













2684億銷售額背后的阿里AI技術全景圖
剛剛結束的雙十一,天貓交易額達到 2684 億元,較去年同比增長 25.7%。這一結果背后,云計算、人工智能等技術以及阿里巴巴工程師們的努力功不可沒。在正在召開的 AICon 全球人工智能與機器學習技術大會 現場,阿里云智能計算平臺事業部研究員林偉介紹了阿里基于飛天 AI 平臺的人工智能技術及能力,揭開雙 11 大規模交易場景下,阿里人工智能技術的神秘面紗。

人工智能生態發展趨勢
大家好,我是林偉,我今天演講的主題是《AI 突破無限可能—5 億消費者的云上雙 11》。我本人是做系統出身的,但在最近的一些會議上發現,越來越多做系統出身的人開始研究 AI。在 90 年代末的那波熱潮里,我有幸在學校的人工智能實驗室呆過,那時還在糾結模型效果,最后發現是自己想多了,那時做出來的東西還遠遠達不到可用的狀態。在后來的一段時間內,AI 進入沉寂,最近幾年又突然火爆,我在一些學校做交流的時候發現很多同學都在研究 AI 算法,但其實神經網絡、遺傳算法和模擬算法很多年前就已經出現,最近幾年才爆發的最主要原因是數據和算力的提升。
在這之中,云計算也起到了很大作用,只有算力更加充足,才可以擬合出更加有效的模型,這也是阿里巴巴 2009 年堅定投入云計算的重要原因。說到阿里云,其實阿里云有個非常大的客戶就是阿里巴巴自己的電商業務,而阿里電商全年最重要的一個活動就是雙 11。
