Python的小數(shù)據(jù)存儲(chǔ),用什么格式更有逼格?
小數(shù)據(jù)存儲(chǔ)
我們?cè)诰帉?xiě)代碼的時(shí)候,經(jīng)常會(huì)涉及到數(shù)據(jù)存儲(chǔ)的情況,如果是爬蟲(chóng)得到的大數(shù)據(jù),我們會(huì)選擇使用數(shù)據(jù)庫(kù),或者excel存儲(chǔ)。但如果只是一些小數(shù)據(jù),或者說(shuō)關(guān)聯(lián)性較強(qiáng)且存在存儲(chǔ)后復(fù)用的數(shù)據(jù),我們?cè)撊绾未鎯?chǔ)呢?
使用open保存文本
最簡(jiǎn)單、粗暴+無(wú)腦的存儲(chǔ)方式就是保存成一個(gè)文本文檔了。
使用open函數(shù),將結(jié)果一行行的保存成文本,這里涉及的知識(shí)點(diǎn)只有簡(jiǎn)單的幾條:
- 文件讀寫(xiě)模式,r 、w、a、b、+ ,掌握這幾種即可。
- 使用單獨(dú)的open打開(kāi)文件時(shí),需要注意結(jié)尾時(shí)的調(diào)用close()函數(shù)關(guān)閉文檔
- 推薦使用上下文管理器的with open操作
csv文件
之所以將csv與excel分開(kāi)說(shuō),首先需要掃盲下,csv屬于特定格式的文本文件(使用逗號(hào)分隔),而excel是二進(jìn)制文件。
csv可以直接使用文本編輯器打開(kāi),excel不行…
其實(shí)csv文件,完全可以使用open函數(shù)進(jìn)行保存,只要你將每行數(shù)據(jù)都使用,分隔開(kāi)即可。
另外,python自帶csv庫(kù),可以很方便的操作與保存該數(shù)據(jù)
xml文件
xml文件的方式,已經(jīng)逐漸被淘汰了,為什么這么說(shuō)?因?yàn)樗爆嵉臉?shù)形結(jié)構(gòu),導(dǎo)致了在傳輸過(guò)程中,占用了更多的內(nèi)存。所以,除非必要,真的不推薦以xml的形式存儲(chǔ)你的數(shù)據(jù)…
configparser
python模塊中configparser是一個(gè)專(zhuān)門(mén)用來(lái)保存配置文件的模塊庫(kù),它非常適合保存一些具有關(guān)聯(lián)性的數(shù)據(jù)內(nèi)容,尤其是配置文件。通過(guò)定義section的方式,在section中添加key:value的方式,可以直觀明了的數(shù)據(jù)內(nèi)容。我之前專(zhuān)門(mén)寫(xiě)了一篇關(guān)于它的文章,會(huì)附在公眾號(hào)的字文章中,喜歡的朋友可以去看看。
pyyaml
yaml類(lèi)型的文件已經(jīng)成為很多Linux下的主流配置文件類(lèi)型,比如Docker、Ansible等等都在使用yaml,但它依然不是一個(gè)主流的數(shù)據(jù)存儲(chǔ)方式,因?yàn)閥aml本身的格式要求太過(guò)嚴(yán)苛,比結(jié)構(gòu)化的Python格式更為嚴(yán)格,喜歡的朋友可以去研究下…
pickle
pickle模塊的使用面很窄,但不得不說(shuō)還是有些人會(huì)使用,所以簡(jiǎn)單說(shuō)些它的優(yōu)劣:
優(yōu)勢(shì):接口簡(jiǎn)單(與json相似);存儲(chǔ)格式通用型,及在Windows、Linux等平臺(tái)下通用;二進(jìn)制存儲(chǔ),效率高
劣勢(shì):pickle是python特定的協(xié)議,其他語(yǔ)言無(wú)法使用;pickle存在安全性,這個(gè)要著重說(shuō)下,看下圖
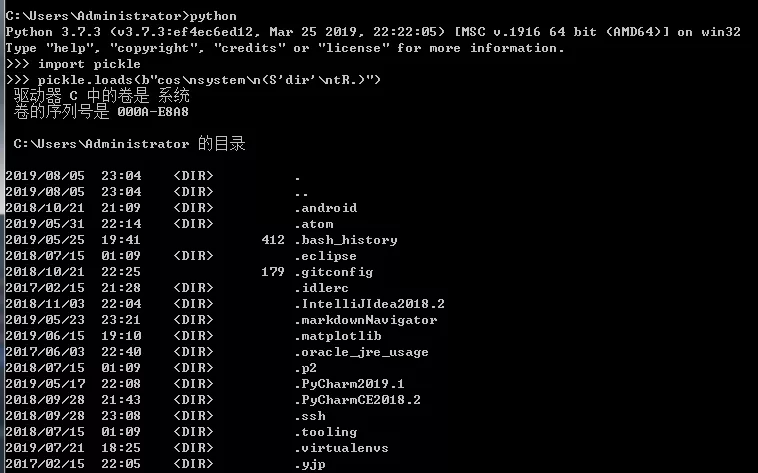
pickle安全性
Json文件
說(shuō)了上面那么多,壓軸的還是Json!
