













支持百億請求的微博廣告運維技術(shù)實踐
一、運維在廣告體系中的價值
運維的工作來源已久,但直到近些年,隨著互聯(lián)網(wǎng)的發(fā)展,產(chǎn)品的維護工作越來越復(fù)雜,以及服務(wù)可用性的提升,都讓運維的工作越來越重要。我們可以回顧下運維發(fā)展至今都經(jīng)歷了哪些階段。
① 人工階段
這個階段的運維主要通過人肉操作我們的服務(wù),由于這個階段的服務(wù)大都是單實例,流量服務(wù)器都比較少,所以我們通過命令行就能夠解決絕大多數(shù)的問題。
② 工具階段
隨著互聯(lián)網(wǎng)影響逐漸變大,我們的流量也開始變大,我們的產(chǎn)品功能也開始變得豐富,曾經(jīng)我們單實例的服務(wù)也開始朝著多實例、分布式發(fā)展,為了應(yīng)對逐漸增加的服務(wù)器、服務(wù)數(shù),我們開始使用一些如Puppet的運維工具,通過Shell、Python寫一些腳本來提升運維的工作效率,減少重復(fù)的勞動。
③ DevOps
前幾年,運維領(lǐng)域開始提出DevOps的理念,開始著手解決運維與開發(fā)的合作問題,開始讓運維的工作走向規(guī)范化、平臺化。讓一個產(chǎn)品從功能開發(fā)到測試交付、再到后期運維能夠更加的快捷、頻繁、可靠,更快的響應(yīng)互聯(lián)網(wǎng)快速的發(fā)展和產(chǎn)品迭代。
④ AiOps
這兩年,人工智能和大數(shù)據(jù)的異常火熱,而運維領(lǐng)域的許多工作都為AI和大數(shù)據(jù)的實施落地提供了良好的土壤。我們也希望通過Ai和大數(shù)據(jù)等技術(shù)的引入,能夠?qū)⑦\維的技術(shù)層次帶入一個更高的臺階。
通過以上描述,我們可以看到運維的工作在互聯(lián)網(wǎng)的產(chǎn)品技術(shù)鏈中是不可或缺的一環(huán),那么下面我們再來看下在微博廣告團隊,我們都是通過哪些方案舉措來服務(wù)微博廣告的產(chǎn)品。