過去幾年,阿里雙 11 的營業額逐漸升高,這背后更深層次的原因其實是我們實現了核心系統的 100% 上云。上云之后,我們發現 AI 離不開計算,只有具備強大的計算力才可以利用 AI 技術提高效率,雙 11 就是一個很好的練兵場。在這樣的規模下,如何構造系統、處理數據以及迅速挖掘數據背后的價值是我們在思考的問題。
在整個大趨勢下面,我們可以看到三個因素:
一是實時化。 雙 11 就一天,我們必須理解數據并及時反饋給商家,實時性非常重要,雙 11 大屏背后的支撐系統就是通過 Flink 實現實時計算。單純的銷售額可能沒有特別大的意義,我們需要進行實時分析以得到更細致的指標,比如用戶的購買興趣、商品類別、供銷比、渠道、倉儲位置和貨源等,我們需要通過實時分析及時反饋給商家、快遞公司等,讓各方都可以明確如何調整雙 11 當天的策略。今年雙 11,我們每秒可以處理 25.5 億條消息,包括買賣消息、快遞請求等。

二是規模性。 我們不僅需要實時反饋,雙 11 結束還需要精細對賬給銀行和商家。今年,我們僅花費一天時間(也就是 11 月 12 日)就完成了所有報表匯報,這就是通過云平臺的彈性來實現的。在這么大的規模下,商家服務效率也是一個問題,原來就是靠人,用電話和小二來服務商家,現在這樣的規模體系下就需要用 AI 技術來服務商家,并通過 AI 輔助快遞配送,比如機器人可能會詢問用戶:在不在家?包裹放在哪里等問題。在大家以往的印象中,AI 離生活很遠,但輔助快遞配送就是一個很具體的場景,可以為用戶帶來更好的體驗,包括淘寶首頁的個性化推薦等。
