Text2Image:一種新的NLP思路
與計算機視覺相比,自然語言處理 (NLP) 一直被認為是一個難以攻克的難題。本文尋找到了一種新的 NLP 處理方式,探索將 NLP 與計算機視覺處理結合,將文本繪制成圖片。雖然目前的準確率還有待優化提高,但看起來很有應用前景。
問題點
長期以來,自然語言處理 (NLP) 一直被認為是一個難以攻克的難題,至少與計算機視覺相比是這樣。NLP 模型需要更長的運行時間,通常更難實現,并且需要更多的計算資源。另一方面,圖像識別模型的實現變得更加簡單,對 GPU 的負擔也更小。這讓我想到,我們可以把一個文本語料庫轉換成一個圖像嗎? 我們能把文本解釋成圖像嗎? 事實證明,答案是肯定的,并帶來了令人驚訝的結果!我們用這種方法來區分假新聞和真新聞。
在本文中,我們將詳細探討這種方法、結果、結論和接下來的改進。
簡 介
思路來源
將文本轉換為圖像的想法最初是受到 Gleb Esman 關于欺詐檢測的這篇文章的啟發。在這種方法中,他們將各種數據點,如鼠標移動的速度、方向、加速度等轉換成彩色圖像。然后在這些圖像上運行一個圖像識別模型,進而可以產生高度準確的結果。
數據
所有實驗使用的數據是 George Mclntire 的假新聞數據集的子集。它包含大約 1000 篇假新聞和真實新聞的文章: https://github.com/cabhijith/Fake-News/blob/master/fake_or_real_news.csv.zip
Text2Image 的基本原理
讓我們首先在一個較高的層次上討論 Text2Image。其基本思想是將文本轉換成我們可以繪制的熱圖。熱圖標識著每個單詞的 TF-IDF 值。詞頻 - 逆文檔頻率 (TF-IDF) 是一種統計方法,用于確定一個單詞相對于文檔中其他單詞的重要性。在基本的預處理和計算 TF-IDF 值之后,我們使用一些平滑的高斯濾波將它們繪制成對數尺度的熱圖。一旦熱圖繪制完成,我們使用 fast.ai 實現了一個 CNN,并嘗試區分真實和虛假的熱圖。我們最終獲得了大約 71% 的穩定準確率,這對于這種新方法來說是一個很好的開始。這里有一個關于我們的方法的小流程圖:
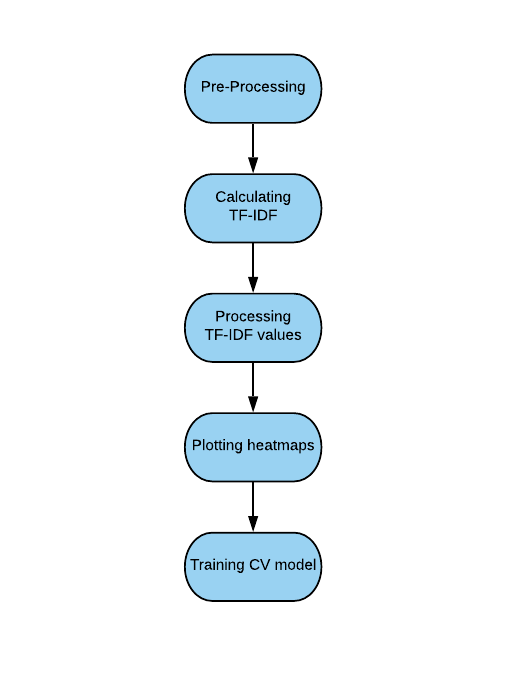
還不太清楚?繼續往下看。
Text2Image 詳述
預處理
數據采用小寫形式,刪除所有特殊字符,并將文本和標題連接起來。文件中 85% 以上的文字也被刪除。此外,要明確避免使用單詞列表 (stopwords)。使用的是一份標準的停頓詞列表,大部分是沒有信息的重復詞。特別是要對假新聞的斷句進行修改,這是未來值得探索的一個領域,特別是可以為假新聞帶來獨特的寫作風格。
計算 TF-IDF
為了對關鍵字進行評分和提取,Text2Image 使用了 tf-idf 的 scikit-learn 實現。對于假新聞語料庫和真實新聞語料庫,IDF 分別計算。與整個語料庫的單個 IDF 分數相比,計算單獨的 IDF 分數會導致準確性大幅提高。然后迭代計算每個文檔的 tf-idf 分數。在這里,標題和文本不是分開評分的,而是一起評分的。
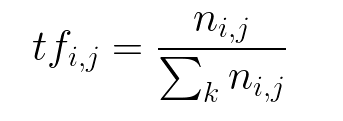