對于我們微博廣告團隊來說,服務(wù)的可用性是至關(guān)重要的,也是我們的核心KPI,所以保障廣告服務(wù)的穩(wěn)定性也是我們運維工作的重中之重。我們主要會通過優(yōu)化系統(tǒng)和提升效率兩個方面來保障和提升我們服務(wù)的可用性。
具體涉及的內(nèi)容包括系統(tǒng)性能評估、故障迅速定位、應(yīng)急事件處理、請求鏈路跟蹤、代碼快速迭代、指標走勢預(yù)測等等。
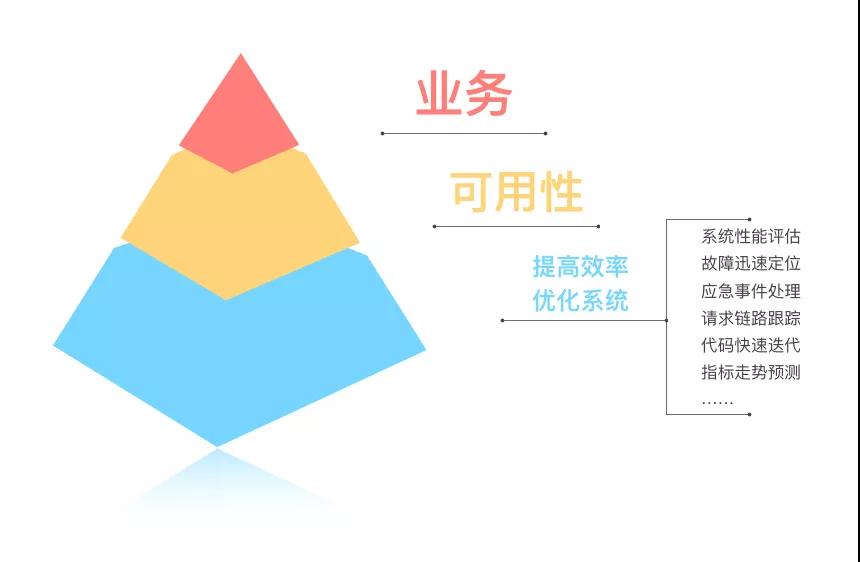
▲ 圖1-1 運維在微博廣告的價值
二、復(fù)雜業(yè)務(wù)場景下的運維建設(shè)之路
1、服務(wù)治理
圖2-1是去年IG奪冠時,王思聰發(fā)了一條博文,而這條博文對微博廣告的影響就如圖2-2所示。這種突發(fā)的流量波動是微博典型的特征之一,它不同于雙十一等活動,可以提前預(yù)估流量,做好前期準備工作。在傳統(tǒng)的運維場景下,也許在你也還沒準備好的情況下,流量的高峰就已經(jīng)過去了。所以如果應(yīng)對這樣突發(fā)的流量高峰是我們需要重點解決的問題之一。
▲ 圖2-1
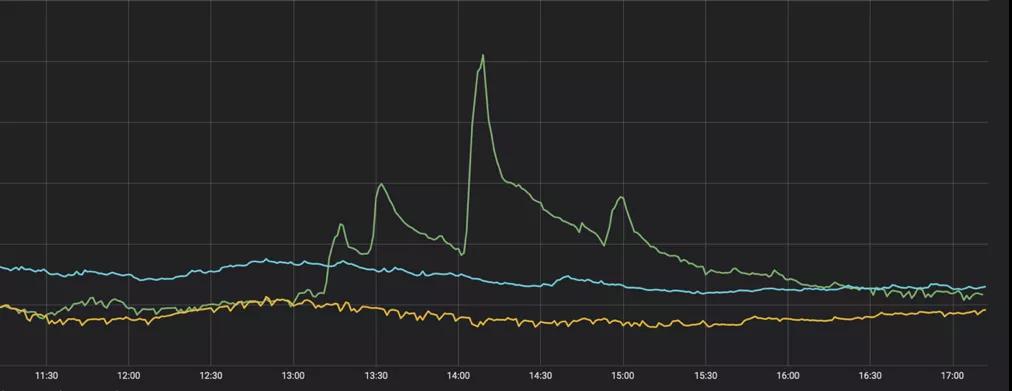
▲ 圖2-2
從去年開始,我們運維團隊開始進行基于機房的服務(wù)治理工作。在以前,廣告的很多服務(wù)部署都是單點單機房、很多多機房的部署也面臨部署不均衡,流量不均勻等現(xiàn)象。跨機房的請求更是無形的增加了整個廣告鏈路的請求耗時。所以再出現(xiàn)機房級故障時,我們的服務(wù)就可能像圖2-4所示的那樣,那么服務(wù)的高可用性也就無從談起了。
▲ 圖2-3
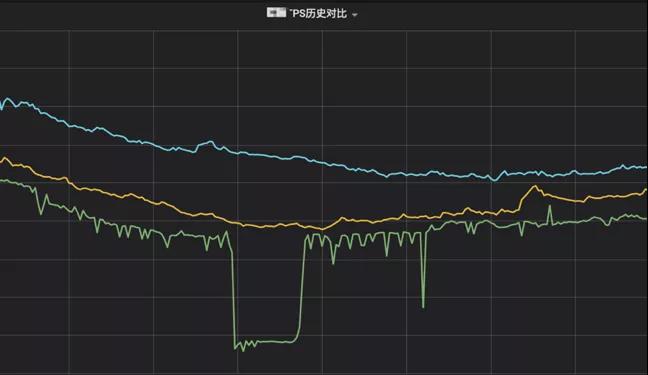
▲ 圖2-4
在19年的上半年,經(jīng)過大半年的時間,我們完成了微博廣告基于機房級別的服務(wù)優(yōu)化改造。共治理服務(wù)一百多個,所有的服務(wù)都分布在兩個及以上的運營商和機房中,從而避免了單機房出現(xiàn)故障時,造成廣告服務(wù)的不可用。而我們治理過程中堅持的準備主要有以下幾點:
- 服務(wù)多機房均衡部署
- 分布在不同運營商
- 機房承載能力冗余
- 流量請求均勻分布
- 上下游同機房請求
