大規模線上應用TiDB會遇到的坑,本文都幫你排除好了
今天主要和大家分享以下內容:
- 轉轉引入 TiDB 主要解決什么問題;
- 大規模線上應用遇到的問題;
- TiDB 集群標準化和未來展望。
下面都是轉轉應用 TiDB 時的一些經驗,供大家參考。
轉轉引入TiDB主要解決什么問題
轉轉引入 TiDB 首先解決了分庫分表的問題。某些場景不便于分庫分表, 分庫分表會使業務層開發邏輯變得越來越復雜,不利于降本增效的方向。其次解決了海量數據存儲的問題。單機容量有瓶頸,會影響最終集群的效果。

大規模線上應用遇到的問題
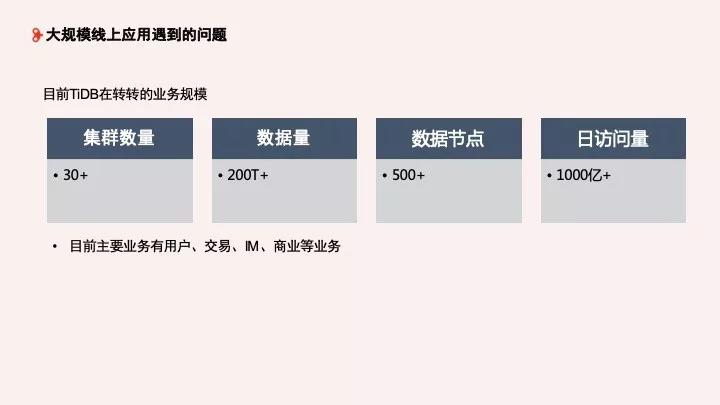
轉轉在 2018 年就開始調研 TiDB,從 1.0 到 3.0。目前集群數量 30+/數據量200T+/數據節點/500+/日訪問量 1000 億+,主要承載用戶、交易、IM、商業等業務。
1、性能問題定位
隨著業務的擴展,集群數量的增加,維護成本也會相應增加。我們首先遇到的第一個問題,也是我們經常會遇到的問題就是性能問題的定位。
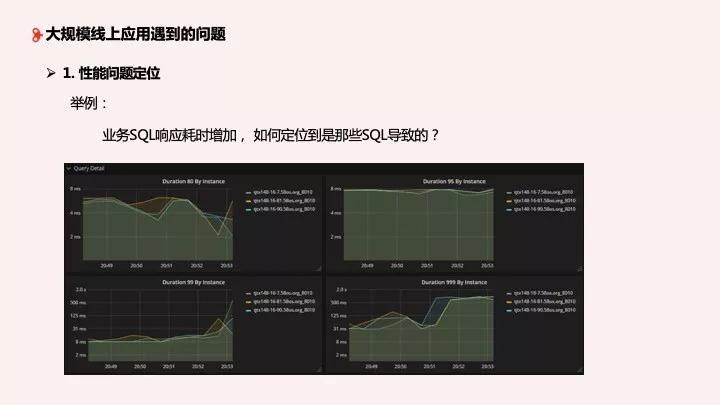
業務 SQL 響應耗時突然增加了,如何定位是哪些 SQL 導致的?下面這圖大家在使用 TiDB 時會經常見到,可以明顯看到某一時刻集群的響應延遲變慢了,業務也想要知道為什么變慢了,這時候我們就要定位問題。

通常我們要打開 TiDB 監控平臺看一些指標:Query 的指標、事務的指標等,看完之后我們再看 TiDB 日志,監控過濾關鍵字后再結合上下文去了解 TiDB 發生了什么情況。最后去看 TiKV 的日志,通過關鍵字分析后基本上能夠定位出來問題了。
如果維護的集群只是一套或兩套,沒有問題。但是當集群增加到上十套或上百套,節點相應增加時,我們怎么定位問題?
2、集群管理
接下來是集群管理。運維單套集群時沒有問題,但是管理多套集群時會遇到例如集群部署、集群版本升級、配置不兼容等問題。

簡單細說一下,比如說在集群部署時,PD 在 Systemd 下會有問題,因為每臺機器只支持一個 PD,可以通過 supervise解決,但是在起停時容易失敗。版本升級時,早期兩星期升一次級,和官方同步,但后來跟不上了,所以我們就會選擇一個版本停下來,然后觀望。
在版本升級的時候,我們遇到的問題是配置不一樣,小版本也不一樣,由于我們做了一些自定義的配置,可能在這個版本就不生效了,導致升級時出問題、報錯。因為都是線上的集群,每次成本都很高。整體來說,集群管理難度增加,每次升級版本的體驗都不太友好。
3、日志規范不統一
第三個問題:日志規范不統一。這個問題對于剛剛使用 TiDB 的用戶來說感受可能不太深,但其實1.0 的日志和 2.0 的日志是不一樣的。比如說慢日志這個日志格式,2.1 版本的關鍵字變化和 2.0 版本不兼容。這個對于我們運維人員來說成本很高。慢日志格式從 2.1.8 之后徹底變成 MySQL 形式,上下版本不太兼容,線上目前是多版本并存,所以極大地增加了日志處理的難度。

