大腦也在用分布式強化學習?DeepMind新研究登上《Nature》
分布式強化學習是智能體在圍棋、星際爭霸等游戲中用到的技術,但 DeepMind 的一項研究表明,這種學習方式也為大腦中的獎勵機制提供了一種新的解釋,即大腦也應用了這種算法。這一發現驗證了分布式強化學習的潛力,同時也使得 DeepMind 的研究人員越發堅信,「現在的 AI 研究正走在正確的道路上」。
多巴胺是人們所熟悉的大腦快樂信號。如果事情的進展好于預期,大腦釋放的多巴胺也會增多。
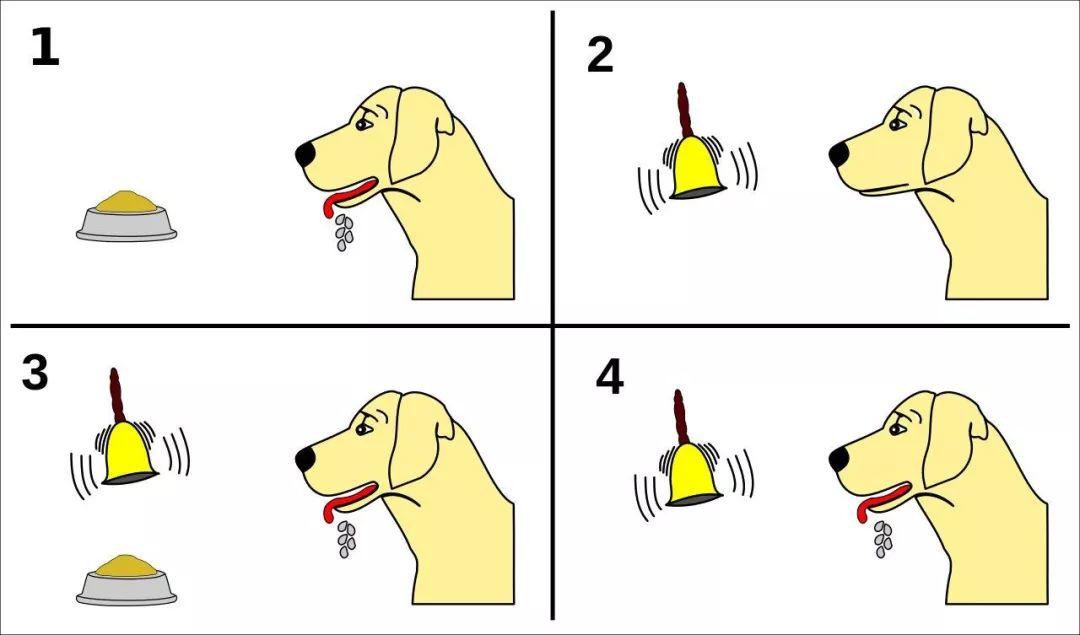
在人腦中存在獎勵路徑,這些路徑控制我們對愉悅事件的反應,并通過釋放多巴胺的神經元進行介導。例如,在著名的巴布洛夫的狗實驗中,當狗聽到鈴聲便開始分泌口水時,這一反應并非已經獲得了獎勵,而是大腦中的多巴胺細胞對即將到來的獎勵產生的一種預測。
之前的研究認為,這些多巴胺神經元對獎勵的預測應當是相同的。
但近日,DeepMind 的研究人員通過使用分布式強化學習算法發現,每個多巴胺神經元對獎勵的預測很不相同,它們會被調節到不同水平的「悲觀」和「樂觀」狀態。研究者希望通過這套算法研究并解釋多巴胺細胞對大腦的行為、情緒等方面的影響。這份研究成果昨日登上了《Nature》。

Nature 論文鏈接:https://www.nature.com/articles/s41586-019-1924-6
強化學習算法和多巴胺獎懲機制研究
強化學習算是神經科學與 AI 相連接的最早也是最有影響力的研究之一。上世紀 80 年代末期,計算機科學研究者試圖開發一種算法,這種算法僅依靠獎懲反饋作為訓練信號,就可以單獨學會如何執行復雜的行為。這些獎勵會加強使其受益的任何行為。