同時,我們還會定期做流量壓測,來發(fā)現(xiàn)我們系統(tǒng)鏈路中的服務(wù)瓶頸。我們將生產(chǎn)環(huán)境的流量重新拷貝到生產(chǎn)環(huán)境中去,來增加線上流量,發(fā)現(xiàn)服務(wù)性能瓶頸。
圖2-5是我們對某廣告產(chǎn)品的整體性能壓測所展示的效果,我們可以清楚的發(fā)現(xiàn)圖中有兩個模塊的在流量高峰下,出現(xiàn)了耗時波動較大的問題。由此我們可以針對性的進行優(yōu)化。
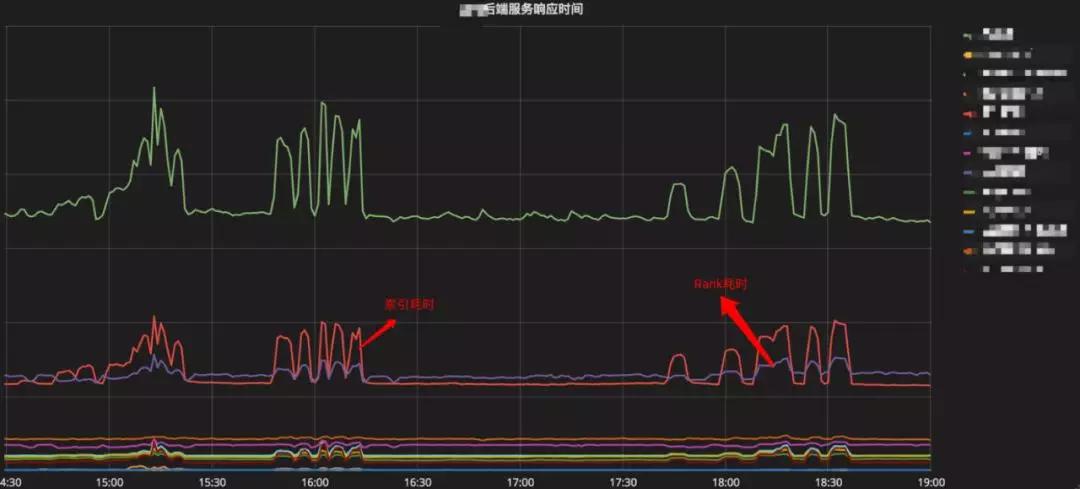
▲ 圖2-5
2、自動化運維平臺
隨著互聯(lián)網(wǎng)的發(fā)展,我們的廣告產(chǎn)品也是日新月異,迭代頻繁。我們運維團隊每天需要面對來自三百多個業(yè)務(wù)方提過來的上線需求,在三千多臺機器上進行服務(wù)的變更等操作,如何提升服務(wù)上線的效率和質(zhì)量,如何讓變更變得安全可靠也是我們重要的目標之一。

▲ 圖2-6
從17年開始,我們運維團隊自研了一套自動化運維平臺Kunkka,該平臺主要基于SaltStack、Jenkins等技術(shù),可以實現(xiàn)服務(wù)的快速上線、快速回滾等操作。整體架構(gòu)如圖2-7所示。
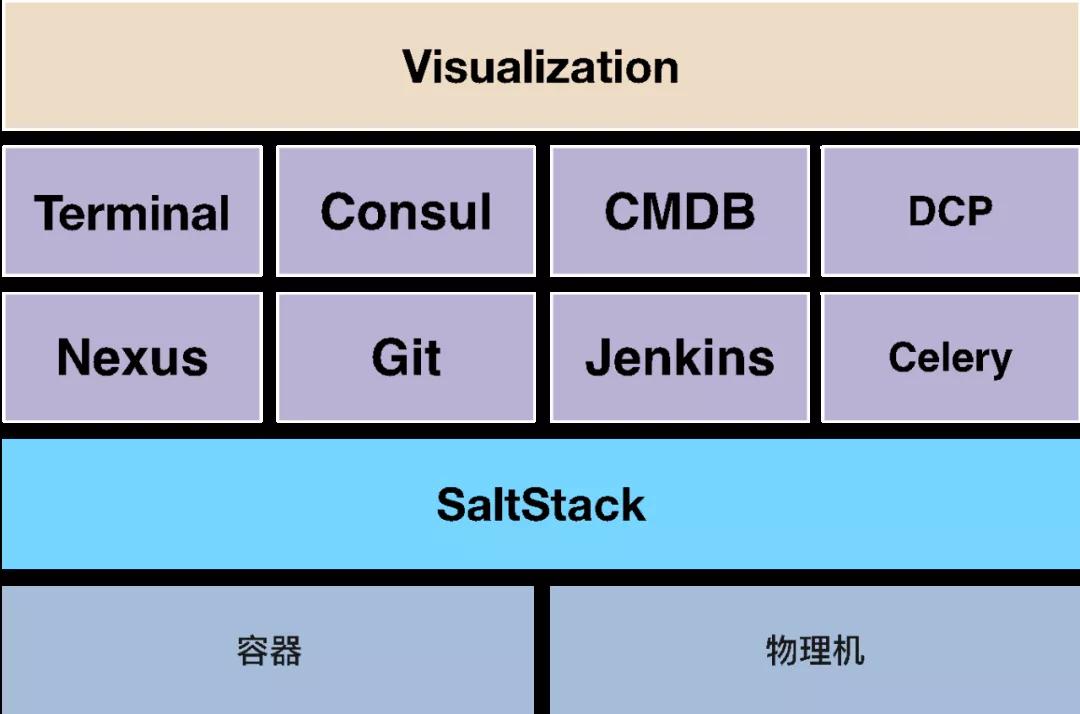
▲ 圖2-7 Kunkka整體架構(gòu)圖
開發(fā)同學在提交代碼到Gitlab后,自動觸發(fā)Jenkins的編譯操作,并將編譯后的包上傳至Nexus中,這時開發(fā)同學只需要選擇他們想要部署的目標主機就可以了。
同時,為了應(yīng)對平常突發(fā)的流量高峰和節(jié)假日的流量高峰,我們還對接了公司的DCP平臺,可以在我們的Kunkka平臺上自動生成Docker鏡像文件,并上傳公司的鏡像倉庫中,這樣就可以在快速的將服務(wù)部署到云主機上,實現(xiàn)服務(wù)動態(tài)擴縮容。
整個服務(wù)部署過程中,我們還加入了多級審核機制,保障服務(wù)上線的安全性。具體流程如圖2-8所示。
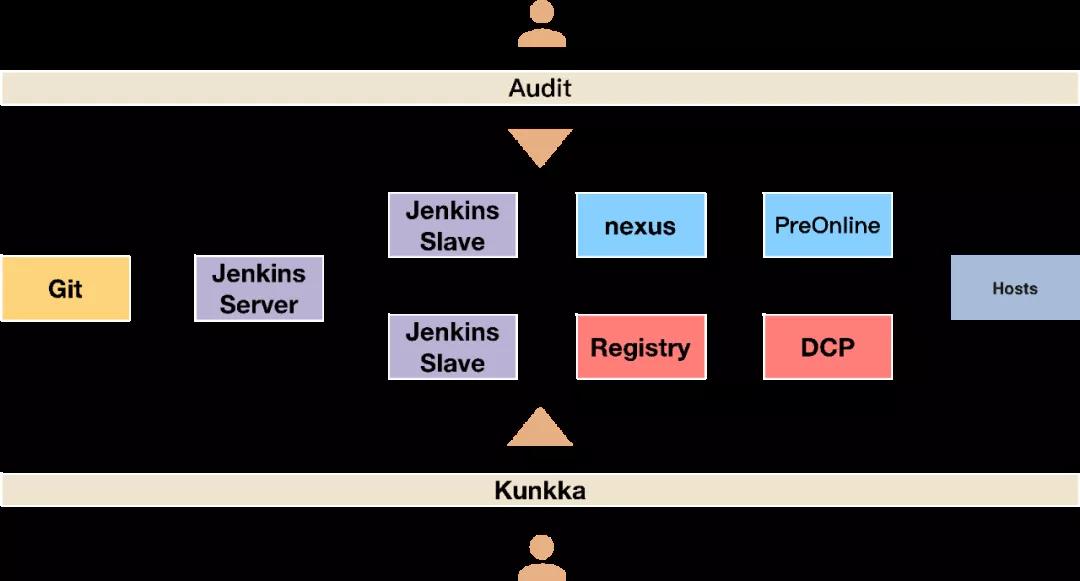
