













淺談集群版Redis和Gossip協議
1.Redis Cluster的基本概念
集群版的Redis聽起來很高大上,確實相比單實例一主一從或者一主多從模式來說復雜了許多,互聯網的架構總是隨著業務的發展不斷演進的。
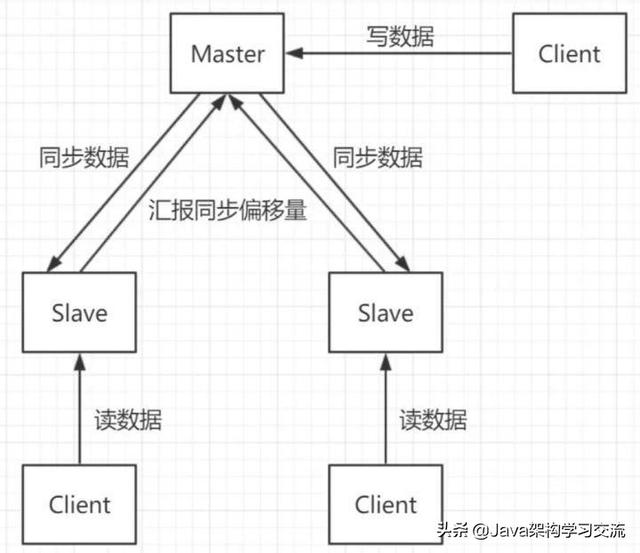
- 單實例Redis架構
最開始的一主N從加上讀寫分離,Redis作為緩存單實例貌似也還不錯,并且有Sentinel哨兵機制,可以實現主從故障遷移。
單實例一主兩從+讀寫分離結構:
注:圖片來自網絡
單實例的由于本質上只有一臺Master作為存儲,就算機器為128GB的內存,一般建議使用率也不要超過70%-80%,所以最多使用100GB數據就已經很多了,實際中50%就不錯了,以為數據量太大也會降低服務的穩定性,因為數據量太大意味著持久化成本高,可能嚴重阻塞服務,甚至最終切主。
如果單實例只作為緩存使用,那么除了在服務故障或者阻塞時會出現緩存擊穿問題,可能會有很多請求一起搞死MySQL。
如果單實例作為主存,那么問題就比較大了,因為涉及到持久化問題,無論是bgsave還是aof都會造成刷盤阻塞,此時造成服務請求成功率下降,這個并不是單實例可以解決的,因為由于作為主存儲,持久化是必須的。
所以我們期待一個多主多從的Redis系統,這樣無論作為主存還是作為緩存,壓力和穩定性都會提升,盡管如此,筆者還是建議:
如果你一意孤行,那么要么坑了自己,要么坑了別人。
- 集群與分片
要支持集群首先要克服的就是分片問題,也就是一致性哈希問題,常見的方案有三種:
客戶端分片:這種情況主要是類似于哈希取模的做法,當客戶端對服務端的數量完全掌握和控制時,可以簡單使用。
中間層分片:這種情況是在客戶端和服務器端之間增加中間層,充當管理者和調度者,客戶端的請求打向中間層,由中間層實現請求的轉發和回收,當然中間層最重要的作用是對多臺服務器的動態管理。
服務端分片:不使用中間層實現去中心化的管理模式,客戶端直接向服務器中任意結點請求,如果被請求的Node沒有所需數據,則像客戶端回復MOVED,并告訴客戶端所需數據的存儲位置,這個過程實際上是客戶端和服務端共同配合,進行請求重定向來完成的。
- 中間層分片的集群版Redis
前面提到了變為N主N從可以有效提高處理能力和穩定性,但是這樣就面臨一致性哈希的問題,也就是動態擴縮容時的數據問題。
在Redis官方發布集群版本之前,業內有一些方案迫不及待要用起自研版本的Redis集群,其中包括國內豌豆莢的Codis、國外Twiter的twemproxy。
核心思想都是在多個Redis服務器和客戶端Client中間增加分片層,由分片層來完成數據的一致性哈希和分片問題,每一家的做法有一定的區別,但是要解決的核心問題都是多臺Redis場景下的擴縮容、故障轉移、數據完整性、數據一致性、請求處理延時等問題。
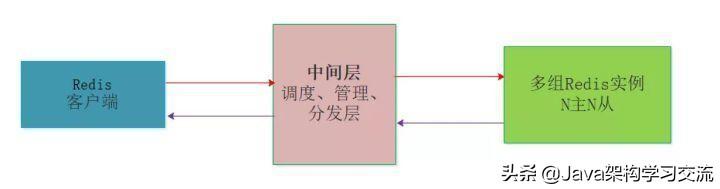
業內Codis配合LVS等多種做法實現Redis集群的方案有很多都應用到生成環境中,表現都還不錯,主要是官方集群版本在Redis3.0才出現,對其穩定性如何,很多公司都不愿做小白鼠,不過事實上經過迭代目前已經到了Redis5.x版本,官方集群版本還是很不錯的,至少筆者這么認為。
- 服務端分片的官方集群版本
