













如何使用 Julia 語言實現「同態加密+機器學習」?
最近,「區塊鏈」、「聯邦學習」等概念受到了空前的關注。而在這些概念背后,少不了一項技術的影子——「同態加密」。本文介紹了使用 Julia 語言進行基于同態加密數據機器學習的全過程,對于入門者具有極大的參考價值。
注意:本文討論了最前沿的密碼學技術,旨在提供一種利用「Julia Computing」進行研究的視角。請不要將文中的任何示例用于生產應用程序。在使用密碼學之前一定要咨詢專業的密碼學專家。
程序包:https://github.com/JuliaComputing/ToyFHE.jl
相關代碼:https://github.com/JuliaComputing/ToyFHE.jl/blob/master/examples/encrypted_mnist/infer.jl
引言
假設你開發了一個酷炫的新機器學習模型,現在你想將部署該模型,為用戶提供服務。應該怎么做呢?最簡單的方法可能是直接把模型發布給用戶,然后讓他們使用自己的數據在本地運行這個模型。但這種方法存在一些問題:
- 機器學習模型一般都很大,而用戶的設備實際上可能沒有足夠的存儲空間或算力來運行模型
- 機器學習模型一般都會頻繁地更新,你可能不會想在網絡上頻繁傳輸這么大的模型
- 開發機器學習模型需要大量時間和計算資源,你可能會想通過向使用該模型的用戶收費來收回成本
接下來,常用的解決方案是將模型作為應用程序接口(API)在云上公開。在過去幾年間,這些「機器學習即服務」產品如雨后春筍般涌現,每個主要的云平臺都會為企業級開發者提供這樣的服務。
但這類產品的潛在用戶所面對的困境也是顯而易見的——處理用戶數據的遠程服務器可能并不可信。這樣就會存在明確的倫理和法律的分歧,從而限制這種解決方案的有效范圍。在受監管的產業(尤其是醫療業和金融業)中,一般是不允許將病患或金融數據發送給第三方進行處理的。我們可以做得更好嗎?
事實證明,我們可以!最近,密碼學方面取得的突破可以在無需進行解密的情況下,直接計算加密數據。在我們的例子中,用戶可以將加密數據(例如圖像)傳遞給云 API,以此運行機器學習模型,并返回加密的答案。整個過程中都沒有解密用戶數據,尤其是云服務商既不能訪問原始圖像,也不能解碼計算得到的預測值。這是怎么做到的呢?本文通過構建一個進行加密圖像的手寫識別(來自 MNIST 數據集)的機器學習模型為大家揭秘背后的原理。
同態加密(Homomorphic Encryption,HE)的一般解釋
一般而言,對加密數據進行計算的能力被稱為「安全計算」,這是一個相當大的研究領域,針對大量不同的場景要用不同的密碼學方法和技術解決問題。在本例中,我們將關注所謂的「同態加密」技術。在同態加密系統中,我們一般要進行以下操作:
- pub_key, eval_key, priv_key = keygen()
- encrypted = encrypt(pub_key, plaintext)
- decrypted = decrypt(priv_key, encrypted)
- encrypted′ = eval(eval_key, f, encrypted)
前三步非常直觀,之前使用過任何非對稱加密技術的人都會對此感到很熟悉(就像通過安全傳輸層協議(TLS)連接到本文)。最后一步才是神奇之處。它使用加密數據評估了 f,并返回了另一個與基于加密值評估 f 的結果對應的加密值。這一性質正是我們將這種技術稱為「同態加密」的原因。評估操作與下面的加密操作等價:
- f(decrypt(priv_key, encrypted)) == decrypt(priv_key, eval(eval_key, f, encrypted))
(同樣地,可以基于加密值評估任意的同態 f)
支持哪些函數 f 取決于加密方案和支持的運算。如果只支持一種函數 f(比如 f=+),我們可以將這種加密方案稱為「部分同態」。如果 f 是可以建立任意電路的完整的門的集合,如果電路大小有限,稱之為「有限同態」(Somewhat Homomorphic Encryption, SHE);如果電路大小不受限制,稱之為「全同態」(Fully Homomorphic Encryption, FHE)。一般可以通過自助法(bootstrapping),將「有限」同態轉換為「全」同態,但這個問題已經超過了本文所討論的內容。
全同態加密是最近的研究,Craig Gentry 在 2009 年發表了第一個可行(但不實際)的方。現在陸續出現了一些更新也更實際的 FHE 方案。更重要的是,還有一些可以高效地實現這一方案的軟件包。最常用的兩個軟件包是 Microsoft SEAL和 PALISADE。此外,我最近還開源了這些算法的 Julia 實現(https://github.com/JuliaComputing/ToyFHE.jl)。出于我們的目的,我們將使用后者中實現的 CKKS 加密。
高級 CKKS
CKKS(以 Cheon-Kim-Kim-Song 的名字命名,他在 2016 年的論文「Homomorphic Encryption for Arithmetic of Approximate Numbers」提出)是一種同態加密方案,可以對以下基本操作進行同態評估:
- 長度為 n 的復數向量的對應元素相加
- 長度為 n 的復數向量的對應元素相乘
- 向量中元素的旋轉(通過循環移位實現)
向量元素的復共軛
這里的參數 n 取決于需要的安全性和準確性,該值一般都比較高。在本例中,n=4096(值越高越安全,但是計算開銷也更大,時間復雜度大致會縮放為 nlog^n)。
