目前運維與測試領域有哪些新技術?
我覺得面對測試的態度是區分一個普通程序員和優秀程序員的重要標準。
現如今我們的程序和服務越來越龐大,光是單元測試 TDD 之類的就已經很難保證質量,不過這些都是 baseline,所以今天聊點新的話題。
說測試之前,我們先問下自己,為什么要測試?當然是為了找 Bug。看起來這是句廢話,但是仔細想想,如果我們能寫出 Bug-free 的程序不就好了嗎?何必那么麻煩。不過 100% 的 bug-free 肯定是不行的,那么我們有沒有辦法能夠盡可能地提升我們程序的質量?
舉個例子,我想到一個 Raft 的優化算法,與其等實現之后再測試,能不能在寫代碼前就知道這個算法理論上有沒有問題?辦法其實是有的,那就是形式化證明技術,比較常用的是 TLA+。
1. TLA+
TLA+ 背后的思想很簡單,TLA+ 會通過一套自己的 DSL(符號很接近數學語言)描述程序的初始狀態以及后續狀態之間的轉換關系,同時根據你的業務邏輯來定義在這些狀態切換中的不變量,然后 TLA+ 的 TLC model checker 對狀態機的所有可達狀態進行窮舉,在窮舉過程中不斷檢驗不變量約束是否被破壞。
舉個簡單的例子,分布式事務最簡單的兩階段提交算法,對于 TLA+ Spec 來說,需要你定義好初始狀態(例如事務要操作的 keys、有幾個并發客戶端等),然后定義狀態間跳轉的操作( Begin / Write / Read / Commit 等),最后定義不變量(例如任何處于 Committed 狀態的 write ops 一定是按照 commit timestamp 排序的,或者 Read 的操作一定不會讀到臟數據之類的),寫完以后放到 TLC Checker 里面運行,等待結果就好。
但是,我們活在一個不完美的世界,即使你寫出了完美的證明,也很難保證你就是對的。第一, Simulator 并沒有辦法模擬出無限多的 paticipants 和并發度, 一般也就是三五個;第二,聰明的你可能也看出來了,一般 TLA+ 的推廣文章也不會告訴你 Spec 的關鍵是定義不變量,如果不變量定義不完備,或者定義出錯,那么證明就是無效的。因此,我認為形式化驗證的意義在于讓工程師在寫代碼之前提高信心,在寫證明的過程中也能更加深對算法的理解,此外,如果在 TLC Checker 里就跑出異常,那就更好了。
目前 PingCAP 應該是國內唯一一個使用 TLA+ 證明關鍵算法,并且將證明的 Spec 開源出來的公司,大家可以參考 pingcap/tla-plus 這個 Repo。
2. Chaos Engineering
如果完美的證明不存在,那么 Deterministic 的測試存在嗎?我記得大概 2015 年在 PingCAP 成立前,我看到了一個 FoundationDB 關于他們的 Deterministic 測試的 演講。簡單來說他們用自己的 IO 處理和多任務處理框架 Flow 將代碼邏輯和操作系統的線程以及 IO 操作解耦,并通過集群模擬器做到了百分之百重現 Bug 出現時的事件順序,同時可以在模擬器中精確模擬各種異常,確實很完美。但是考慮到現實的情況,我們當時選擇使用的編程語言主要是 Go,很難或者沒有必要做類似 Flow 的事情 。所以我們選擇了從另一個方向解決這個問題,提升分布式環境下 Bug 的復現率,能方便復現的 Bug 就能好解決,這個思路也是最近幾年很火的 Chaos Engineering。做 Chaos Engineering 的幾個關鍵點:
定義穩態,記錄正常環境下的 workload 以及關注的重要指標。
定義系統穩態后,我們分為實驗組和對照組進行實驗,確認在理想的硬件情況下,無論如何操作實驗組,最后都會回歸穩態。
開始對底層的操作系統和網絡進行破壞,再重復實驗,觀察實驗組會不會回歸穩態。
道理大家都懂,但是實際做起來最大的問題在于如何將整個流程自動化。原因在于:一是靠手動的效率很低;二是正統的 Chaos Engineering 強調的是在生產環境中操作,如何控制爆炸半徑,這也是個比較重要的問題。
先說第一個問題,PingCAP 在實踐 Chaos Engineering 的初期,都是在物理機上通過腳本啟停服務,所有實驗都需要手動完成,耗時且非常低效,在資源利用上也十分不合理。這個問題我們覺得正好是 K8s 非常擅長的,于是我們開發了一個基于 K8s 的,內部稱為 Schrodinger 的自動化測試平臺,將 TiDB 集群的啟停鏡像化,另外將 TiDB 本身的 CI/CD,自動化測試用例的管理、Fault Injection 都統一了起來。這個項目還催生出一個好玩的子項目 Chaos Operator:我們通過 CRD 來描述 Chaos 的類型,然后在不同的物理節點上啟動一個 DaemonSets,這個 DaemonSets 就負責干擾 Pod,往對應的 Pod 里面注入一個 Sidecar,Sidecar 幫我們進行注入錯誤(例如使用 Fuse 來模擬 IO 異常,修改 iptable 制造網絡隔離等),破壞 Pod。近期我們也有計劃將 Chaos Operator 開源。
第二個問題,其實在我看來,有 Chaos Engineering 仍然還是不夠的,我們在長時間的對測試和質量的研究中發現提升測試質量的關鍵是如何發現更多的測試 workload。在早期我們大量依賴了 MySQL 和相關社區的集成測試,數量大概千萬級別,這個決定讓我們在快速迭代的同時保證質量,但是即使這樣還是不夠的,我們也在從學術界尋求答案. 例如引入并通過官方的 Jepsen Test ,再例如通過 SQLfuzz 自動生成合法 SQL 的語句加入到測試集中。
總之,比起寫業務邏輯,在分布式環境下寫測試 + 寫測試框架花費的精力可能一點都不少,甚至可能多很多(如果就從代碼量來說,TiDB 的測試相關的代碼行數可能比內核代碼行數多一個數量級),而且這是一個非常值得研究和投資的領域。另外一個問題是如何通過測試發現性能回退。我們的測試平臺中每天運行著一個名為 benchbot 的機器人,每天的回歸測試都會自動跑性能測試,對比每日的結果。這樣一來我們的工程師就能很快知道哪些變更導致了性能下降,以及得到一個長期性能變化趨勢。
3. eBPF
說完測試,另外一個相關的話題是 profiling 和分布式 tracing。tracing 看看 Google 的 Dapper 和開源實現 OpenTracing 就大概能理解,所以,我重點聊聊 profiling。最近這幾年我關注的比較多的是 eBPF (extended BPF) 技術。想象下,過去我們如果要開發一個 TCP filter,要么就自己寫一個內核驅動,要么就用 libpcap 之類的基于傳統 BPF 的庫,而傳統 BPF 只是針對包過濾這個場景設計的虛擬機,很難定制和擴展。