▲ 圖2-8 Kunkka上線流程圖
3、有效的報警
在服務(wù)上線后,我們要做的一個很重要的工作就是給我們的服務(wù)添加監(jiān)控報警機制,否則我們就像瞎子一樣,對我們系統(tǒng)服務(wù)運行情況一無所知。
關(guān)于報警系統(tǒng)業(yè)界優(yōu)秀的報警系統(tǒng)有很多,使用的方案也基本大同小異。我們目前主要用的是開源的Prometheus報警系統(tǒng),這里就不詳細介紹了。
這里主要想說下我們在做報警的一些想法。比如我們經(jīng)常遇到的一個問題就是報警郵件狂轟濫炸,每天能收到成百上千的報警郵件,這樣很容易讓系統(tǒng)中一些重要的報警信息石沉大海。對此,我們主要以下三個方面來考慮:
- 質(zhì)疑需求的合理性
- 報警聚合
- 追蹤溯源
首先,在業(yè)務(wù)方提出報警需求的時候,我們就需要學會質(zhì)疑他們的需求,因為并不是每個需求都是合理的,其實很多開發(fā)他們并不懂報警,也不知道如果去監(jiān)控自己的服務(wù)。這時候就是發(fā)揮我們運維人員的價值了。我們可以在充分了解服務(wù)架構(gòu)屬性的前提下提出我們的意見,和開發(fā)人員共同確定每個服務(wù)需要報警的關(guān)鍵指標。
其次,我們可以對報警做預(yù)聚合。現(xiàn)在我們的服務(wù)大都都是多機部署的,一個服務(wù)有可能部署到成百上千臺機器上。有時候因為人為失誤或者上線策略等原因,可能導(dǎo)致該服務(wù)集體下線,這時就會有成百上千來自不同主機的相同報警信息發(fā)送過來。
對于這種場景,我們可以通過報警聚合的方式,將一段時間內(nèi)相同的報警合并成一條信息,放在一封郵件里面發(fā)送給開發(fā)人員,從而避免郵件轟炸的情況發(fā)生。關(guān)于報警聚合,像Prometheus這樣的報警系統(tǒng)自身已經(jīng)支持,所以也不會有太多的開發(fā)量。