此外,用 CKKS 計算是有噪聲的。因此,計算結果一般都只是近似值,而且要注意確保評估結果足夠準確,不會影響結果的正確性。
也就是說,對機器學習程序包的開發者而言,這些限制并不罕見。像 GPU 這樣有特殊用途的加速器,也可以處理數字向量。同樣,許多開發者會因算法選擇的影響、多線程等原因,認為浮點數噪聲太多(我要強調的是,有一個關鍵的區別是,浮點算法本身是確定性的,盡管因為實現的復雜性,它有時不會展現出這種確定性,但 CKKS 原語的噪聲真的很多,但這也許可以讓用戶意識到噪聲并沒有第一次出現時那么可怕)。
考慮到這一點,我們再看看如何在 Julia 中執行這些運算(注意:這里有一些非常不安全的參數選擇,這些操作的目的是說明這個庫在交互式解釋器(REPL)中的用法)。
- julia> using ToyFHE
- # Let's play with 8 element vectors
- julia> N = 8;
- # Choose some parameters - we'll talk about it later
- julia> ℛ = NegacyclicRing(2N, (40, 40, *40*))
- ℤ₁₃₂₉₂₂₇₉₉₇₅₆₈₀₈₁₄₅₇₄₀₂₇₀₁₂₀₇₁₀₄₂₄₈₂₅₇/(x¹⁶ + 1)
- # We'll use CKKS julia> params = CKKSParams(ℛ)
- CKKS parameters
- # We need to pick a scaling factor for a numbers - again we'll talk about that later
- julia> Tscale = FixedRational{2^40}
- FixedRational{1099511627776,T} where T
- # Let's start with a plain Vector of zeros
- julia> plain = CKKSEncoding{Tscale}(zero(ℛ))
- 8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
- 0.0 + 0.0im
- 0.0 + 0.0im
- 0.0 + 0.0im
- 0.0 + 0.0im
- 0.0 + 0.0im
- 0.0 + 0.0im
- 0.0 + 0.0im
- 0.0 + 0.0im
- # Ok, we're ready to get started, but first we'll need some keys
- julia> kp = keygen(params)
- CKKS key pair
- julia> kp.priv
- CKKS private key
- julia> kp.pub
- CKKS public key
- # Alright, let's encrypt some things:
- julia> foreach(i->plain[i] = i+1, 0:7); plain
- 8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
- 1.0 + 0.0im
- 2.0 + 0.0im
- 3.0 + 0.0im
- 4.0 + 0.0im
- 5.0 + 0.0im
- 6.0 + 0.0im
- 7.0 + 0.0im
- 8.0 + 0.0im
- julia> c = encrypt(kp.pub, plain)
- CKKS ciphertext (length 2, encoding
- CKKSEncoding{FixedRational{1099511627776,T} where T})
- # And decrypt it again
- julia> decrypt(kp.priv, c)
- 8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
- 0.9999999999995506 - 2.7335193113350057e-16im
- 1.9999999999989408 - 3.885780586188048e-16im
- 3.000000000000205 + 1.6772825551165524e-16im
- 4.000000000000538 - 3.885780586188048e-16im
- 4.999999999998865 + 8.382500573679615e-17im
- 6.000000000000185 + 4.996003610813204e-16im
- 7.000000000001043 - 2.0024593503998215e-16im
- 8.000000000000673 + 4.996003610813204e-16im
- # Note that we had some noise. Let's go through all the primitive operations we'll need:
- julia> decrypt(kp.priv, c+c)
- 8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
- 1.9999999999991012 - 5.467038622670011e-16im
- 3.9999999999978817 - 7.771561172376096e-16im
- 6.00000000000041 + 3.354565110233105e-16im
- 8.000000000001076 - 7.771561172376096e-16im
