu1
cpu1收到invalidate消息之后把b設為1
cpu0收到invalidate ack之后把b的值1寫入cache
cpu1要讀取b的值,發出read消息給cpu0,
cpu0把b=1發給cpu1
cpu1收到b的值1,退出循環
cpu1發現a無效,發出read消息給cpu0
cpu0把a的值1發送給cpu1,并且把a置為s
cpu1得到a=1,成功
但是內存屏障的處理方法有個問題,那就是store buffer空間是有限的,如果store buffer中的空間被smp_mb之后的存儲塞滿,cpu還是得等待invalidate消息返回才能繼續處理。解決這種問題的思路是讓invalidate ack能更早得返回,一種辦法是提供一種放置invalidate message的隊列,稱為invalidate queue. cpu可以在收到invalidate之后馬上返回invalidate ack,而不是在把本地cache invalidate之后,并把invalidate message放置到invalide queue,以待之后處理。
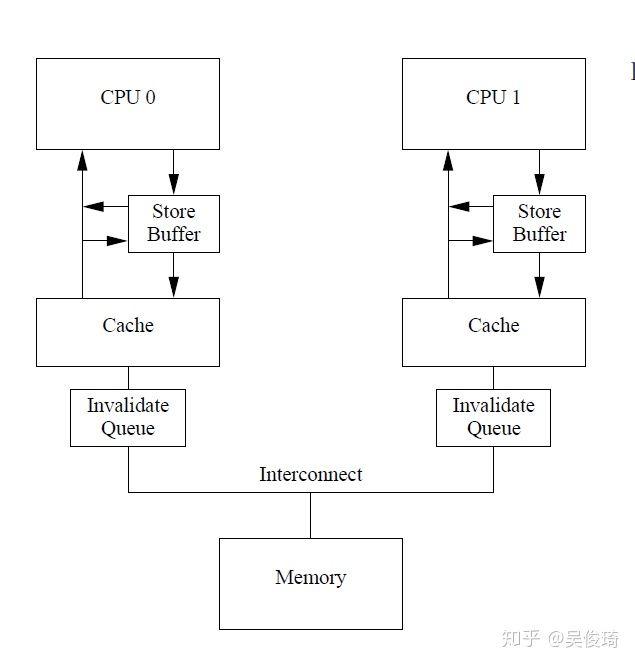
但是這種方法會使得我們之前的內存屏障的例子也失效,主要是因為在cpu1收到cpu0關于a的invalidate消息之后直接ack,而沒有真正invalidate cache,導致退出循環之后發現a是有效的,執行assert(a==1)失敗
- void foo(void)
- {
- a = 1;
- smp_mb();
- b = 1;
- }
- void bar(void)
- {
- while (b == 0) continue;
- smp_mb();
- assert(a == 1);
- }
在assert之前插入內存屏障,作用是把invalidate queue標記下,在讀取下面的數據的時候,譬如a的時候會先把invalidate queue中的消息都處理掉,這里的話會使得a失效而去cpu0獲取最新的數據。
進而我們知道smp_mb有兩個作用,1,標記store buffer,在處理之后的寫請求之前需要把store buffer中的數據apply到cache,2,標記invalidate queue,在加載之后的數據之前把invalidate queue中的消息都處理掉
進而我們再觀察上面的例子,我們發現,在foo中我們不需要處理invalidate queue,而在bar中,我們不需要處理store buffer,我們可以使用一種更弱的內存屏障來修改上例讓我們程序的性能更高,smp_wmb寫屏障,只會標記store buffer,smp_rmb讀屏障,只會標記invalidate queue,代碼如下:
- void foo(void)
- {
- a = 1;
- smp_wmb();
- b = 1;
- }
- void bar(void)
- {
- while (b == 0) continue;
- smp_rmb();
- assert(a == 1);
本文基本是對http://www.puppetmastertrading.com/images/hwViewForSwHackers.pdf的理解與翻譯。
MESI緩存一致性協議,能保證緩存和內存數據一致
volatile表示不使用寄存器的值,每次都從內存讀(不包括緩存)
dma越過cpu修改內存,會影響MESI
補充MESI:
緩存一致性協議給緩存行(通常為64字節)定義了個狀態:獨占(exclusive)、共享(share)、修改(modified)、失效(invalid),用來描述該緩存行是否被多處理器共享、是否修改。所以緩存一致性協議也稱MESI協議。