首先相對(duì)于xml,現(xiàn)在更多的網(wǎng)站在數(shù)據(jù)傳輸中使用json格式,因?yàn)橥鹊淖止?jié)下,json傳輸數(shù)據(jù)的效率要更高于xml。

json與xml對(duì)比
對(duì)于configparser,configparser有一個(gè)巨大的劣勢(shì),在于配置文件只能支持二維,section下定義option(key:value),如果想在option的value中再次定義列表、字典等數(shù)據(jù)類(lèi)型,它只能識(shí)別為字符串,你需要將str手動(dòng)再轉(zhuǎn)化為對(duì)應(yīng)的數(shù)據(jù)類(lèi)型
而針對(duì)ymal,json沒(méi)有那么嚴(yán)格的格式要求,寫(xiě)做一行還是換行展示都隨你,沒(méi)有那么嚴(yán)苛的要求。
最后對(duì)比pickle,json格式是各種編程語(yǔ)言通用的數(shù)據(jù)格式,由于是key value的鍵值對(duì),不存在loads之后的安全問(wèn)題。而且你學(xué)會(huì)了json,也就學(xué)會(huì)了pickle,因?yàn)槎叩氖褂梅绞揭幻粯影?
三分鐘學(xué)會(huì)Json
1.簡(jiǎn)介
JSON(JavaScript Object Notation, JS 對(duì)象簡(jiǎn)譜) 是一種輕量級(jí)的數(shù)據(jù)交換格式。它基于 ECMAScript (歐洲計(jì)算機(jī)協(xié)會(huì)制定的js規(guī)范)的一個(gè)子集,采用完全獨(dú)立于編程語(yǔ)言的文本格式來(lái)存儲(chǔ)和表示數(shù)據(jù)。簡(jiǎn)潔和清晰的層次結(jié)構(gòu)使得 JSON 成為理想的數(shù)據(jù)交換語(yǔ)言。易于人閱讀和編寫(xiě),同時(shí)也易于機(jī)器解析和生成,并有效地提升網(wǎng)絡(luò)傳輸效率。
至于推薦使用Json的理由:
- Json格式是一種通用的數(shù)據(jù)類(lèi)型
- Python內(nèi)置json模塊,便于操作
- json格式類(lèi)似于python的dict
- json的保存與讀取極為方便
- 學(xué)習(xí)成本低,3分鐘包教包會(huì)
2.類(lèi)型、語(yǔ)法說(shuō)明
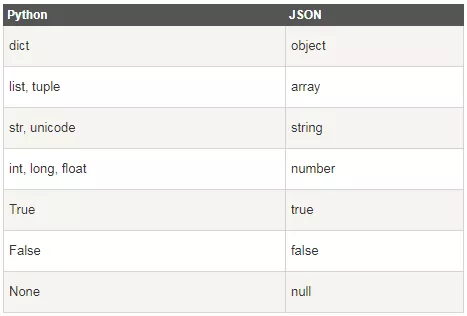
python與json數(shù)據(jù)類(lèi)型
看到上圖的Python與json對(duì)比關(guān)系,其實(shí)差異并不大,我們只需要注意幾點(diǎn)即可:
- json的數(shù)據(jù)為key:value,且以逗號(hào)分隔,但注意json使用雙引號(hào)包裹鍵值對(duì)
- 花括號(hào)中保存為對(duì)象,而方括號(hào)保存的是數(shù)組,不論python是list還是tuple,最終都會(huì)轉(zhuǎn)化為數(shù)組
- json由于是js引申的數(shù)據(jù)類(lèi)型,所以在布爾表達(dá)式與空值上,使用與python不同,需要注意
3.json的方法
.dump():將python對(duì)象序列化到一個(gè)文件,是文本文件,相當(dāng)于將序列化后的json字符寫(xiě)到一個(gè)文件
.load():從文件反序列表出python對(duì)象
json和pickle相同,都只有四個(gè)方法:
.dumps():將python對(duì)象編碼為json的字符串
.loads():將字符串編碼為一個(gè)python對(duì)象
即:帶s的方法是數(shù)據(jù)類(lèi)型間的轉(zhuǎn)化str <--> dict,不帶s的都是數(shù)據(jù)與文件的轉(zhuǎn)化
4.實(shí)例說(shuō)明
在演示前,我們需要先定義一個(gè)初始化數(shù)據(jù):
- 1data = {
- 2 "in_use": True,