計算 Term 頻率
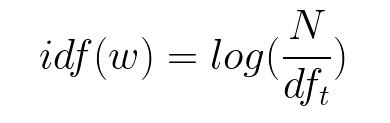
計算 IDF
把它們相乘,就得到 tf-idf。我們對每個文檔分別進行迭代。
處理 TF-IDF 值
對于每個文檔,將提取具有最高 TF-IDF 值的 121 個單詞。這些單詞然后用于創建一個 11x11 數組。在這里,選擇的單詞數量就像一個超參數。對于更短、更簡單的文本,可以使用更少的單詞,而使用更多的單詞來表示更長的、更復雜的文本。根據經驗,11x11 是這個數據集的理想大小。將 TF-IDF 值按大小降序排列,而不是按其在文本中的位置映射。TF-IDF 值以這種方式映射,因為它看起來更能代表文本,并且為模型提供了更豐富的特性來進行訓練。因為一個單詞可以在一篇文章中出現多次,所以要考慮第一次出現的單詞。
不按原樣繪制 TF-IDF 值,而是按對數刻度繪制所有值。這樣做是為了減少頂部和底部值之間的巨大差異。

在繪制時,由于這種差異,大多數熱圖不會顯示任何顏色的變化。因此,它們被繪制在一個對數刻度上,以便更好地找出差異。
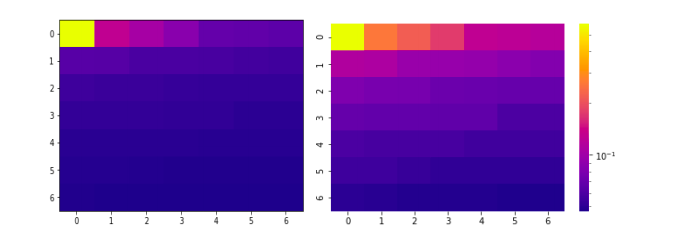
圖 1(左) 顯示了按原樣繪制的 TF-IDF 值。圖 2(右) 顯示了在對數刻度上繪制的相同值
缺點之一是在訓練模型時大量的過度擬合。這可以歸因于缺乏任何數據擴充,目前,似乎沒有數據擴充的方法可以用于這個用例。因此,在整個數據集上使用高斯濾波來平滑這些圖。雖然它確實降低了一點點準確性,但在過度擬合方面有顯著的下降,尤其是在訓練的初始階段。
最終的熱圖
最終的熱圖尺寸為 11x11,用 seaborn 繪制。因為 x 軸和 y 軸以及顏色條在訓練時都沒有傳達任何信息,所以我們刪除了它們。使用的熱圖類型是“等離子體”,因為它顯示了理想的顏色變化。嘗試不同的顏色組合可能是未來探索的一個領域。下面是最終情節的一個例子。
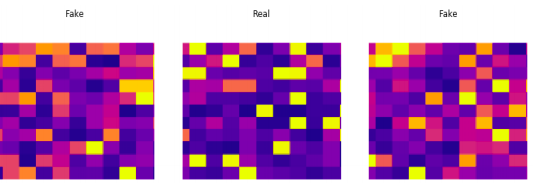
熱圖最終形態
訓練我們的模型
該模型使用 fast.ai 在 resnet34 上進行訓練。識別出假新聞 489 篇,真新聞 511 篇。在不增加數據的情況下,在訓練集和測試集之間采用標準的 80:20 分割。所有使用的代碼都可以在這里找到: https://github.com/cabhijith/Text2Image/blob/master/Code.html
結果
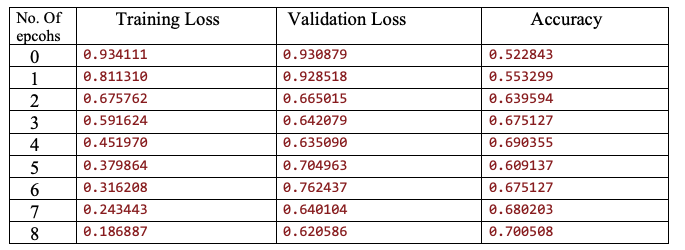
總 結
經過 9 輪迭代后,模型的準確率達到了 70% 以上。盡管對這個數據集來說還遠遠不夠先進,但這種新方法似乎很有前景。以下是在訓練過程中所做的一些觀察結果:
這個模型超差了很多。增加數據對過擬合沒有任何影響,這與我們的預期相反。進一步的訓練或改變學習率沒有任何效果。
增加繪圖大小有助于準確性提升直到大小為 11x11,之后增加繪圖大小會導致準確性下降。
在圖上使用一定數量的高斯濾波有助于提高精度。
下一步計劃
目前,我們正在致力于詞性標記和手套詞嵌入的可視化。我們也在考慮修改停止詞,修改繪圖的大小和顏色模式。我們將保持持續改進!