4、慢 SQL 對集群整體穩定性的影響
第四個問題:慢 SQL 對集群整體穩定性的影響。對于日常來說,線上復雜統計 SQL,大數據的 ETL 需求,以及數據臨時抽取需求都很正常,但是直接在線上操作時有可能會導致整個集群響應延時變慢,最終影響整個業務的響應延時。

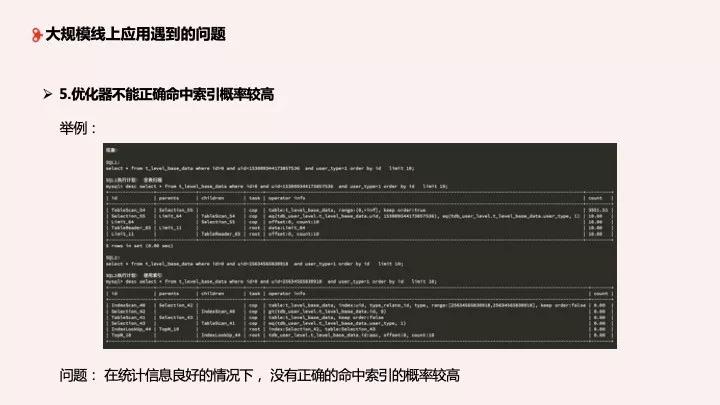
5、優化器不能正確命中索引概率較高
第五個問題:優化器不能正確命中索引概率較高,這個問題業務經常遇到。我的 SQL 一模一樣,一個兩秒,一個幾十毫秒,怎么解釋?比如說,在我們開啟了統計信息自動統計、表的統計信息相對良好的情況下,兩個一樣的 SQL,一個走了索引,一個走了全程掃描,執行計劃不一樣。為什么在統計信息相對良好的情況下索引正確命中概率不高?大家可以先思考一下。

6、事務沖突會導致集群性能嚴重下降
第六個問題:事務沖突會導致集群性能嚴重下降。例如圖中的這個問題 SQL,執行時有一個并發更新的場景,在 TiDB retry_limite = 3 的情況下會嚴重影響集群性能。可以看到當 retry 出現時,整體鎖的狀態比較高,響應延時也相應增加。


TiDB集群標準化
剛剛我們整理了比較有代表性的六個問題,相信大家也有過思考。轉轉通過 TiDB 的標準化來解決:集群部署、信息收集、監控告警和業務上線中遇到的問題。
1、集群部署標準化
在集群部署標準化方面,轉轉至少部署 3 個以上的 TiDB Server,用于 TiDB 高可用,為數據提供穩定的接入,需要萬兆網卡和機械磁盤。其次需要 3 個 PD Server, 千兆或萬兆網卡都可以,機械磁盤。最后至少 6 個 TiKV Server,單獨 TiKV 容量不超過 400GB,但這也因企業的使用而異,最好使用固態硬盤。
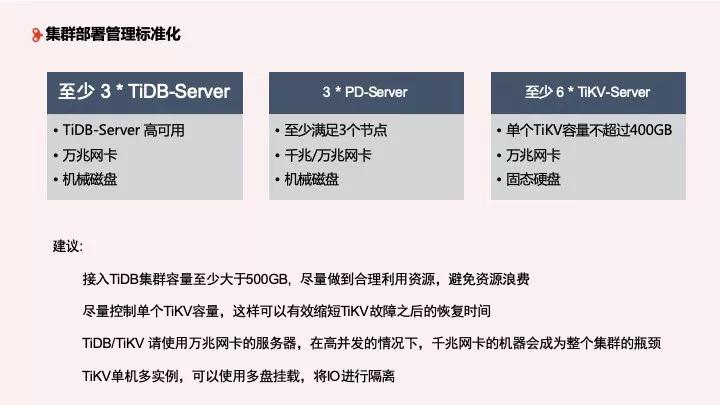
對于部署管理的建議:
- 作為 MySQL 應用場景的補充,我們不建議接入 TiDB 的容量特別少,建議至少大于 500GB,避免浪費資源;
- 單獨 TiKV 容量不超過 400GB,這可以有效縮短 TiKV 故障之后的恢復時間;
- TiDB/TiKV 在高并發下千兆網卡會成為容量瓶頸,請使用萬兆網卡;
- TiKV 單機多實例,可以使用多盤掛載,將 IO 進行隔離,目前應用效果較好。
2、信息收集
接下來是信息收集的標準化。我們一直和官方吐槽日志能不能固定下來,一路從 1.0 追到 3.0,算是資深老用戶。對于新上 TiDB 的用戶,建議使用 2.1.8 之后的版本,日志相對穩定,做日志的 ETL 也相對容易。官方會在未來的版本中將格式固定下來,這對社區來說是一件非常好的事情。