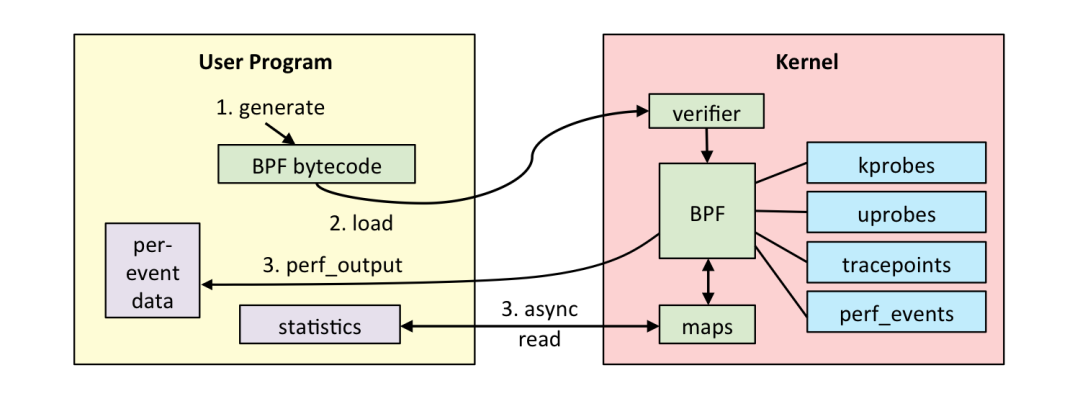
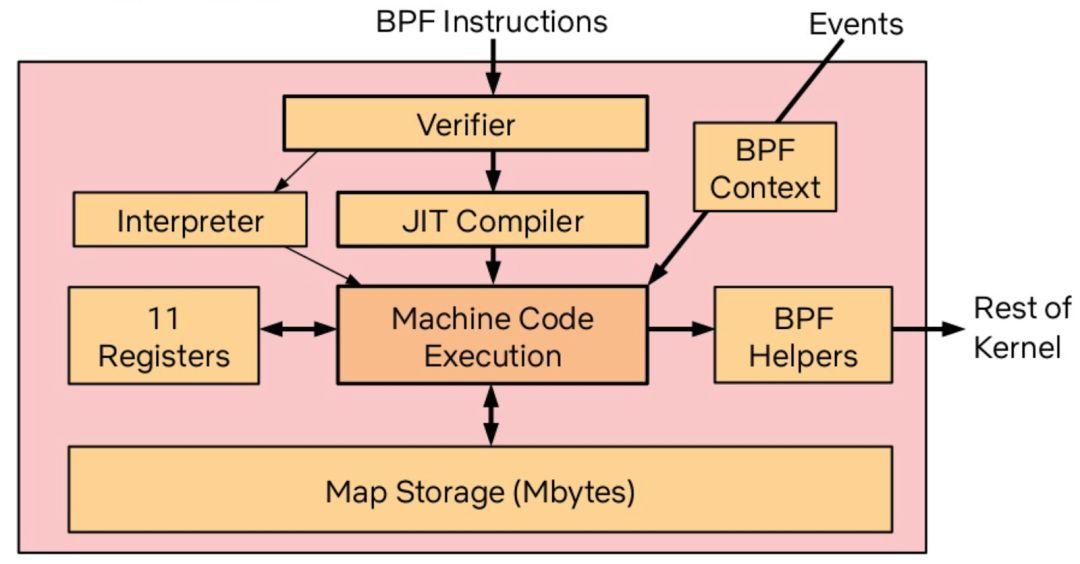
在這個背景下,eBPF 應運而生,eBPF 引入了 JIT 和寄存器,將 BPF 的功能進一步擴充,這背后的意義是,我們在內核中有一個安全的、高性能的、基于事件的、支持 JIT 的字節碼的虛擬機!這其實極大地降低了拓展內核能力的門檻,我們可以不用擔心在驅動中寫個異常把內核搞崩,我們也可以將給 llvm 用的 clang 直接編譯成 eBPF 對象,社區還有類似 bcc 這樣的基于 Python 的實用工具集……
過去其實大家是從系統狀態監控、防火墻這個角度認識 eBPF 的。沒錯,性能監控以及防火墻確實是目前 eBPF 的王牌場景,但是我大膽地預測未來不止于此,就像最近 Brendan Gregg 在他的 blog 里喊出的口號:BPF is a new type of software。可能在不久的未來,eBPF 社區能誕生出更多好玩的東西,例如我們能不能用 eBPF 來做個超高性能的 web server?能不能做個 CDN 加速器?能不能用 BPF 來重定義操作系統的進程調度?我喜歡 eBPF 的另一個重要原因是,第一次內核應用開發者可以無視內核的類型和版本,只要內核能夠運行 eBPF bytecode 就可以了,真正做到了一次編譯,各個內核運行。所以有一種說法是 BPF is eating Linux,也不是沒有道理 。
PingCAP 也已經默默地在 BPF 社區投入了很長時間,我們也將自己做的一些 bcc 工具開源了,詳情可以參考 pingcap/kdt 這個 repo。其中值得一提的是,我們的 bcc 工具之一 drsnoop 被 Brendan Gregg 的新書收錄了,也算是為社區做出了一點微小的貢獻。
上面聊的很多東西都是具體的技術,技術的落地離不開部署和運維,分布式系統的特性決定了維護的復雜度比單機系統大得多。在這個背景之下,我認為解法可能是:不可變基礎設施。
云和容器的普及讓 infrastructure as code 的理念得以變成現實,通過描述式的語言來創建可重復的部署體驗,這樣可重用的描述其實很方便在開源社區共享,而且由于這些描述幾乎是和具體的云的實現無關,對于跨云部署和混合數據中心部署的場景很適合。有些部署工具甚至誕生出自己的生態系統,例如 Terraform / Chef / Ansible。有一種說法戲稱現在的運維工程師都是 yaml 語言工程師,其實很有道理的:人總是會出錯,且傳統的基于 shell 腳本的運維部署受環境影響太大,shell 天然也不是一個非常嚴謹的語言。描述意圖,讓機器去干事情,才是能 scale 的正道。
4. 作者介紹
黃東旭:分布式系統專家,架構師,開源軟件作者。PingCAP 聯合創始人兼 CTO,知名開源項目 Codis / TiDB / TiKV 主要作者,曾就職于微軟亞洲研究院,網易有道及豌豆莢。2015 年創業,成立 PingCAP,致力于下一代開源分布式數據庫的研發工作,擅長分布式存儲系統設計與實現,高并發后端架構設計。