解決獎勵預測問題的重要突破是時序差分算法(TD),TD 不會去計算未來的總體回報,它嘗試預測當前獎勵和未來時刻預期獎勵之和。當下一個時刻來臨時,將新的預測結果與預期中的相比,如果有出入,算法會計算二者之間的差異,并用此「時序差分」將舊版本的預測調整為新的預測。
不斷訓練之后,「預期」和「現實」會逐漸變得更加匹配,整個預測鏈條也會變得越來越準確。
與此同時,很多神經科學研究者們,專注于多巴胺神經元的行為研究。當面對即將到來的獎勵時,多巴胺神經元會將「預測」和「推斷」的值發送給許多大腦區域。
這些神經元的「發送」行為與獎勵的大小有一定關系,但這些反應常常依靠的是外部感性信息輸入,并且在給定任務中的表現也會隨著生物體經驗的豐富而改變。例如,對于特定的刺激產生的獎勵預測變少了,因為大腦已經習慣了。
一些研究者注意到,某些多巴胺神經元的反應揭示了獎勵預測的漏洞:相比于被訓練應該生成的那種「預期」,它們實際發送的預期總是或多或少,和訓練的預期不太一樣。
于是這些研究者建議大腦使用 TD 算法去計算獎勵預測的誤差,通過多巴胺信號發送給大腦各個部位,以此來驅動學習行為。從那時起,多巴胺的獎勵預測理論逐漸在數以萬計的實驗中得到證實,并已經成為神經科學領域最成功的定量理論之一。
自 TD 被應用于多巴胺獎懲機制研究以來,計算機科學家在不斷優化從獎懲機制中學習的算法。自從 2013 年以來,深度強化學習開始受到關注:在強化學習中使用深度神經網絡來學習更強的表示,使強化學習算法解決了精巧性和實用度等問題。
分布式強化學習是一種能讓神經網絡更好地進行強化學習的算法之一。在許多的情況下,尤其是很多現實情況中,未來獎勵的結果實際上是依據某個特定的行為而不是一個完全已知的量進行的預測,它具有一定的隨機性。
圖 1 是一個示例,一個由計算機控制的小人正在越過障礙物,無法得知它是會掉落還是跨越到另一端。所以在這里,預測獎勵就有兩種,一種代表墜落的可能性,一種代表成功抵達另一邊的可能性。