最后,再高層次,我們就可以通過一些策略、算法去關(guān)聯(lián)我們的報警。很多時候,一條服務(wù)鏈路上的某個環(huán)節(jié)出現(xiàn)問題可能導(dǎo)致整條鏈路上的多個服務(wù)都觸發(fā)了報警,這個時候,我們就可以通過服務(wù)與服務(wù)之間的相關(guān)性,上下游關(guān)系,通過一些依賴、算法等措施去屏蔽關(guān)聯(lián)的報警點,只對問題的根因進行報警,從而減少報警觸發(fā)的數(shù)量。
圖2-9是我們運維團隊17年優(yōu)化報警期間,報警數(shù)量的走勢。
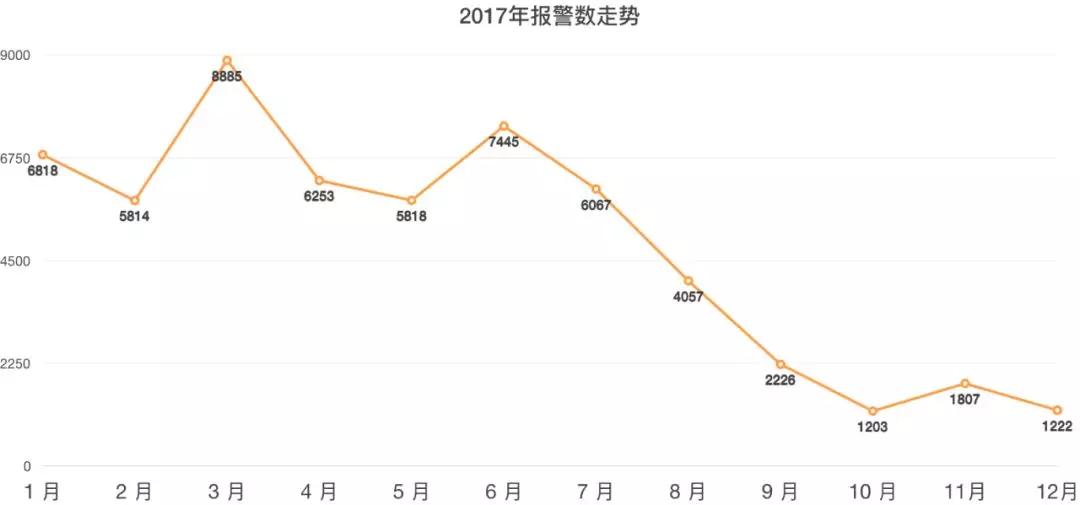
▲ 圖2-9 有效的報警
4、全鏈路Trace系統(tǒng)
除了添加報警以外,在服務(wù)上線后,我們還會經(jīng)常需要跟蹤我們整個服務(wù)鏈路處理請求的性能指標需求。這時就需要有一套全鏈路的Trace系統(tǒng)來方便我們實時監(jiān)控我們系統(tǒng)鏈路,及時排查問題,定位問題。
在全鏈路Trace系統(tǒng)中,最重要的就是Traceid,它需要貫穿整個鏈路,我們再通過Traceid來關(guān)聯(lián)所有的日志,從而跟蹤一條請求在整個系統(tǒng)鏈路上的指標行為。圖2-10是我們約定的用于全鏈路Trace的日志格式信息。
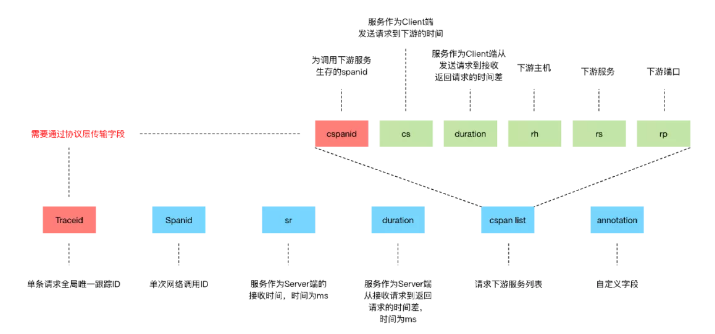
▲ 圖2-10 日志格式與解析
有了日志后,我們就可以基于這些日志進行分析關(guān)聯(lián),就像上面說的,Traceid是我們整個系統(tǒng)的核心,我們通過Traceid來關(guān)聯(lián)所有的日志。如圖2-11所示,所有的日志會寫入Kafka中,并通過Flink進行實時的日志解析處理,寫入ClickHouse中。有了這些關(guān)鍵指標數(shù)據(jù)后,我們就可以在此基礎(chǔ)上去做我們想做的事,比如形成服務(wù)拓撲進行請求跟蹤、日志的檢索以及指標的統(tǒng)計分析等。
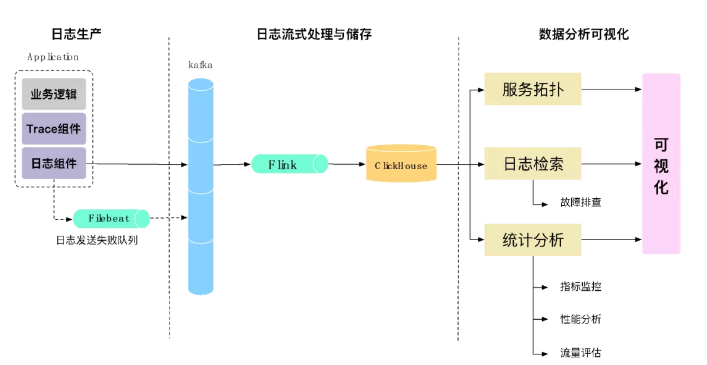
▲ 圖2-11 數(shù)據(jù)收集與處理
在所有的數(shù)據(jù)收集解析完成后,業(yè)務(wù)方就可以根據(jù)一些維度,比如UID,來跟蹤用戶的在整個廣告系統(tǒng)中請求處理情況,如圖2-12所示。隨后再將查詢的數(shù)據(jù)以Traceid維度進行關(guān)聯(lián)展示給用戶。