官方版本區別于上面的Codis和Twemproxy,實現了服務器層的Sharding分片技術,換句話說官方沒有中間層,而是多個服務結點本身實現了分片,當然也可以認為實現sharding的這部分功能被融合到了Redis服務本身中,并沒有單獨的Sharding模塊。
之前的文章也提到了官方集群引入slot的概念進行數據分片,之后將數據slot分配到多個Master結點,Master結點再配置N個從結點,從而組成了多實例sharding版本的官方集群架構。
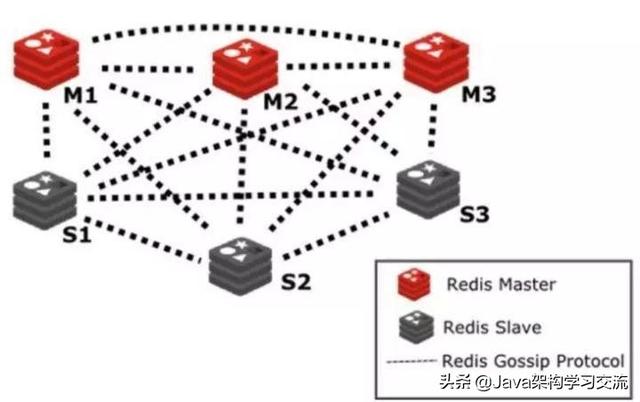
Redis Cluster 是一個可以在多個 Redis 節點之間進行數據共享的分布式集群,在服務端,通過節點之間的特殊協議進行通訊,這個特殊協議就充當了中間層的管理部分的通信協議,這個協議稱作Gossip流言協議。
分布式系統一致性協議的目的就是為了解決集群中多結點狀態通知的問題,是管理集群的基礎。
如圖展示了基于Gossip協議的官方集群架構圖:
注:圖片來自網絡
2.Redis Cluster的基本運行原理
- 結點狀態信息結構
Cluster中的每個節點都維護一份在自己看來當前整個集群的狀態,主要包括:
- 當前集群狀態
- 集群中各節點所負責的slots信息,及其migrate狀態
- 集群中各節點的master-slave狀態
- 集群中各節點的存活狀態及不可達投票
也就是說上面的信息,就是集群中Node相互八卦傳播流言蜚語的內容主題,而且比較全面,既有自己的更有別人的,這么一來大家都相互傳,最終信息就全面而且準確了,區別于拜占庭帝國問題,信息的可信度很高。
基于Gossip協議當集群狀態變化時,如新節點加入、slot遷移、節點宕機、slave提升為新Master,我們希望這些變化盡快的被發現,傳播到整個集群的所有節點并達成一致。節點之間相互的心跳(PING,PONG,MEET)及其攜帶的數據是集群狀態傳播最主要的途徑。
- Gossip協議的概念
gossip 協議(gossip protocol)又稱 epidemic 協議(epidemic protocol),是基于流行病傳播方式的節點或者進程之間信息交換的協議。
在分布式系統中被廣泛使用,比如我們可以使用 gossip 協議來確保網絡中所有節點的數據一樣。
gossip protocol 最初是由施樂公司帕洛阿爾托研究中心(Palo Alto Research Center)的研究員艾倫·德默斯(Alan Demers)于1987年創造的。https://www.iteblog.com/archives/2505.html
Gossip協議已經是P2P網絡中比較成熟的協議了。Gossip協議的最大的好處是,即使集群節點的數量增加,每個節點的負載也不會增加很多,幾乎是恒定的。這就允許Consul管理的集群規模能橫向擴展到數千個節點。
Gossip算法又被稱為反熵(Anti-Entropy),熵是物理學上的一個概念,代表雜亂無章,而反熵就是在雜亂無章中尋求一致,這充分說明了Gossip的特點:在一個有界網絡中,每個節點都隨機地與其他節點通信,經過一番雜亂無章的通信,最終所有節點的狀態都會達成一致。每個節點可能知道所有其他節點,也可能僅知道幾個鄰居節點,只要這些節可以通過網絡連通,最終他們的狀態都是一致的,當然這也是疫情傳播的特點。https://www.backendcloud.cn/2017/11/12/raft-gossip/