- 3 "info": {
- 4 "name_cn": '清風(fēng)Python',
- 5 "name_en": "BreezePython",
- 6 },
- 7 "contents": ["Python", "Java", "Linux"]
- 8
- 9}
5..dumps() .loads()
- 1import json
- 2json.dumps(data)
- 3>>> '{"in_use": true, "info": {"name_cn": "\\u6e05\\u98cePython", "name_en": "BreezePython"}, "contents": ["Python", "Java", "Linux"]}'
- 4這里大家看到一個(gè)問(wèn)題,中文異常,此時(shí)我們需要添加參數(shù)ensure_ascii=False
- 5json.dumps(data,ensure_ascii=False)
- 6>>> '{"in_use": true, "info": {"name_cn": "清風(fēng)Python", "name_en": "BreezePython"}, "contents": ["Python", "Java", "Linux"]}'
- 7# 當(dāng)然我們可以美觀的打印它
- 8json_data = json.dumps(data, sort_keys=True, indent=4, separators=(',', ': '),ensure_ascii=False)
- 9print(json_data)
- 10>>> {
- 11 "contents": [
- 12 "Python",
- 13 "Java",
- 14 "Linux"
- 15 ],
- 16 "in_use": true,
- 17 "info": {
- 18 "name_cn": "清風(fēng)Python",
- 19 "name_en": "BreezePython"
- 20 }
- 21}
- 22
- 23# 了解了dumps,loads就比較簡(jiǎn)單了...
- 24json.loads(json_data)
- 25{'contents': ['Python', 'Java', 'Linux'], 'in_use': True, 'info': {'name_cn': '清風(fēng)Python', 'name_en': 'BreezePython'}}
6..dump() .load()
- 1import json
- 2# 先來(lái)看看dump將數(shù)據(jù)保存至文本
- 3with open('data.json', 'w', encoding='utf-8') as f:
- 4 json.dump(data, f, indent=4)
- 5 # 同理我們還可以使用dumps完成寫(xiě)入操作
- 6 # f.write(json.dumps(data, indent=4))
- 7
- 8# 保存了文本,我們?cè)谕ㄟ^(guò)load讀取出來(lái)
- 9with open('data.json', 'r', encoding='utf-8') as f:
- 10 data = json.load(f)
- 11 # 同理我們還可以使用loads完成讀取操作
- 12 # data = json.loads(f.read())
- 13print(data)
- 14>>> {'in_use': True, 'info': {'name_cn': '清風(fēng)Python', 'name_en': 'BreezePython'}, 'contents': ['Python', 'Java', 'Linux']}
看到這里,你是否發(fā)現(xiàn),即便不會(huì)dump和load我們一樣可以使用dumps和loads替換前兩者,完成讀寫(xiě)操作。三分鐘學(xué)會(huì)了json的操作,并且買(mǎi)一送一附帶學(xué)會(huì)了pickle的操作。你是否get到?