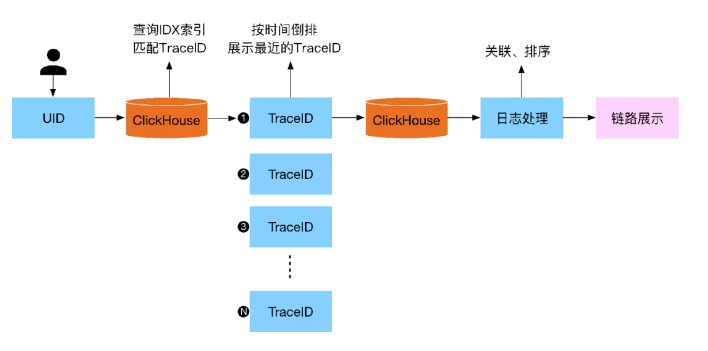
▲ 圖2-12 業(yè)務(wù)查詢
三、海量指標監(jiān)控平臺Oops實踐
最后我們看下我們?nèi)绾螒?yīng)對微博廣告海量指標數(shù)據(jù)下多維的監(jiān)控需求。前文也說了,監(jiān)控報警就像我們的眼睛,能夠讓我們實時的看到我們系統(tǒng)內(nèi)部的運行情況,因此,每一個服務(wù)都應(yīng)該有一些關(guān)鍵指標通過我們的監(jiān)控報警系統(tǒng)展示出來,實時反饋系統(tǒng)的健康狀態(tài)。
如圖3-1所示,做一個監(jiān)控平臺很容易,我們將指標、日志等數(shù)據(jù)進行ETL清洗后寫入一個時序數(shù)據(jù)庫中,再通過可視化工具展示出來,對于有問題的指標通過郵件或者微信的方式報警出來。但是在這個過程中,隨著我們數(shù)據(jù)量的增長、我們指標的增長以及查詢復(fù)雜度的增加,我們可能會遇到監(jiān)控指標延遲、數(shù)據(jù)偏差以及系統(tǒng)不穩(wěn)定等問題。
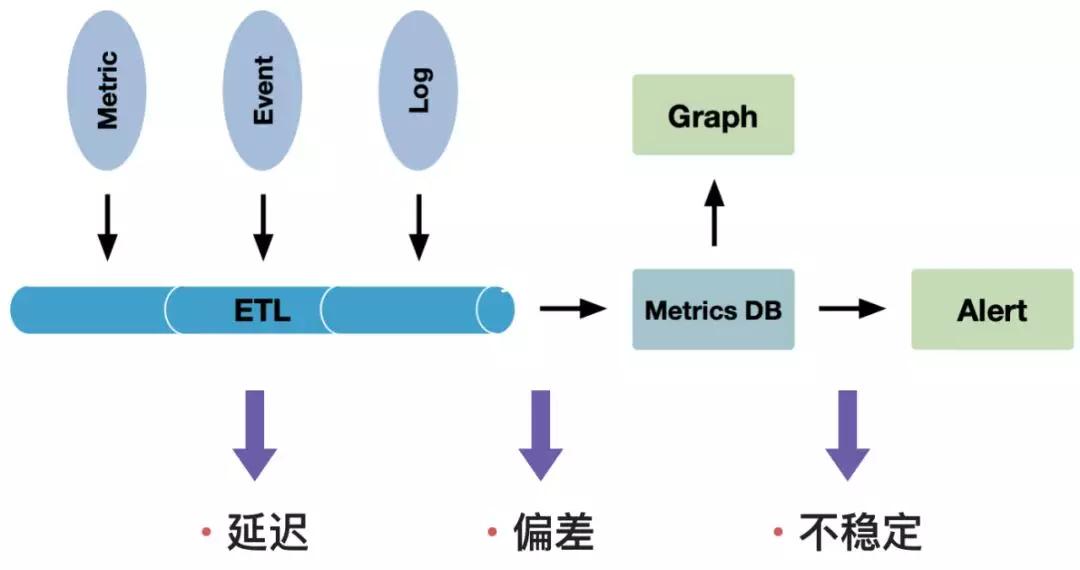
▲ 圖3-1 監(jiān)控平臺的挑戰(zhàn)
因此,在設(shè)計我們的監(jiān)控系統(tǒng)時,就不能僅僅基于實現(xiàn)考慮,還需要考慮它的穩(wěn)定性、實施性、準確性,同時還應(yīng)盡量把系統(tǒng)做的簡單易用。
▲ 圖3-2 監(jiān)控平臺的目標
而我們目前的監(jiān)控平臺Oops,也是基于上述原則,經(jīng)歷了多年的迭代和考驗。圖3-3是我們Oops監(jiān)控平臺當前的整體架構(gòu)。
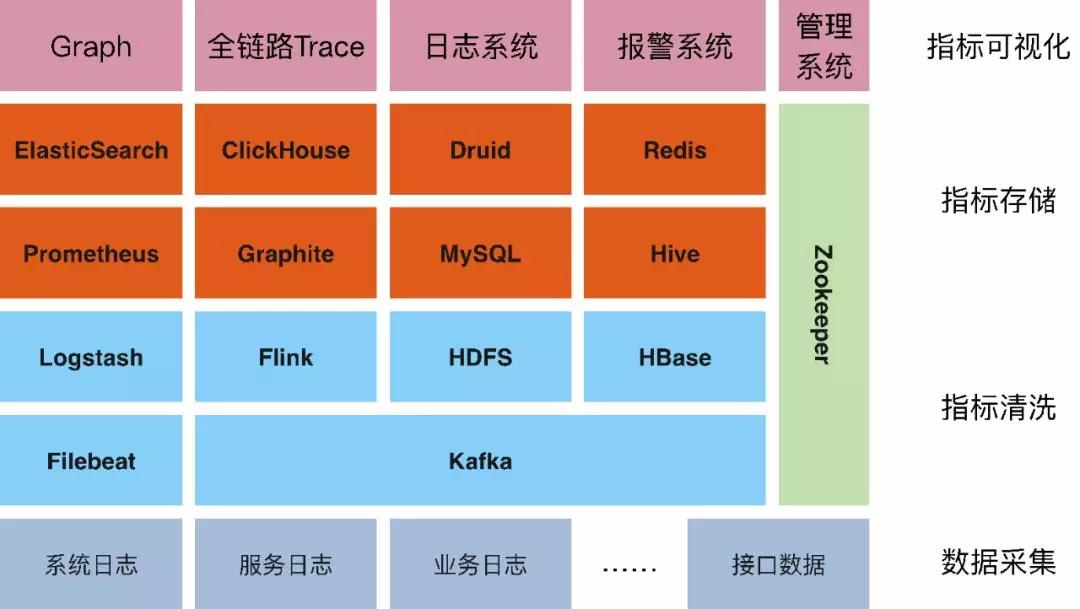
▲ 圖3-3 Oops監(jiān)控平臺架構(gòu)
① 數(shù)據(jù)采集
整個平臺分為四個層次,首先是我們的數(shù)據(jù)采集。我們當前主要通過Filebeat這樣一款優(yōu)秀的開源采集客戶端來采集我們的日志。對我們使用而言,F(xiàn)ilebeat足夠的高效、輕量,使用起來也很靈活易用。