上面的描述都比較學術,其實Gossip協議對于我們吃瓜群眾來說一點也不陌生,Gossip協議也成為流言協議,說白了就是八卦協議,這種傳播規模和傳播速度都是非常快的,你可以體會一下。所以計算機中的很多算法都是源自生活,而又高于生活的。
- Gossip協議的使用
Redis 集群是去中心化的,彼此之間狀態同步靠 gossip 協議通信,集群的消息有以下幾種類型:
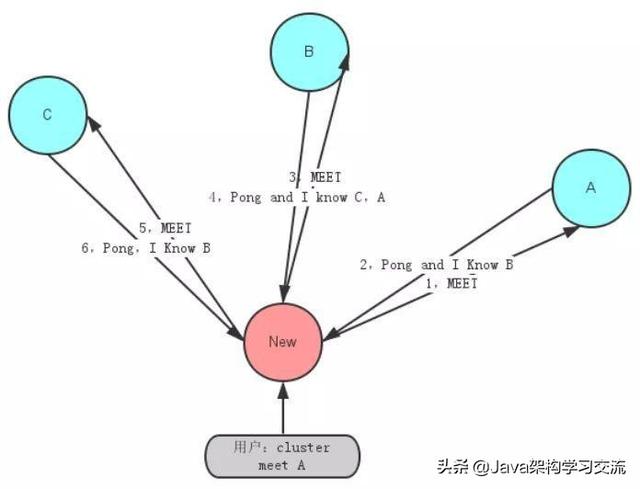
- Meet 通過「cluster meet ip port」命令,已有集群的節點會向新的節點發送邀請,加入現有集群。
- Ping 節點每秒會向集群中其他節點發送 ping 消息,消息中帶有自己已知的兩個節點的地址、槽、狀態信息、最后一次通信時間等。
- Pong 節點收到 ping 消息后會回復 pong 消息,消息中同樣帶有自己已知的兩個節點信息。
- Fail 節點 ping 不通某節點后,會向集群所有節點廣播該節點掛掉的消息。其他節點收到消息后標記已下線。
由于去中心化和通信機制,Redis Cluster 選擇了最終一致性和基本可用。
例如當加入新節點時(meet),只有邀請節點和被邀請節點知道這件事,其余節點要等待 ping 消息一層一層擴散。除了 Fail 是立即全網通知的,其他諸如新節點、節點重上線、從節點選舉成為主節點、槽變化等,都需要等待被通知到,也就是Gossip協議是最終一致性的協議。
由于 gossip 協議對服務器時間的要求較高,否則時間戳不準確會影響節點判斷消息的有效性。另外節點數量增多后的網絡開銷也會對服務器產生壓力,同時結點數太多,意味著達到最終一致性的時間也相對變長,因此官方推薦最大節點數為1000左右。如圖展示了新加入結點服務器時的通信交互圖:
注:圖片來自網絡
總起來說Redis官方集群是一個去中心化的類P2P網絡,P2P早些年非常流行,像電驢、BT什么的都是P2P網絡。在Redis集群中Gossip協議充當了去中心化的通信協議的角色,依據制定的通信規則來實現整個集群的無中心管理節點的自治行為。
- 基于Gossip協議的故障檢測
集群中的每個節點都會定期地向集群中的其他節點發送PING消息,以此交換各個節點狀態信息,檢測各個節點狀態:在線狀態、疑似下線狀態PFAIL、已下線狀態FAIL。
自己保存信息:當主節點A通過消息得知主節點B認為主節點D進入了疑似下線(PFAIL)狀態時,主節點A會在自己的clusterState.nodes字典中找到主節點D所對應的clusterNode結構,并將主節點B的下線報告添加到clusterNode結構的fail_reports鏈表中,并后續關于結點D疑似下線的狀態通過Gossip協議通知其他節點。
一起裁定:如果集群里面,半數以上的主節點都將主節點D報告為疑似下線,那么主節點D將被標記為已下線(FAIL)狀態,將主節點D標記為已下線的節點會向集群廣播主節點D的FAIL消息,所有收到FAIL消息的節點都會立即更新nodes里面主節點D狀態標記為已下線。
最終裁定:將 node 標記為 FAIL 需要滿足以下兩個條件:
- 有半數以上的主節點將 node 標記為 PFAIL 狀態。
- 當前節點也將 node 標記為 PFAIL 狀態。
也就是說當前節點發現其他結點疑似掛掉了,那么就寫在自己的小本本上,等著通知給其他好基友,讓他們自己也看看,最后又一半以上的好基友都認為那個節點掛了,并且那個節點自己也認為自己掛了,那么就是真的掛了,過程還是比較嚴謹的。
