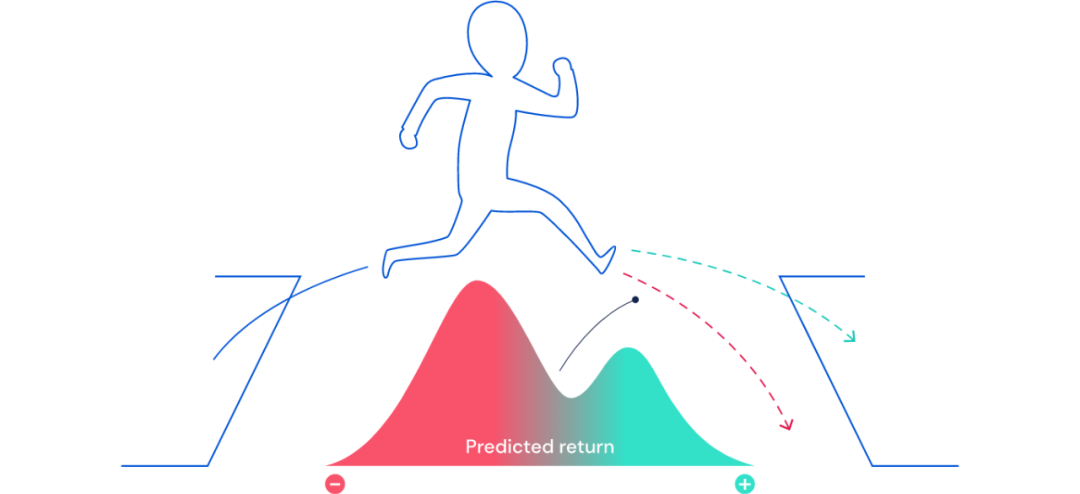
圖 1:當未來不確定時,可以用概率分布的方式去描述未來獎勵。未來的某一部分可能會是「好的(綠色)」,其他則代表「不好(紅色)」。借助各種 TD 算法,分布式強化學習可以學習關于這個獎勵預期的分布情況。
在這種情況下,標準 TD 算法學習預測將來的平均獎勵,而不能獲得潛在回報的雙峰分布(two-peaked distribution)。但是分布式強化學習算法則能夠學習預測將來的全部獎勵。上圖 1 描述了由分布式智能體學習到的獎勵預測。
因此,分布式強化學習算法在多巴胺研究中的應用就進入了研究者們的視野。
分布式 TD:性能更好的強化學習算法
新的研究采用了一種分布式強化學習算法,與標準 TD 非常類似,被稱為分布式 TD。標準 TD 學習單個預測(平均期望預測),而分布式 TD 學習一系列不同的預測。而分布式 TD 學習預測的方法與標準 TD 相同,即計算能夠描述連續預測之間差異的獎勵預測誤差,但是每個預測器對于每個獎勵預測誤差都采用不同的轉換。
例如,當獎勵預測誤差為正時(如下圖 2A 所示),一些預測器會有選擇性地「擴增」或「增持」獎勵預測誤差。這使得預測器學習更樂觀的獎勵預測,從而對應獎勵分布中的更高部分。但同時,另一些預測器擴增它們的負獎勵預測誤差(如下圖 2A 所示),所以學習更悲觀的獎勵預測。因此具有不同悲觀和樂觀權重的一系列預測器構成了下圖 2B 和 2C 的完整獎勵分布圖。
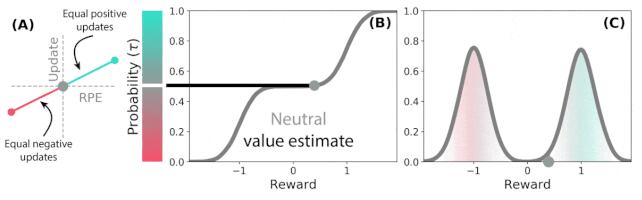
圖 2:分布式 TD 學習對獎勵分布不同部分的價值估計。
除了簡潔性之外,分布式強化學習還有另一項優勢,當它與深度神經網絡結合時會非常強大。過去五年,基于原始深度強化學習 DQN 智能體的算法有了很多進展,并且這些算法經常在 Atari 2600 游戲中的 Atari-57 基準測試集上進行評估,證明了分布式強化學習算法的性能優勢。