- 9.99999999999773 + 1.676500114735923e-16im
- 12.00000000000037 + 9.992007221626409e-16im
- 14.000000000002085 - 4.004918700799643e-16im
- 16.000000000001346 + 9.992007221626409e-16im
- julia> csq = c*c
- CKKS ciphertext (length 3, encoding CKKSEncoding{FixedRational{1208925819614629174706176,T} where T})
- julia> decrypt(kp.priv, csq)8-element CKKSEncoding{FixedRational{1208925819614629174706176,T} where T} with indices 0:7:
- 0.9999999999991012 - 2.350516767363621e-15im
- 3.9999999999957616 - 5.773159728050814e-15im
- 9.000000000001226 - 2.534464540987068e-15im
- 16.000000000004306 - 2.220446049250313e-15im
- 24.99999999998865 + 2.0903753311370056e-15im
- 36.00000000000222 + 4.884981308350689e-15im
- 49.000000000014595 + 1.0182491378134327e-15im
- 64.00000000001077 + 4.884981308350689e-15im
這很簡單!敏銳的讀者可能已經注意到了 csq 和之前的密文看起來有點不同。尤其是,它是「長度為 3」的密文,范圍也更大。要說明它們是什么,以及它們是做什么用的有點太過復雜。我只想說,在進一步計算之前,我們要得讓這些值降下來,否則我們會盡密文中的「空間」。幸運的是,有一種方法可以解決這兩個問題:
- # To get back down to length 2, we need to `keyswitch` (aka
- # relinerarize), which requires an evaluation key. Generating
- # this requires the private key. In a real application we would
- # have generated this up front and sent it along with the encrypted
- # data, but since we have the private key, we can just do it now.
- julia> ek = keygen(EvalMultKey, kp.priv)
- CKKS multiplication key
- julia> csq_length2 = keyswitch(ek, csq)
- CKKS ciphertext (length 2, encoding
- CKKSEncoding{FixedRational{1208925819614629174706176,T} where T})
- # Getting the scale back down is done using modswitching.
- julia> csq_smaller = modswitch(csq_length2)
- CKKS ciphertext (length 2, encoding
- CKKSEncoding{FixedRational{1.099511626783e12,T} where T})
- # And it still decrypts correctly (though note we've lost some precision)
- julia> decrypt(kp.priv, csq_smaller)
- 8-element CKKSEncoding{FixedRational{1.099511626783e12,T} where T} with indices 0:7:
- 0.9999999999802469 - 5.005163520332181e-11im
- 3.9999999999957723 - 1.0468514951188039e-11im
- 8.999999999998249 - 4.7588542623100616e-12im
- 16.000000000023014 - 1.0413447889166631e-11im
- 24.999999999955193 - 6.187833723406491e-12im
- 36.000000000002345 + 1.860733715346631e-13im
- 49.00000000001647 - 1.442396043149794e-12im
- 63.999999999988695 - 1.0722489563648028e-10im
- julia> ℛ # Remember the ring we initially created
- ℤ₁₃₂₉₂₂₇₉₉₇₅₆₈₀₈₁₄₅₇₄₀₂₇₀₁₂₀₇₁₀₄₂₄₈₂₅₇/(x¹⁶ + 1)
- julia> ToyFHE.ring(csq_smaller) # It shrunk!