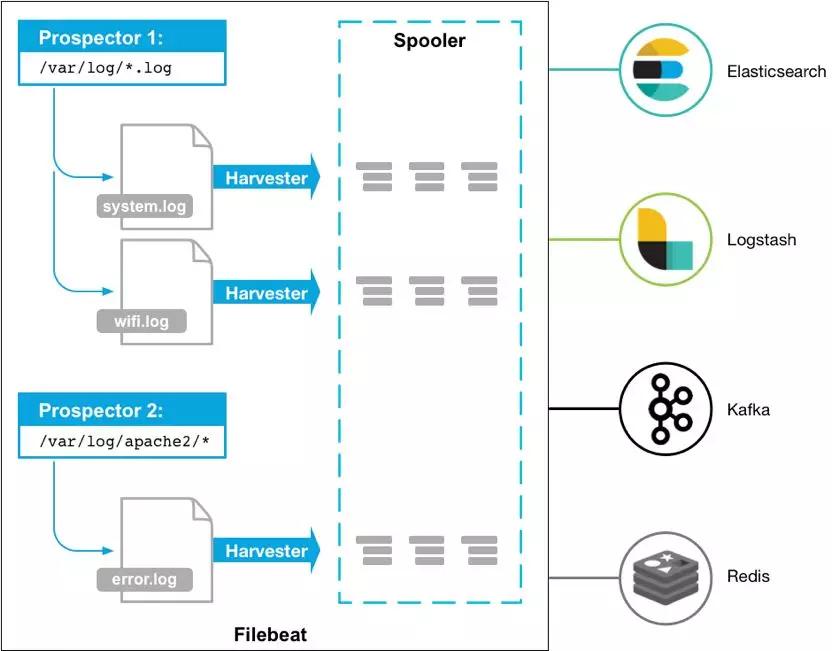
▲ 圖3-4 Filebeat架構(gòu)圖
② 指標清洗
數(shù)據(jù)采集到Kafka后,我們再根據(jù)具體的業(yè)務(wù)需求將指標提取出來。如圖3-5所示,當前我們主要通過Flink來解析日志,并寫入ClickHouse中。
同時,針對一些業(yè)務(wù)需求,我們需要將一些指標維度做關(guān)聯(lián)處理,這里主要通過HBase實現(xiàn)指標的關(guān)聯(lián),比如,有曝光和互動兩個日記,我們將曝光日志中的mark_id字段作為rowkey寫入HBase中,并儲存一個小時,當在時間窗口內(nèi)互動日志匹配到相同的mark_id時,就將曝光日志的內(nèi)容從HBase中取出,并與互動日志組合成一條新的日志,寫入到一個新的Kafka Topic中。
此外,我們還將Kafka中數(shù)據(jù)消費寫入ElasticSearch和HDFS中,用于日志檢索和離線計算。
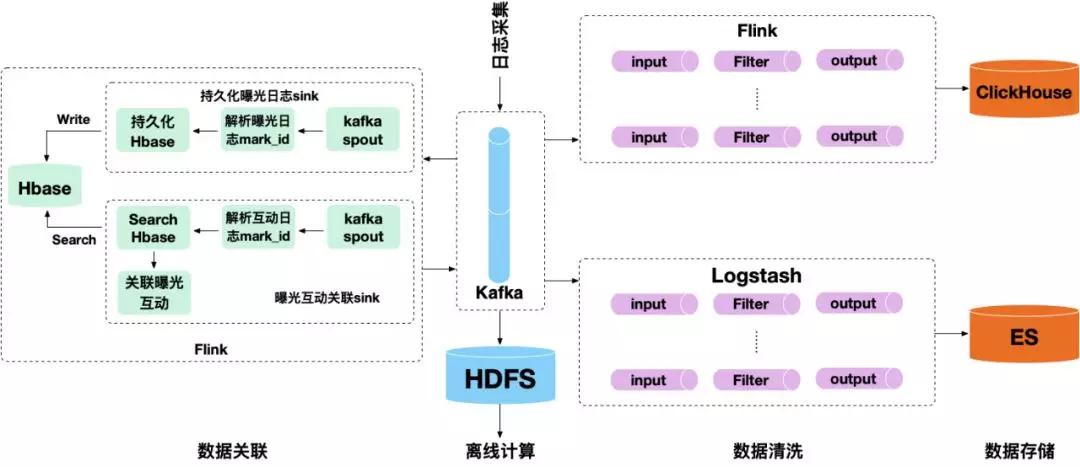
▲ 圖3-5 指標清洗
③ 指標儲存
當前,我們通過ClickHouse來儲存查詢我們的監(jiān)控指標。最初也是選擇了流行的時序數(shù)據(jù)庫Graphite。但是在長期的使用中,我們發(fā)現(xiàn)在復(fù)雜的多維分析上,Graphite并沒有很好的體驗。在去年,我們將我們的監(jiān)控指標引擎替換成了現(xiàn)在的ClickHouse,ClickHouse是一款優(yōu)秀的開源OLAP引擎,它在多維分析等功能上相比傳統(tǒng)的時序數(shù)據(jù)庫具有很大的優(yōu)勢。
同時,我們基于ClickHouse強大的函數(shù)功能和物化視圖表引擎構(gòu)建了一個實時的指標倉庫。如圖3-6所示,我們會將清洗后的指標寫入到一張原始表中,比如這里的ods_A,我們再根據(jù)具體的監(jiān)控需求在ods_A表上進行維度的聚合。再比如,我們將請求維度按秒聚合成agg_A_1s,或者按照psid維度按分鐘聚合成agg_A_1m_psid,又或者我們按照用戶id維度來統(tǒng)計每個用戶的訪問次數(shù)。