如今,淘寶推薦也會有一些動態封面,這背后是我們一天分析了 2.5 億個視頻的結果,現在的淘寶上也有很多用短視頻賣貨宣傳的,我們分析了 2.5 億視頻,最后日均商品分析達到 15000 萬。我們統計了當天通過視頻購買商品的人,發現平均有效時長是 120 秒。通過這種新技術可以促進新的場景。
三是 AI。 這一切的背后是數據的力量,整個雙 11 都是 AI 和數據在驅動。實時性、規模性和 AI 三者相輔相成讓雙 11 的效率得到了大幅提高,計算處理能力也有了很大提高,這就是 2684 億銷售額背后的技術力量。
云上雙 11 的 AI 能力
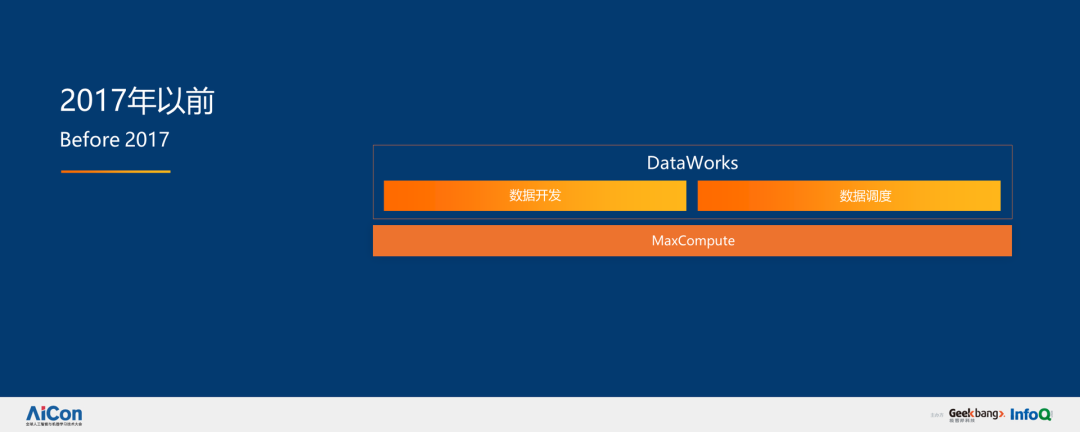
回歸技術本身。2017 年以前,我們的系統是比較簡單的,更多的任務是處理數據和生成報表。一年半以前,我們開始加入更多實時性,用實時數據反饋商業決策,這就有了 MaxCompute 的出現。

如今,整個技術后臺非常復雜,我們有非常好的一些計算引擎,可以進行全域數據集成,具備統一的源數據管理、任務管理,智能數據開發和數據合成治理等能力。
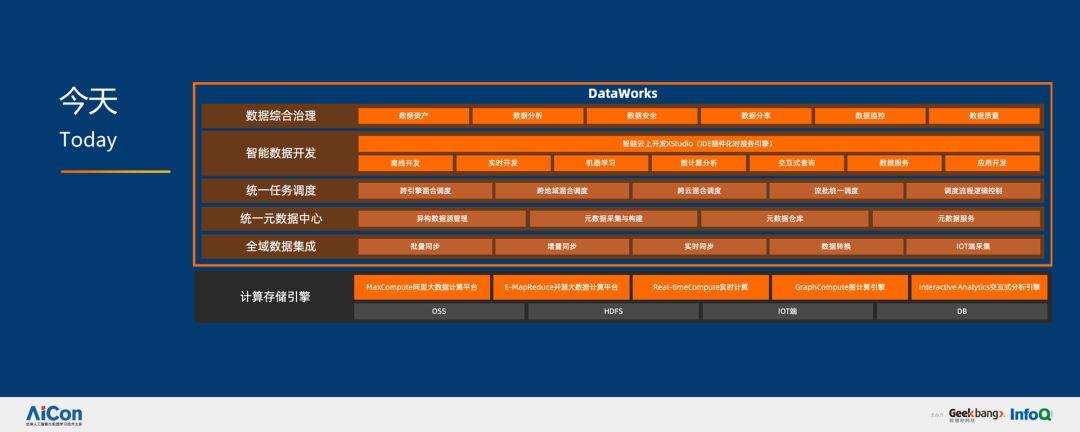
說到底,AI 和計算其實是共生體,AI 的繁榮依賴于計算力的積累,所以我們需要很好的數據處理平臺進行分析和提取,服務好算法工程師進行創新,比如嘗試各種各樣的模型、各種各樣構造機器學習的方式,看看能否提高人工智能的效率和準確度。
企業如何構建云上 AI 能力