- ℤ₁₂₀₈₉₂₅₈₂₀₁₄₄₅₉₃₇₇₉₃₃₁₅₅₃/(x¹⁶ + 1)
我們要做的最后一步運算是:旋轉。就像上文的密鑰轉換(KeySwitching),在這里也需要評估密鑰(也稱為伽羅瓦(galois)密鑰):
- julia> gk = keygen(GaloisKey, kp.priv; steps=2)
- CKKS galois key (element 25)
- julia> decrypt(circshift(c, gk))
- decrypt(kp, circshift(c, gk))
- 8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
- 7.000000000001042 + 5.68459112632516e-16im
- 8.000000000000673 + 5.551115123125783e-17im
- 0.999999999999551 - 2.308655353580721e-16im
- 1.9999999999989408 + 2.7755575615628914e-16im
- 3.000000000000205 - 6.009767921608429e-16im
- 4.000000000000538 + 5.551115123125783e-17im
- 4.999999999998865 + 4.133860996136768e-17im
- 6.000000000000185 - 1.6653345369377348e-16im
- # And let's compare to doing the same on the plaintext
- julia> circshift(plain, 2)
- 8-element OffsetArray(::Array{Complex{Float64},1}, 0:7) with eltype Complex{Float64} with indices 0:7:
- 7.0 + 0.0im
- 8.0 + 0.0im
- 1.0 + 0.0im
- 2.0 + 0.0im
- 3.0 + 0.0im
- 4.0 + 0.0im
- 5.0 + 0.0im
- 6.0 + 0.0im
好了,我們已經了解了同態加密庫的基本用法。在思考如何用這些原語進行神經網絡推斷之前,我們先觀察并訓練我們需要使用的神經網絡。
機器學習模型
如果你不熟悉機器學習或 Flux.jl 機器學習庫,我建議你先快速閱讀一下 Flux.jl 文檔或我們在 JuliaAcademy 上發布的免費機器學習介紹課程,因為我們只會討論在加密數據上運行模型所做的更改。
我們將以 Flux 模型空間中卷積神經網絡的例子為出發點。在這個模型中,訓練循環、數據預處理等操作都不變,只是輕微地調整模型。我們要用的模型是:
- function reshape_and_vcat(x)
- let y=reshape(x, 64, 4, size(x, 4))
- vcat((y[:,i,:] for i=axes(y,2))...)
- end
- end
- model = Chain(
- # First convolution, operating upon a 28x28 image
- Conv((7, 7), 1=>4, stride=(3,3), x->x.^2),
- reshape_and_vcat,
- Dense(256, 64, x->x.^2),
- Dense(64, 10),
- )
該模型與「安全外包矩陣的計算及其在神經網絡上與應用」(Secure Outsourced Matrix Computation and Application to Neural Networks)文中所用的模型基本相同,它們用相同的加密方案演示了相同的模型,但有兩個區別:(1)他們加密了模型而我們(為簡單起見)沒有對模型加密;(2)我們在每一層之后都有偏置向量(這也是 Flux 的默認行為),我不確定這種行為對本文評估的模型是否是這樣。也許是因為(2),我們模型的準確率才略高(98.6% vs 98.1%),但這也可能僅僅是因為超參數的差異。
「x.^2」激活函數也是一個不尋常的特征(對那些有機器學習背景的人來說)。這里更常用的選擇可能是「tanh」、「relu」或者其他更高級的函數。然而,盡管這些函數(尤其是 relu)可以更容易地評估明文值,但評估加密數據的計算開銷則相當大(基本上是評估多項式近似值)。幸運的是,「x.^2」可以很好地滿足我們的目的。
其余的訓練循環基本上是相同的。我們從模型中刪除了「softmax」,取而代之的是「logitcrossentropy」損失函數(當然也可以保留它,在客戶端解密后再評估「softmax」)。訓練模型的完整代碼見 GitHub,在近期發布的 GPU 上只需要幾分鐘就可以完成訓練。
代碼地址:https://github.com/JuliaComputing/ToyFHE.jl/blob/master/examples/encrypted_mnist/train.jl
高效地計算
好了,現在已經明確了我們需要做什么,接下來看看我們要做哪些運算:
- 卷積
- 元素平方
- 矩陣乘法
我們在上文中已經看到了,元素平方操作是很簡單的,所以我們按順序處理剩下的兩個問題。在整個過程中,假設批處理大小(batch size)為 64(你可能注意到了,我們有策略地選擇模型參數和批處理大小,從而充分利用 4096 元素向量的優勢,這是我們從實際的參數選擇中得到的)。
卷積
讓我們回顧一下卷積是如何工作的。首先,取原始輸入數組中的一些窗口(本例中為 7*7),窗口中的每個元素跟卷積掩模的元素相乘。然后移動窗口(本例中步長為 3,所以將窗口移動 3 個元素)。重復這個過程(用相同的卷積掩模)。下面的動畫說明了以(2,2)的步長進行 3*3 卷積的過程(藍色數組是輸入,綠色數組是輸出)。