由此我們可以實現(xiàn)不同時間維度和不同業(yè)務(wù)維度的組合分析查詢,同時提升了查詢響應(yīng)速度,以及數(shù)據(jù)的重復(fù)利用率。而原始表的存在也讓我們可以根據(jù)不同的需求定制不同的復(fù)雜的聚合表數(shù)據(jù)。
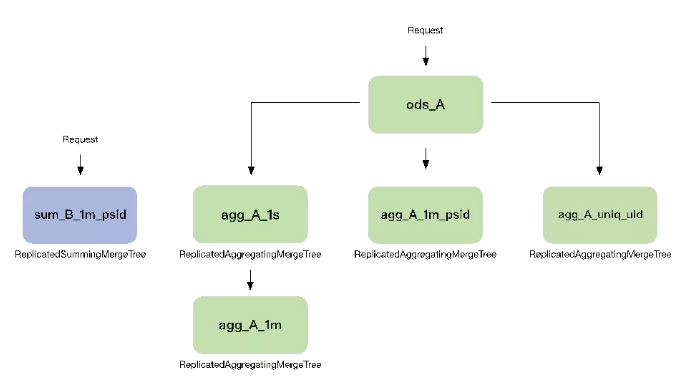
▲ 圖3-6 實時指標倉庫
④ 指標可視化
最后,我們通過Grafana實現(xiàn)我們的指標可視化,Grafana應(yīng)該是當前全球最受歡迎的監(jiān)控可視化開源軟件,它支持很多的數(shù)據(jù)源,而ClickHouse也是其中之一,我們只需要寫一條SQL就可以按照我們的想法在Grafana上以圖表的形式呈現(xiàn)出來。如圖3-7呈現(xiàn)的監(jiān)控圖就是圖3-8這樣一條簡單的SQL實現(xiàn)的。
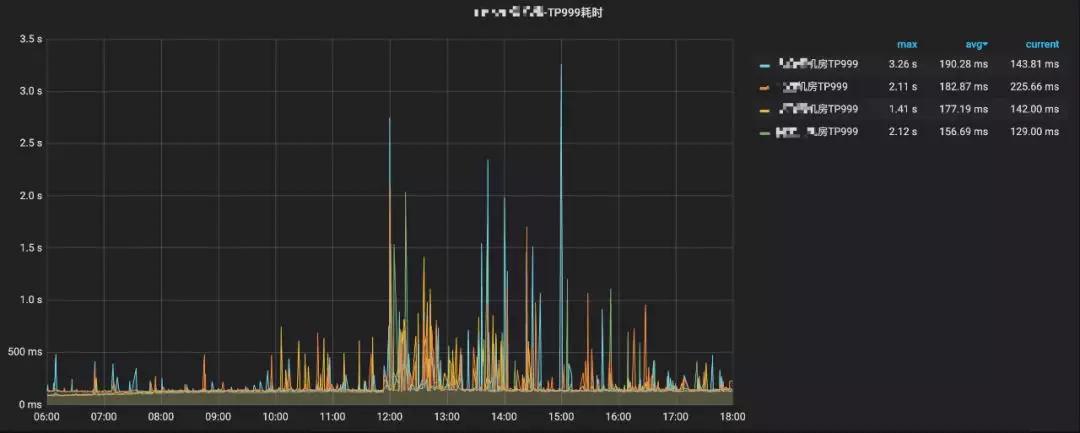
▲ 圖3-7 折線圖監(jiān)控指標

▲ 圖3-8 折線圖監(jiān)控指標SQL語句
對于表格的指標監(jiān)控展示,也很簡單,也是一條SQL就能完成的,如圖3-9所示。
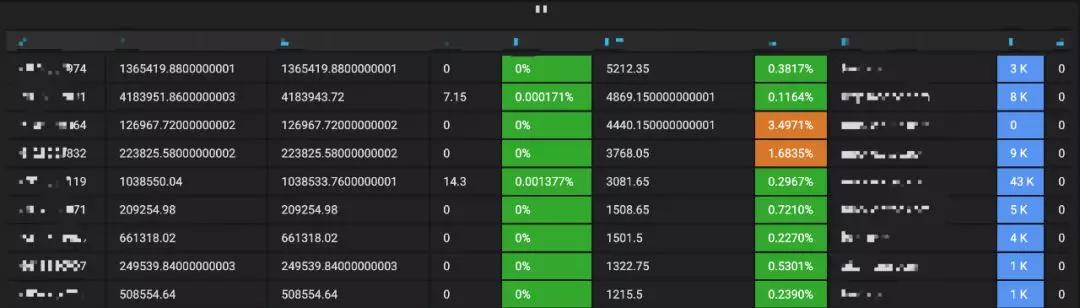
▲ 圖3-9 表格監(jiān)控指標
當前我們的實時指標倉庫存儲120T的數(shù)據(jù)量,峰值處理QPS在125萬左右,秒級查詢、多維分析,為微博廣告的指標監(jiān)控、數(shù)據(jù)分析以及鏈路跟蹤等場景提供了底層數(shù)據(jù)支撐。
講師介紹
朱偉,微博廣告SRE團隊負責人,書籍《智能運維:從0搭建大規(guī)模分布式AIOps系統(tǒng)》作者之一。目前負責微博廣告業(yè)務(wù)可用性的保障與優(yōu)化、資源利用率的提升、監(jiān)控報警系統(tǒng)的建設(shè)以及自動化體系的推進。

