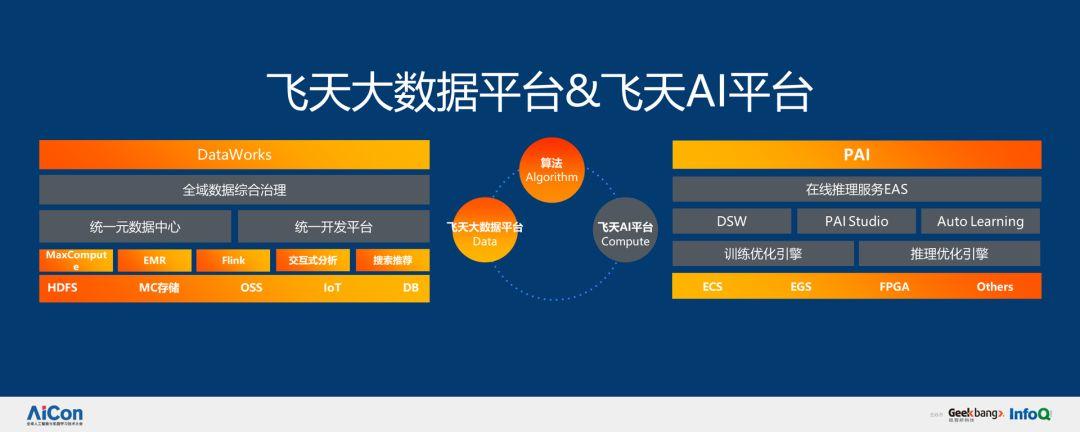
上述這些主要是 AI 的場景,接下來,我會著重介紹這些場景背后的 AI 技術,主要圍繞飛天 AI 平臺,上層是 PAI 和在線推理服務 EAS,然后分為 DSW 開發平臺,PAI Studio 和 Auto Learning 三部分,基于訓練優化引擎和推理優化引擎,解決大規模分布式數據處理問題。
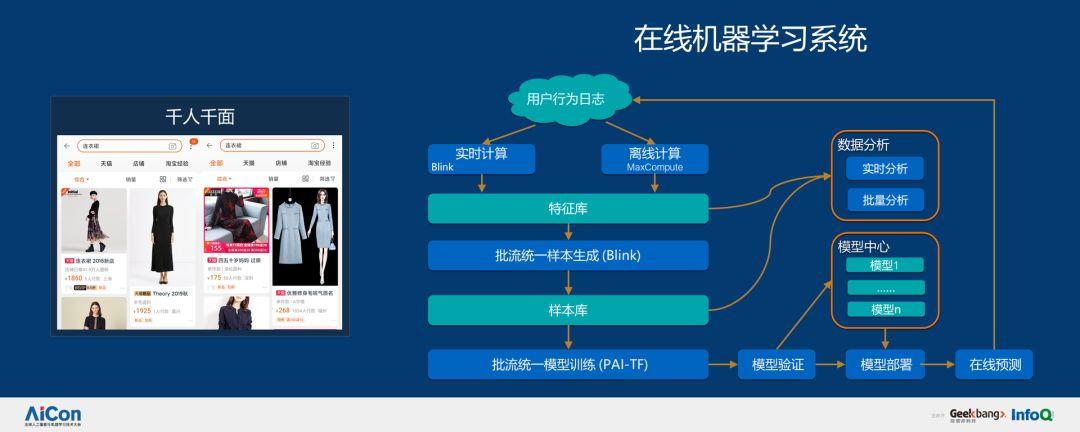
此外,我們還有在線機器學習系統,可以對用戶行為日志進行實時和離線計算,然后抽取特征庫,生成批流統一樣本,進入樣本庫,最終進行批流統一模型訓練。為什么我們要做這個?一是因為實時性,傳統的搜索是非常不敏感的,而我們是在遵循用戶興趣的變化,如果兩周更新一次模型可能已經錯過了幾輪熱銷商品,我們需要通過在線機器學習的方式進行實時判斷,這非常接近于深度學習。在非實時的狀態下,工程師可以非常精細的做特征工程,花更多的時間理解數據,利用深度學習本身的特性捕獲數據之間的關系,而不是靠專家提取,這是深度學習的好處,但這需要海量的計算才可以完成,而在線機器學習系統會把雙 11 當天的日志及時傳遞到實時計算平臺做集合,然后通過分析按照 ID 對數據進行聚合形成樣本,最后根據樣本做增量學習、驗證、部署,只有這樣才能快速更新模型,使其遵循用戶或者商業的變化。