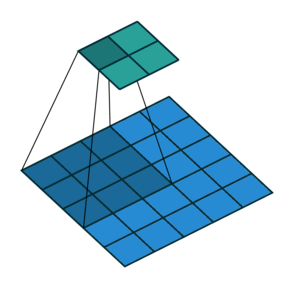
另外,我們將卷積分成 4 個不同的「通道」(這意味著用不同的卷積掩模,將卷積又重復了 3 次)
好了,現在我們已經知道了要做什么,接下來考慮一下該如何實現。幸運的是,卷積是我們模型中的第一步運算。因此,可以在加密數據之前(無需模型權重)先在客戶端上預處理,來節省一些工作。具體而言,我們將執行以下操作:
- 預先計算每個卷積窗口(即從原始圖像中提取 7*7 的窗口),從每個輸入圖像中得到 64 個 7*7 的矩陣(注意要在步長為 2 的情況下得到 7*7 的窗口,要評估 28*28 的輸入圖像的話,要計算 8*8 的卷積窗口)
- 將每個窗口中的相同位置收集到一個向量中,即對每張圖來說,都會有包含 64 個元素的向量,或當批處理大小為 64 時,會得到 64*64 的元素向量(即,共有 49 個 64*64 的矩陣)
- 加密
然后卷積就變成了整個矩陣和適當掩碼元素的標量乘法,對這 49 個元素求和,得到了卷積的結果。這個方案是這樣實現的(在明文上):
- function public_preprocess(batch)
- ka = OffsetArray(0:7, 0:7)
- # Create feature extracted matrix
- I = [[batch[i′*3 .+ (1:7), j′*3 .+ (1:7), 1, k] for i′=ka, j′=ka] for k = 1:64]
- # Reshape into the ciphertext
- Iᵢⱼ = [[I[k][l...][i,j] for k=1:64, l=product(ka, ka)] for i=1:7, j=1:7]
- end
- Iᵢⱼ = public_preprocess(batch)
- # Evaluate the convolution
- weights = model.layers[1].weight
- conv_weights = reverse(reverse(weights, dims=1), dims=2)
- conved = [sum(Iᵢⱼ[i,j]*conv_weights[i,j,1,channel] for i=1:7, j=1:7) for channel = 1:4]
- conved = map(((x,b),)->x .+ b, zip(conved, model.layers[1].bias))
這樣的實現(對維度重新排序的模)給出了相同的答案,但是用了這樣的操作:
- model*.*layers[*1*](batch)
加入加密操作后,我們得到:
- Iᵢⱼ = public_preprocess(batch)
- C_Iᵢⱼ = map(Iᵢⱼ) do Iij
- plain = CKKSEncoding{Tscale}(zero(plaintext_space(ckks_params)))
- plain .= OffsetArray(vec(Iij), 0:(N÷2-1))
- encrypt(kp, plain)
- end
- weights = model.layers[1].weight
- conv_weights = reverse(reverse(weights, dims=1), dims=2)
- conved3 = [sum(C_Iᵢⱼ[i,j]*conv_weights[i,j,1,channel] for i=1:7, j=1:7) for channel = 1:4]
- conved2 = map(((x,b),)->x .+ b, zip(conved3, model.layers[1].bias))
- conved1 = map(ToyFHE.modswitch, conved2)
注意,由于權重是公開的,所以不需要密鑰轉換,因此沒有擴展密文的長度。
矩陣乘法
接下來看看矩陣乘法是如何實現的。我們利用這樣的事實——可以旋轉向量中的元素,來重排序乘法索引。特別是,要考慮向量中矩陣元素的行優先排序。然后,如果以行大小的倍數移動向量,就可以得到列旋轉的效果,這可以提供充足的原語來實現矩陣乘法(至少是方陣)。我們不妨試一下:
- function matmul_square_reordered(weights, x)
- sum(1:size(weights, 1)) do k
- # We rotate the columns of the LHS and take the diagonal
- weight_diag = diag(circshift(weights, (0,(k-1))))
- # We rotate the rows of the RHS
- x_rotated = circshift(x, (k-1,0))
- # We do an elementwise, broadcast multiply
- weight_diag .* x_rotated
- end
- end
- function matmul_reorderd(weights, x)
- sum(partition(1:256, 64)) do range
- matmul_square_reordered(weights[:, range], x[range, :])
- end
- end
- fc1_weights = model.layers[3].W
- x = rand(Float64, 256, 64)
- @assert (fc1_weights*x) ≈ matmul_reorderd(fc1_weights, x)
當然,對于一般的矩陣乘法,我們可能需要更好的方法,但是在本例中,現在這種程度就已經足夠了。