- 獨占(exclusive):僅當前處理器擁有該緩存行,并且沒有修改過,是最新的值。
- 共享(share):有多個處理器擁有該緩存行,每個處理器都沒有修改過緩存,是最新的值。
- 修改(modified):僅當前處理器擁有該緩存行,并且緩存行被修改過了,一定時間內會寫回主存,會寫成功狀態會變為S。
- 失效(invalid):緩存行被其他處理器修改過,該值不是最新的值,需要讀取主存上最新的值。
- 協議協作如下:
- 一個處于M狀態的緩存行,必須時刻監聽所有試圖讀取該緩存行對應的主存地址的操作,如果監聽到,則必須在此操作執行前把其緩存行中的數據寫回CPU。
- 一個處于S狀態的緩存行,必須時刻監聽使該緩存行無效或者獨享該緩存行的請求,如果監聽到,則必須把其緩存行狀態設置為I。
- 一個處于E狀態的緩存行,必須時刻監聽其他試圖讀取該緩存行對應的主存地址的操作,如果監聽到,則必須把其緩存行狀態設置為S。
- 當CPU需要讀取數據時,如果其緩存行的狀態是I的,則需要從內存中讀取,并把自己狀態變成S,如果不是I,則可以直接讀取緩存中的值,但在此之前,必須要等待其他CPU的監聽結果,如其他CPU也有該數據的緩存且狀態是M,則需要等待其把緩存更新到內存之后,再讀取。
- 當CPU需要寫數據時,只有在其緩存行是M或者E的時候才能執行,否則需要發出特殊的RFO指令(Read Or Ownership,這是一種總線事務),通知其他CPU置緩存無效(I),這種情況下會性能開銷是相對較大的。在寫入完成后,修改其緩存狀態為M。
另外MESI協議為了提高性能,引入了Store Buffe和Invalidate Queues,還是有可能會引起緩存不一致,還會再引入內存屏障來確保一致性
存儲緩存(Store Buffe)
也就是常說的寫緩存,當處理器修改緩存時,把新值放到存儲緩存中,處理器就可以去干別的事了,把剩下的事交給存儲緩存。
失效隊列(Invalidate Queues)
處理失效的緩存也不是簡單的,需要讀取主存。并且存儲緩存也不是無限大的,那么當存儲緩存滿的時候,處理器還是要等待失效響應的。為了解決上面兩個問題,引進了失效隊列(invalidate queue)。處理失效的工作如下:
- 收到失效消息時,放到失效隊列中去。
- 為了不讓處理器久等失效響應,收到失效消息需要馬上回復失效響應。
- 為了不頻繁阻塞處理器,不會馬上讀主存以及設置緩存為invlid,合適的時候再一塊處理失效隊列。
MESI和CAS關系
在x86架構上,CAS被翻譯為”lock cmpxchg...“,當兩個core同時執行針對同一地址的CAS指令時,其實他們是在試圖修改每個core自己持有的Cache line,
假設兩個core都持有相同地址對應cacheline,且各自cacheline 狀態為S, 這時如果要想成功修改,就首先需要把S轉為E或者M, 則需要向其它core invalidate 這個地址的cacheline,則兩個core都會向ring bus發出 invalidate這個操作, 那么在ringbus上就會根據特定的設計協議仲裁是core0,還是core1能贏得這個invalidate, 勝者完成操作, 失敗者需要接受結果, invalidate自己對應的cacheline,再讀取勝者修改后的值, 回到起點.。
對于我們的CAS操作來說, 其實鎖并沒有消失,只是轉嫁到了ring bus的總線仲裁協議中. 而且大量的多核同時針對一個地址的CAS操作會引起反復的互相invalidate 同一cacheline, 造成pingpong效應, 同樣會降低性能(參考[9])。當然如果真的有性能問題,我覺得這可能會在ns級別體現了,一般的應用程序中使用CAS應該不會引起性能問題。

