多巴胺研究中的分布式 TD
由于分布式 TD 在人工神經網絡中具有很好的性能,因此本研究考慮采用分布式 TD,嘗試研究大腦的獎懲機制。
在研究中,研究者聯合哈佛大學,對老鼠多巴胺細胞的記錄進行分析。在任務中,這些老鼠獲得數量未知的獎勵(如下圖 4 所示)。研究者的目的是評估多巴胺神經元的活動是否與標準 TD 或分布式 TD 更為一致。
以往的研究表明,多巴胺細胞改變它們的發放率(firing rate)來表明存在的預測誤差,即一個動物是否接收了比預期更多或更少的獎勵。我們知道,當獎勵被接收時,預測誤差應為零,也就是獎勵大小應與多巴胺細胞預測的一樣,因此對應的發放率也不應當改變。
對于每個多巴胺細胞,如果研究者確定了其基準發放率沒有改變,則其獎勵大小也可以被確定。這個關系被稱之為細胞的「逆轉點」。研究者想要弄清楚不同細胞之間的逆轉點是否也存在差異。
如下圖 4C 所示,細胞之間存在著明顯差異,一些細胞會預測非常大的獎勵,而另一些只預測出非常小的獎勵。相較于從記錄中固有隨機變化率所能預期的差異,細胞之間的實際差異要大得多。
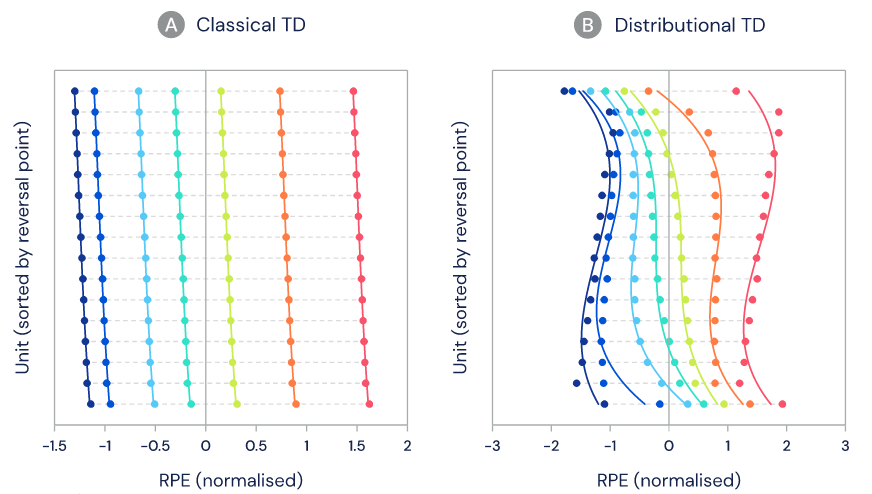
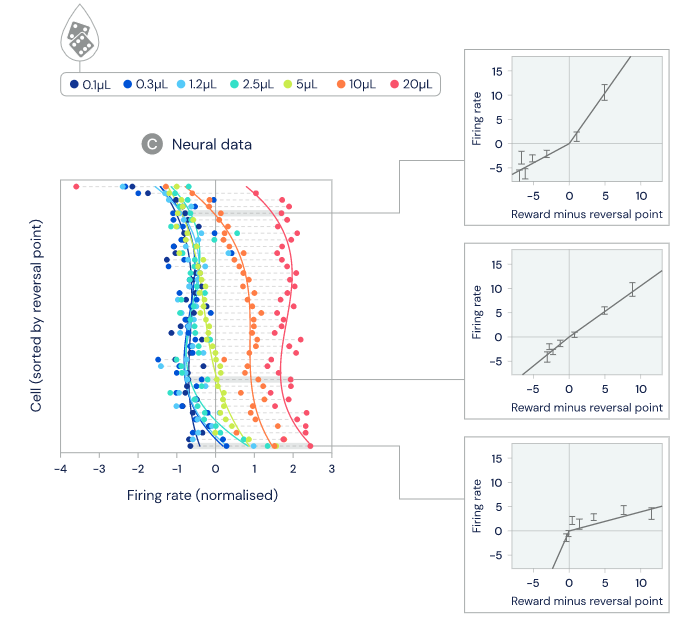
圖 4:在這項任務中,老鼠獲得的水獎勵(water reward)通過隨機方法確定,并可以調整,范圍是 0.1-20 UL。
在分布式 TD 中,獎勵預測中的這些差異是由正或負獎勵預測誤差的選擇性擴增引起的。擴增正獎勵預測可以獲得更樂觀的獎勵預測,而擴增負獎勵可以獲得更悲觀的預測。所以,研究者接下來測量了不同多巴胺細胞對正或負期望的擴增程度,并發現了細胞之間存在著噪聲也不能解釋的可靠多樣性。并且關鍵的一點是,他們發現擴增正獎勵預測誤差的同一些細胞也表現出了更高的逆轉點(上圖 4C 右下圖),也就是說,這些細胞期望獲得更高的獎勵。