優化代碼
至此,我們設法將所有內容整合在一起,而且也確實奏效了。這里提供了代碼作為參考(省略了參數選擇等設置):
- ek = keygen(EvalMultKey, kp.priv)
- gk = keygen(GaloisKey, kp.priv; steps=64)
- Iᵢⱼ = public_preprocess(batch)
- C_Iᵢⱼ = map(Iᵢⱼ) do Iij
- plain = CKKSEncoding{Tscale}(zero(plaintext_space(ckks_params)))
- plain .= OffsetArray(vec(Iij), 0:(N÷2-1))
- encrypt(kp, plain)
- end
- weights = model.layers[1].weight
- conv_weights = reverse(reverse(weights, dims=1), dims=2)
- conved3 = [sum(C_Iᵢⱼ[i,j]*conv_weights[i,j,1,channel] for i=1:7, j=1:7) for channel = 1:4]
- conved2 = map(((x,b),)->x .+ b, zip(conved3, model.layers[1].bias))
- conved1 = map(ToyFHE.modswitch, conved2)
- Csqed1 = map(x->x*x, conved1)
- Csqed1 = map(x->keyswitch(ek, x), Csqed1)
- Csqed1 = map(ToyFHE.modswitch, Csqed1)
- function encrypted_matmul(gk, weights, x::ToyFHE.CipherText)
- result = repeat(diag(weights), inner=64).*x
- rotated = x
- for k = 2:64
- rotated = ToyFHE.rotate(gk, rotated)
- result += repeat(diag(circshift(weights, (0,(k-1)))), inner=64) .* rotated
- end
- result
- end
- fq1_weights = model.layers[3].W
- Cfq1 = sum(enumerate(partition(1:256, 64))) do (i,range)
- encrypted_matmul(gk, fq1_weights[:, range], Csqed1[i])
- end
- Cfq1 = Cfq1 .+ OffsetArray(repeat(model.layers[3].b, inner=64), 0:4095)
- Cfq1 = modswitch(Cfq1)
- Csqed2 = Cfq1*Cfq1
- Csqed2 = keyswitch(ek, Csqed2)
- Csqed2 = modswitch(Csqed2)
- function naive_rectangular_matmul(gk, weights, x)
- @assert size(weights, 1) < size(weights, 2)
- weights = vcat(weights, zeros(eltype(weights), size(weights, 2)-size(weights, 1), size(weights, 2)))
- encrypted_matmul(gk, weights, x)
- end
- fq2_weights = model.layers[4].W
- Cresult = naive_rectangular_matmul(gk, fq2_weights, Csqed2)Cresult = Cresult .+ OffsetArray(repeat(vcat(model.layers[4].b,
- zeros(54)), inner=64), 0:4095)
雖然代碼看起來不是很清晰,但是如果你已經進行到這一步了,那你就應該理解這個流程中的每一步。
現在,把注意力轉移到可以讓這一切更好理解的抽象上。我們先跳出密碼學和機器學習領域,考慮編程語言設計的問題。Julia 可以實現強大的抽象,我們可以利用這一點構建一些抽象。例如,可以將整個卷積提取過程封裝為自定義數組類型:
- using BlockArrays
- """
- ExplodedConvArray{T, Dims, Storage} <: AbstractArray{T, 4}
- Represents a an `nxmx1xb` array of images, but rearranged into a
- series of convolution windows. Evaluating a convolution compatible
- with `Dims` on this array is achievable through a sequence of
- scalar multiplications and sums on the underling storage.
- """
- struct ExplodedConvArray{T, Dims, Storage} <: AbstractArray{T, 4}
- # sx*sy matrix of b*(dx*dy) matrices of extracted elements
- # where (sx, sy) = kernel_size(Dims)
- # (dx, dy)=output_size(DenseConvDims(...))
