大數據公司又被查,爬蟲程序員在內20余人被抓!
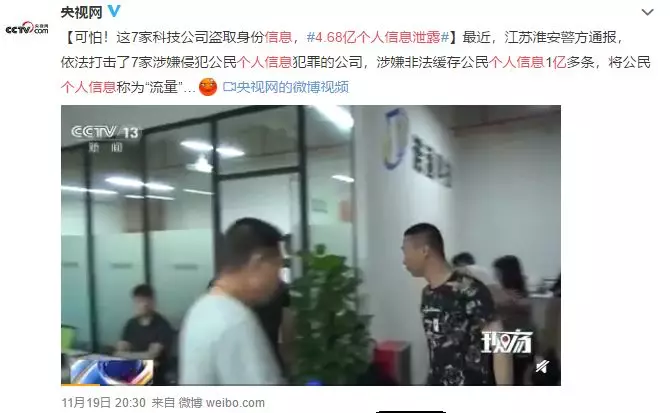
近日江蘇淮安警方依法打擊了 7 家涉嫌侵犯公民個人信息犯罪的公司,涉嫌非法緩存公民個人信息 1 億多條。
其中,拉卡拉支付旗下的考拉征信涉嫌非法提供身份證返照查詢 9800 多萬次,獲利 3800 萬元。
警方已將考拉征信服務有限公司及北京黑格公司的法定代表人、董事長、銷售、技術等 20 余名涉案人員抓獲。
01.“爬蟲”軟件“爬出”的犯罪鏈條
警方發現,涉案的廣州諾涵公司雖然披著科技公司的外衣,其實從事的是網絡放貸、軟暴力催收、販賣公民個人信息等違法犯罪行為。
在他們販賣的公民個人信息里,甚至還出現了公民身份證照片信息,這樣極度隱私的個人信息他們從哪兒獲取的呢?

警方發現,在廣州諾涵科技公司,公民個人信息被稱為“流量”,公司自己開發有“樂花管家”等多個小貸平臺,在自身購買公民個人信息用于推銷貸款、軟暴力催收的同時,也和其他公司相互交換公民個人信息,還開發有爬蟲云等軟件,通過技術手段爬取其他小貸公司的公民個人信息,用于公司放貸和非法出售牟利。

鎖定相關犯罪證據后,淮安警方在長沙、深圳分別將湖南九象公司的法定代表人和技術主管抓獲。
審訊得知,九象公司黑爬蟲網站的“身份核驗返照”業務端口來自北京黑格科技有限公司,而黑格公司是從北京考拉征信服務有限公司等四家公司購買的查詢接口。
隨即,警方將北京黑格公司和考拉征信服務有限公司的法定代表人、董事長、銷售、技術等 20 余名涉案人員抓獲,并于今年 4 月在北京將他們上游公司的 5 名涉案人員抓獲。
經查,北京考拉征信服務有限公司從上游公司獲取接口后又違規將查詢接口出賣,并非法緩存公民個人身份信息,供下游公司查詢牟利,從而造成公民身份信息包括身份證照片的大量泄露。
違規緩存相當于把公民個人信息復制了一份,存在那邊,下游公司再向它通過數據接口調取數據的時候,它就不需要再向上游調取,也是節省了開支,這個是違法的。

經查,2015 年 3 月以來,北京考拉公司非法提供查詢返照 9800 余萬次,獲利 3800 余萬元,在公司服務器中查獲并收繳被非法獲取、存儲的公民姓名、身份證號、相片近 1 億條。
02.我只是個寫爬蟲的,跟我有什么關系?
許多程序員都有這樣的想法,技術是無罪的,我只是個打工的程序員,公司干違法的業務,跟我沒關系。。。只能說,程序猿們真是圖羊圖森破了。
我們先來看幾個真實的法院判決案例:
案例一:數據擁有者有證據能夠舉證你的數據是抓取來的。如下,今日頭條對起訴上海晟品法院宣判結果。

(圖片文字來自中國判決文書網)
從文書描述來看,修改UA、修改device id、繞開網站訪問頻率控制這是寫爬蟲的基本,這些技術手法反而成了獲罪的依據。
案例二:抓取用戶社交數據,尤其是用戶隱私相關。

(圖片文字來自新浪網)
案例三:用爬蟲技術擾亂對方網站經營規則,且牟利。比如這個:

(圖片文字來自中國永嘉公號)
圖上描述做搜索引擎排名的技術,其實就是利用爬蟲技術規模化的訪問網頁。
在我們通常的認知里,因為互聯網推崇分享精神,所以認為只要是網絡公開數據就可以抓取,但是通過上面的案例來看,有幾個禁忌,抓取的數據最好不要直接商用,涉及社交信息/用戶信息要謹慎。
老板交代你抓取敏感任務時,讓老板先看下刑法第285條。公司從事違法業務,不代表個人行為就沒事,只是還沒入有關部門的法眼。
03.程序員如何避免,面向監獄編程?
爬哪些數據會觸犯法律?
第一、著作權法保護的所有作品數據
比如一些網站發表的內容,如文章、評論等都是有著作權的,如果只是單純的通過瀏覽器查看是不會觸犯法律的。
但是,對于有著作權的作品,如果未經著作權人許可,以盈利為目的,對其作品用任何手段進行復制是犯法的。
如果是使用了爬蟲技術手段爬取數據之后將其保存下來或者傳播,并且進行盈利,這種都是屬于犯罪的。
第二、網站用戶的個人信息或者隱私信息
網站上的個人用戶的個人信息,即使是用戶自己放到一些網站上進行公開或者部分公開,如微博、微信等,不代表這些數據就可以被其他人隨便獲取,這個要特別注意。
所以,如果爬取的數據涉及到個人信息或隱私信息,都是違法的!
還有些爬蟲企圖繞過權限校驗等,爬取用戶未公開的信息,如個人私密相冊照片等,都是屬于侵犯用戶的個人隱私的,不要覺得自己技術玩得溜,這些可都是違法行為。
第三、反不正當競爭法中明確保護的數據
許多網站中的數據系由用戶生成,且該等數據和內容系原告網站的主要競爭力來源。如“XX點評”、“X團”上面的店鋪評價、評論等信息,“X程網”上面的關于酒店的評價評論等信息等。
那么,未經允許,爬取其他網站的核心數據,很明顯并沒有遵守《反不正當競爭法》中規定的自愿、平等、公平、誠實信用的原則。
在“XX點評”訴“X度”不正當競爭案件、以及“X浪微博”訴“X脈脈”不正當競爭等案件中,法院都認定被告未經許可抓取、使用原告網站中的數據的行為,違反了誠實信用原則及公認的道德,損害了互聯網的市場競爭秩序,損害了原告的競爭優勢,從而構成不正當競爭。
因此,如果抓取XX點評、X博、X瓣電影、X乎等UGC模式的網站上用戶發布的信息,并在自己的產品或者服務中發布、使用該等信息,則有較大的風險構成不正當競爭。
怎么爬數據算犯法?
如果是爬取公開的數據,通常不會被認為是侵權。Google、百度等搜索引擎都是這么爬取的。
那么,到底怎么爬數據是有可能觸犯法律的呢,主要考慮是否涉及以下兩種行為:
沒有遵守網站Robots協議
Robots協議是技術界為了解決爬取方和被爬取方之間通過計算機程序完成關于爬取的意愿溝通而產生的一種機制。
通過技術手段,繞過防護措施,抓取數據
由于爬蟲的批量訪問會給網站帶來巨大的壓力和負擔,因此許多網站經營者會采取技術手段,以阻止爬蟲批量獲取自己網站信息。
所以,很多爬蟲工具為了爬取數據,會想辦法通過各種手段繞過防護措施,但是,這種行為也是會觸犯法律的。
抓回來的數據怎么用會犯法?
很多公司開發的爬蟲遵守了Robots協議,也沒有爬取不該爬取的數據,難道這樣獲取到的數據就可以隨便使用了嗎?其實也不是,如果使用不當,也會觸犯法律的。
比如通過爬蟲抓取到的數據進行盈利、損害他人利益、造假、誹謗等都是可能觸犯法律的。
此外,未經被收集者同意,即使是將合法收集的公民個人信息向他人提供的,也屬于刑法第二百五十三條之一規定的“提供公民個人信息”,可能構成犯罪。
04.我們如何防止個人信息被泄露?
在科技飛速發展的今天,人們開始追求各種方便快捷的方式生活,但是,在方便快捷的背后,個人信息安全也不能忽視。瀏覽器、社交平臺等等都有可能出現隱私泄露。
個人隱私泄露有著很嚴重的安全隱患!如何防止個人信息泄露?快來看防范小妙招:
- 盡量不使用公共場所的 WiFi。
- 盡量訪問具備安全協議的網址。建議盡量登錄網址前綴中帶有“https:”字樣的網站,具備這種安全協議的網址的安全性較高。
- 不同軟件盡量不要使用同一組賬號密碼。
- 妥善處置快遞單等包含個人信息的單據。對于含有姓名、電話、住址等信息的單據憑證要及時銷毀,不經意扔掉也可能導致個人信息泄露。
- 身份證、戶口本等有個人信息的證件,一定要保存好。
- 手機、電腦等都需要安裝安全軟件,每天至少進行一次對木馬程序的掃描,尤其在使用重要賬號密碼前。每周定期進行一次病毒查殺,并及時更新安全軟件。
- 不少人熱衷于曬地點、曬自拍照,還有家長喜歡曬孩子照片等。這種手機簽到可能被別有用心的人盯上。可參考《21歲日本女星慘遭猥褻,只因自拍瞳孔倒影暴露住址?| 一張照片是怎么出賣你的!》
- 一方面暴露了個人隱私,比如姓名、工作單位、家庭住址等,另一方面可能招致犯罪,在網上使用手機簽到時,需要謹慎。