目前對于轉轉來說,經過我們的規范,主要問題還是在 TiDB 的慢查詢這塊,我們針對慢查詢開發了對應的實時慢查詢視圖,方便業務 RD 觀察集群慢查詢信息。目前主要通過 Flume 進行日志采集,最終通過平臺進行統一處理、展示和告警。
3、監控告警
下面是告警監控標準化。TiDB 的原生報警有很多種告警和監控,轉轉做了梳理,確保每次告警都能起到預警的效果,并且有意義,但不一定每次告警都需要人工干預。如果每天都在收報警,會產生疲勞,大家就不看了,所以我們希望做到告警收斂。

還有就是告警做了簡化,做定制,讓收到的人更容易理解信息。業務 RD 根本看不懂 TiDB 的原生報警,他們只想知道出了什么問題,所以我們做了處理。
最后就是監控簡化,通過掃描關鍵指標獲取集群瞬時狀態,這個目前還在和 TiDB 的同學一起做這個事情,希望能夠兼容多個版本可以獲取到集群的瞬時值,以便快速了解到集群問題、狀態,定位大方向故障。
4、業務上線
最后是業務上線標準化 。

第一是 SQL 優化,表結構、索引及列表全部優化。DBA 要全程參與業務上線,包括建表、SQL List,審視表結構和 SQL,也就是我們每次要上線 TiDB 集群時,都要和業務去討論有些地方可能有問題。SQL 要全部使用 Force Index,用于解決優化器不能正確命中索引概率高的問題。3.0 GA 中包含 SQL Plan Management,目前雖然是實驗特性,但是大家可以測一下,這個是美團和 TiDB 一起聯合開發的功能。然后響應延時我們要求比較高,99.9% 控制在 100 ms 以下,99% 控制在 10 ms 以下才能上線,能解決一些常規的響應延時。接下來就是 TiDB Explain, DBA 需要熟練掌握,并且將如何解讀其中的內容告訴開發后才能上線。
第二是業務邏輯。在已有的業務場景下,并發更新同一條記錄的情況下會觸發 TiDB retry,在當前的事務模型(樂觀鎖)下表現并不好,怎么解決?我們使用的是轉轉自研的分布式鎖 ZZLock,即將樂觀鎖加一個分布式鎖來模擬悲觀鎖,這樣對業務響應延時沒有問題,可以將沖突時間降到比較平穩的時間。
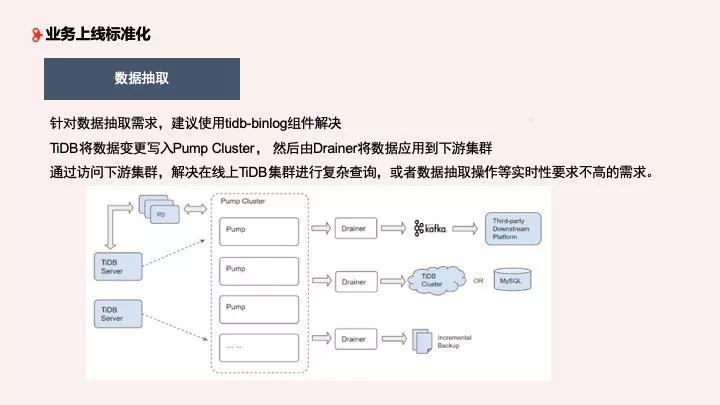
第三是數據抽取,這是非常普遍的需求,我們使用了 binlog 這個組件,將 tidb-server 變更數據寫到 Pump Cluster,然后 Drainer 將數據應用到下游集群,通過訪問下游集群,解決在線上進行的復雜查詢、抽取等時效要求不高的需求。
TiDB未來規劃和展望
對于 TiDB 未來規劃和展望,整體來說還是圍繞降本增效這個主題,我們正在和 PingCAP 進行容器試點,接下來會將 TiDB 跑在云上面。

Q & A
Q1:轉轉現在最大的集群是什么場景下的,大概有幾個節點?訪問 QPS 峰值有多少,數據量有多大?
A:目前最大的集群是 IM 集群,有上百個節點,數據量上百億。整體來說 TiKV 集群比較多,整體響應不錯,SQL 都是基于主鍵查詢,業務方面做得很好。
Q2:當前線上版本分布情況是什么?為什么不都升級到2.1.8?
A:目前有 2.0、 2.0.5、2.1.7、2.1.8,主流版本是2.1.8。2.1.8以下版本還比較穩定,有升級規劃但是業務還沒有什么需求,所以想和業務一起升上去。如果 3.0 測試效果較好,會考慮直接升級到 3.0。
Q3:一個集群有多個 DB,還是只有一個 DB?隔離怎么考慮?
A:一個集群只有一個 DB。