- cdims::Dims
- x::Matrix{Storage}
- function ExplodedConvArray{T, Dims, Storage}(cdims::Dims, storage::Matrix{Storage}) where {T, Dims, Storage}
- @assert all(==(size(storage[1])), size.(storage))
- new{T, Dims, Storage}(cdims, storage)
- end
- end
- Base.size(ex::ExplodedConvArray) = (NNlib.input_size(ex.cdims)..., 1, size(ex.x[1], 1))
- function ExplodedConvArray{T}(cdims, batch::AbstractArray{T, 4}) where {T}
- x, y = NNlib.output_size(cdims)
- kx, ky = NNlib.kernel_size(cdims)
- stridex, stridey = NNlib.stride(cdims)
- kax = OffsetArray(0:x-1, 0:x-1)
- kay = OffsetArray(0:x-1, 0:x-1)
- I = [[batch[i′*stridex .+ (1:kx), j′*stridey .+ (1:ky), 1, k] for i′=kax, j′=kay] for k = 1:size(batch, 4)]
- Iᵢⱼ = [[I[k][l...][i,j]
- for k=1:size(batch, 4), l=product(kax, kay)] for (i,j) in product(1:kx, 1:ky)]
- ExplodedConvArray{T, typeof(cdims), eltype(Iᵢⱼ)}(cdims, Iᵢⱼ)
- end
- function NNlib.conv(x::ExplodedConvArray{<:Any, Dims},
- weights::AbstractArray{<:Any, 4}, cdims::Dims) where {Dims<:ConvDims}
- blocks = reshape([
- Base.ReshapedArray(sum(x.x[i,j]*weights[i,j,1,channel] for i=1:7, j=1:7), (NNlib.output_size(cdims)...,1,size(x, 4)), ()) for channel = 1:4 ],(1,1,4,1))
- BlockArrays._BlockArray(blocks, BlockArrays.BlockSizes([8], [8], [1,1,1,1], [64]))
- end
注意,如原始代碼所示,這里用 BlockArrays 將 8*8*4*64 的數組表示成 4 個 8*8*1*64 的數組。所以現在,我們已經得到了第一個步驟更好的表征(至少是在未加密數組上):
- julia> cdims = DenseConvDims(batch, model.layers[1].weight; stride=(3,3), padding=(0,0,0,0), dilation=(1,1))
- DenseConvDims: (28, 28, 1) * (7, 7) -> (8, 8, 4), stride: (3, 3) pad: (0, 0, 0, 0), dil: (1, 1), flip: false
- julia> a = ExplodedConvArray{eltype(batch)}(cdims, batch);
- julia> model(a)
- 10×64 Array{Float32,2}:
- [snip]如何將這種表征帶入加
如何將這種表征帶入加密的世界呢?我們需要做兩件事:
1. 我們想以這樣的方式加密結構體(ExplodedConvArray),以致于對每個字段(field)都能得到一個密文。然后,通過查詢該函數在原始結構上執行的操作,在加密的結構體上進行運算,并直接進行相同的同態操作。
2. 我們希望攔截某些在加密的上下文中以不同方式執行的操作。
幸運的是 Julia 提供了可以同時執行這兩個操作的抽象:使用 Cassette.jl 機制的編譯器插件。它是如何起作用的,以及如何使用它,都有些復雜,本文中不再深入介紹這部分內容。簡言之,你可以定義上下文(即「Excrypted」,然后定義在這樣的上下文中,運算是如何起作用的規則)。例如,第二個要求可以寫成:
所有這一切的最終結果是,用戶可以以最少的手工工作,寫完整個內容:
當然,就算經過了以上處理,代碼也不是最優的。加密系統的參數(例如 ℛ 環,什么時候模轉換,什么時候密鑰轉換等)表現出了在答案的準確性、安全性以及性能之間的取舍,而且參數很大程度上取決于正在運行的代碼。一般來說,人們希望編譯器能分析將要運行的加密代碼,為給定的安全等級和所需精度提出參數建議,然后用戶以最少的人工操作來生成代碼。
結語
對于任何系統來說,安全地自動執行任意計算都是一項艱巨的任務,但 Julia 的元編程功能和友好的語法都讓它成為合適的開發平臺。RAMPARTS 系統已經做了一些嘗試,將簡單的 Julia 代碼編譯到 PALISADE FHE 庫中。「Julia Computing」正在與 RAMPARTS 背后的專家在 Verona 平臺上合作,最近已經發布了下一代版本。在過去的一年中,同態加密系統的性能才達到能以實際可用的速度評估有趣計算的程度。一扇嶄新的大門就此打開。隨著算法、軟件和硬件的進步,同態加密必然會成為保護數百萬用戶隱私的主流技術。
RAMPARTS 論文:https://eprint.iacr.org/2019/988.pdf
報告:https://www.youtube.com/watch?v=_KLlMg6jKQg



