在這個過程中,我們面臨的第二個挑戰是模型非常大,因為要“千人千面”,因此需要一個非常大且針對稀疏場景的分布式訓練。目前的開源機器學習框架還遠遠達不到我們的規模要求,我們需要進行大量的優化,以便在稀疏場景下訓練大規模數據。如果對深度學習有了解,就應該知道深度學習可以描述非常大的細粒度圖,在圖上如何進行切割讓圖的計算和通訊可以更好地平衡是需要考慮的問題。
通過通信算子融合和基于通信代價的算子下推,我們實現了分布式圖優化技術。通過高效內存分配庫,比如 thread 庫、Share Nothing 執行框架;利用 Spares 特性的通訊;異步訓練,通訊和計算充分 overlap;容錯、partial checkpoint、autoscale、動態 embedding;支持大規模梯度 optimizer 的方法實現運行框架的優化,如下圖所示:
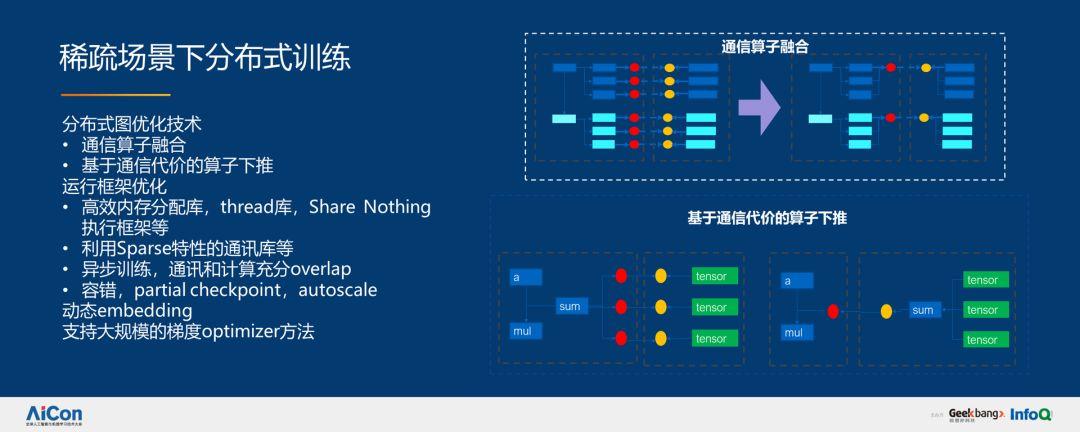
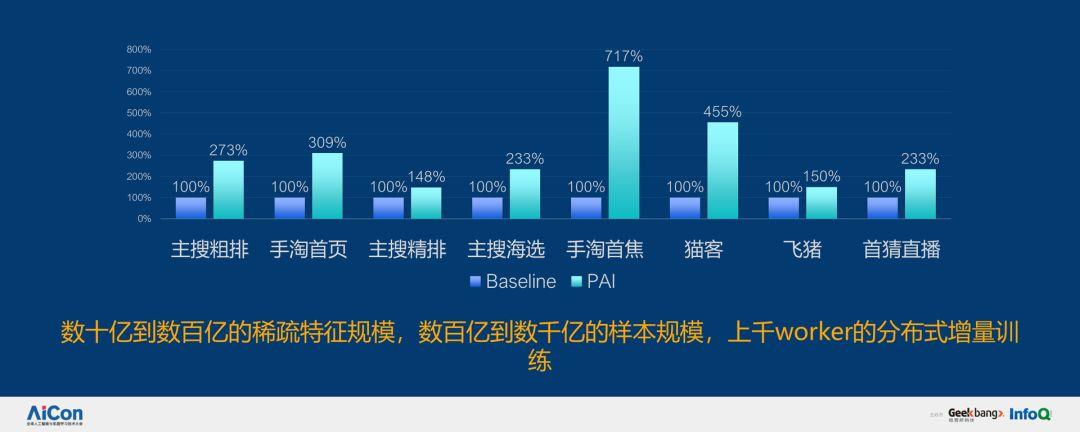
優化之后,性能上達到了七倍提升。稀疏特征規模從數十億到數百億,樣本從數百億到上千億,同時還有上千億 worker 的分布式增量訓練。
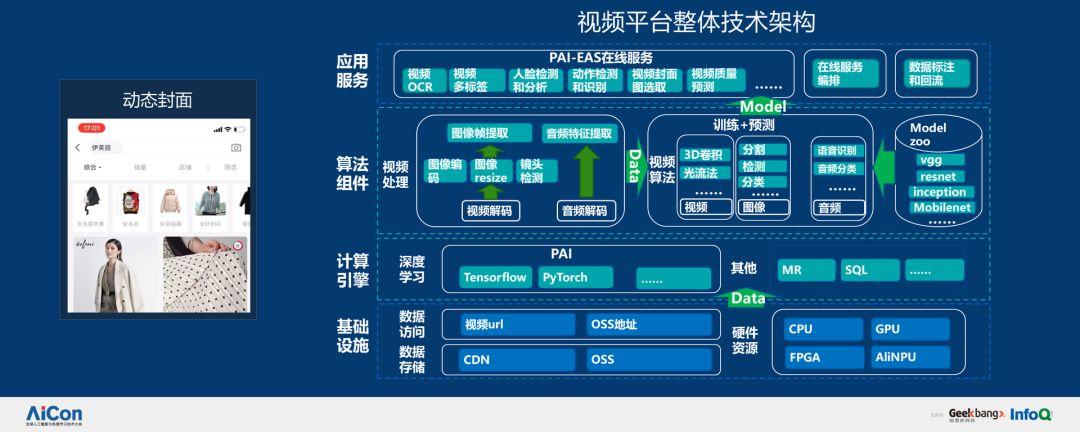
在動態封面層面,我們分析了大量視頻文件,視頻比圖片更復雜,因為視頻牽涉的環節非常多,需要做視頻的預處理,提取視頻幀,但不可能每一幀都進行提取,這樣做的代價實在是太大了,需要提取視頻的關鍵幀,通過圖片識別和目標檢測提取,這是很復雜的工作。因此,我們研發了視頻平臺,幫助視頻分析和算法工程師解決問題,具體架構如下圖所示:
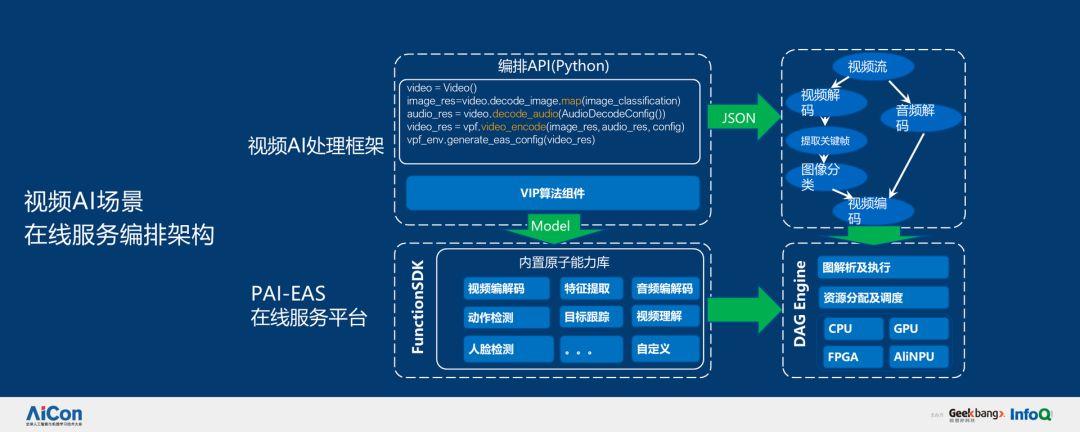
在視頻里面,在線服務其實也很復雜,有分解,也有合成。首先對視頻進行分解,然后加以理解并提取,最后進行合成。通過視頻 PAI-EAS 在線服務平臺,算法工程師只需要編寫簡單的 Python 代碼就可以通過接口調用相應服務,讓他們有更多的時間進行創新。
除了上述場景,整個平臺最重要的就是支持算法工程師的海量創新。五年以前,阿里的算法模型非常寶貴,寫算法的人不是特別多。隨著深度學習的演進,現在越來越多的算法工程師在構造模型。為了支撐這些需求,我們進行了 AI 自動化,讓算法建模同學專注業務建模本身,由系統將基礎設施(PAI)完成業務模型的高效、高性能運行執行。
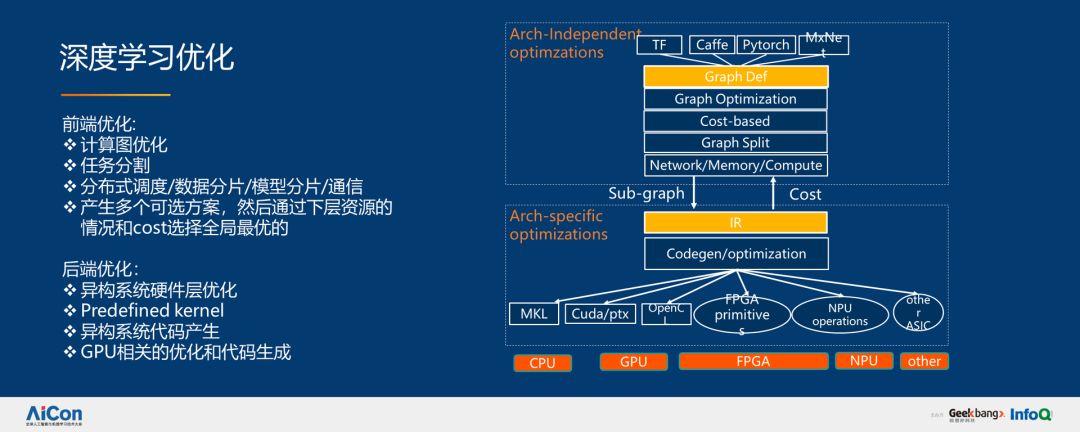
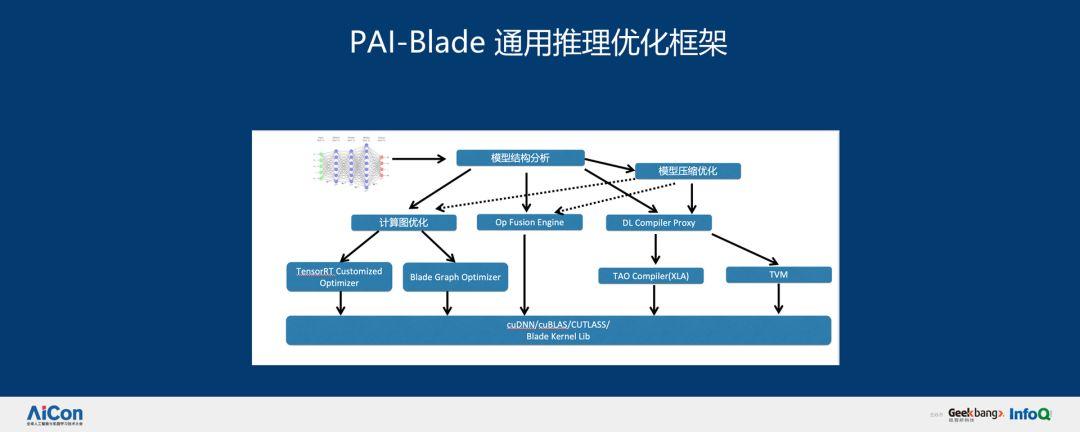
在深度學習方面,我們分別進行了前端和后端優化。我們希望通過編譯技術,系統技術服務實現圖優化、任務分割、分布式調度、數據分片、模型分片,通過系統模型選擇我們認為最好的方案執行,這是我們整個平臺做 PAI 的理念。整個 PAI-Blade 通用推理優化框架分為如下幾部分:
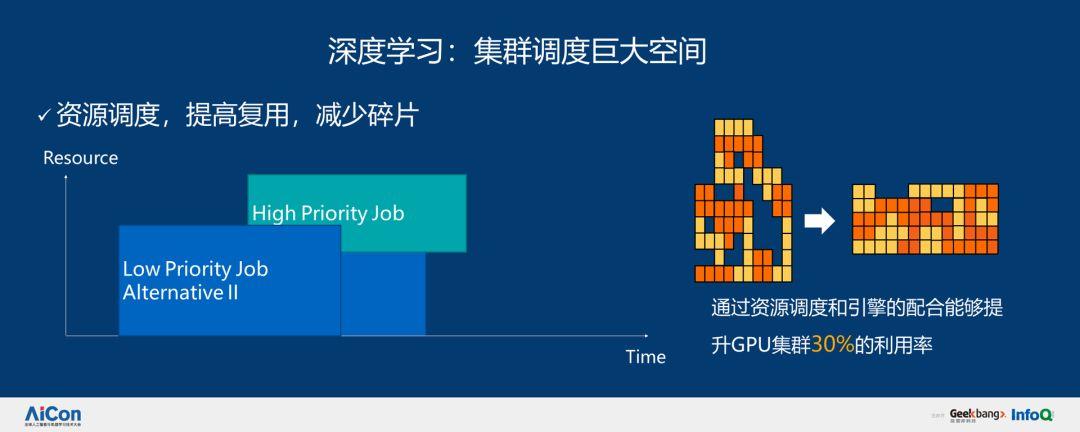