最后,分布式 TD 理論預測,有著不同的逆轉點(reversal point)的細胞應該共同編碼學到的獎勵分配。因此研究人員希望能夠探究:是否可以從多巴胺細胞的發放率解碼出獎勵分配到不同細胞的分布。
如圖 5 所示,研究人員發現,只使用多巴胺細胞的放電速率,確實有可能重建獎勵的分布(藍色線條),這與老鼠執行任務時獎勵的實際分布(灰色區域)非常接近。
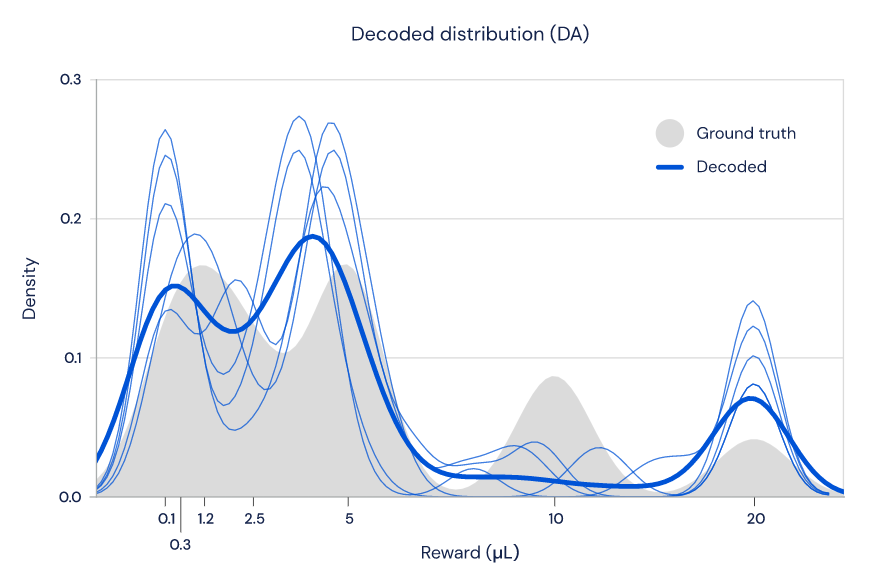
圖 5:多巴胺細胞群編碼了學到的獎勵分布的形狀。
總結
研究人員發現,大腦中的多巴胺神經元被調節到不同水平的「悲觀」和「樂觀」。如果它們是一個合唱團,那么所有的神經元不會唱同一個音域,而是彼此配合——每個神經元都有自己的音域,如男高音或女低音。在人工強化學習系統中,這種多樣化的調整創造了更加豐富的訓練信號,極大地加快了神經網絡的學習。研究人員推測,大腦可能出于同樣的原因使用這套機制。
大腦中分布式強化學習的存在可以為 AI 和神經科學的發展提供非常有趣的啟示。首先,這一發現驗證了分布式強化學習的潛力——大腦已經用到了這套算法。
其次,它為神經科學提出了新的問題。如果大腦選擇性地「傾聽」樂觀/悲觀多巴胺神經元會怎么樣呢?會導致沖動或抑郁嗎?大腦有強大的表征能力,這些表征是如何由分布式學習訓練出的呢?例如,一旦某個動物學會了分配獎勵的機制,在它的下游任務會如何使用這種表征?多巴胺細胞之間的樂觀情緒可變性與大腦中其他已知的可變形式存在什么關聯?這些問題都需要后續研究進一步解釋。
最后,DeepMind 的研究人員希望通過這些問題的提出和解答來促進神經科學的發展,進而為人工智能研究帶來益處,形成一個良性循環。