通過系列改進,我們也取得了一些優化成果。我們有一個非常大的集群,在集群足夠大的時候,我們就可以很好地實現復用。通過資源調度和引擎的配合能夠提升 GPU 集群 30% 的利用率。
此外,我們很多 AI 服務都加載在線服務框架,我們叫做 PAI EAS,這個框架是云原生的,可以更好地利用云平臺本身的規模性和可擴展性,撐住雙 11 當天的海量 AI 請求。因為雙 11 不僅是商業數據、購買數據在暴漲,AI 請求也在暴漲,比如智能客服、菜鳥語音當天的服務量都非常大,通過利用云平臺的能力,我們可以提供更好的體驗。

綜上,這些技術支撐了阿里巴巴的所有 BU,支持單任務 5000+ 的分布式訓練,有數萬臺的機器,數千 AI 的服務,日均調用量可以達到上十萬的規模。最后,阿里雙 11 的成長和 AI 技術的成長以及數據的爆發密不可分。
嘉賓介紹:
林偉,阿里云智能計算平臺事業部研究員,十五年大數據超大規模分布式系統經驗,負責阿里巴巴大數據 MaxCompute 和機器學習 PAI 平臺整體設計和構架,推動 MaxCompute2.0,以及 PAI2.0、PAI3.0 的演進。加入阿里之前是微軟大數據 Cosmos/Scope 的核心成員,在微軟研究院做分布式系統方面的研究,分別致力于分布式 NoSQL 存儲系統 PacificA、分布式大規模批處理 Scope、調度系統 Apollo、流計算 StreamScope 以及 ScopeML 分布式機器學習的工作。在 ODSI、NSDI、SOSP、SIGMOD 等系統領域頂級會議發表十余篇論文。














