書本上學不到:萬臺服務器下運維怎樣做好監控?
作者簡介:
龔誠,58集團智能運維團隊負責人,高級技術經理。負責運維及自動化團隊的技術和管理工作。
背景
智能運維其實比較好的落地點是在監控領域,因為監控領域有大量的數據作為基礎,可以做大量的智能分析和處理需求。
我們在監控領域也有很多需求,對于大量的指標需要做異常檢測,指標檢測方式是不一樣的。
另外我們收到大量的告警需要進行一定的合并,并且從中摘取出重要的內容,有這么負責的調用鏈,負責的系統,不同的監控系統之間是有關系的,怎么樣從系統自動化的從各個關聯關系當中分析出哪個是關聯原因,哪些是衍生引起的,這也是比較重要的問題。
1、多維異常檢測
異常檢測在運維實踐中有著舉足輕重的地位,實時、準確的發現異常能夠幫助我們及時采取行動,最大限度減少故障的損失。
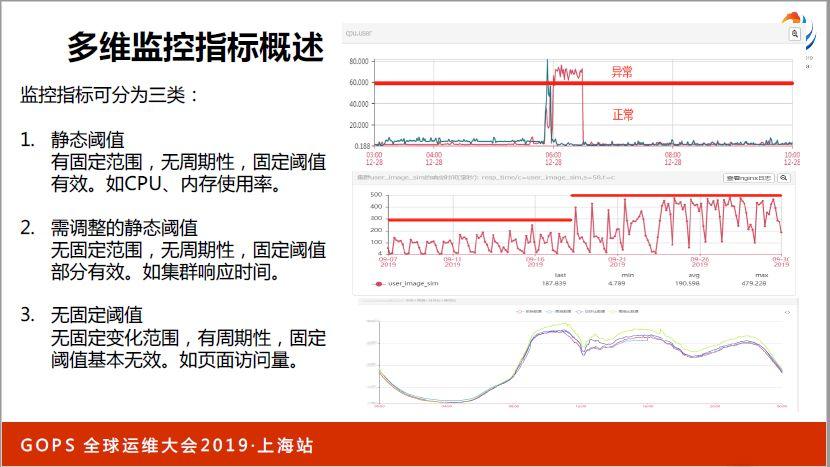
在監控領域中,其實最重要的一點是要能夠通過一些監控指標發現問題,當我們的系統越來越大越來越復雜的時候,想從繁雜的指標當中,幾百個監控策略中發現異常其實是非常困難的,尤其是最初開始使用靜態閾值的方式相對來說比較簡單。
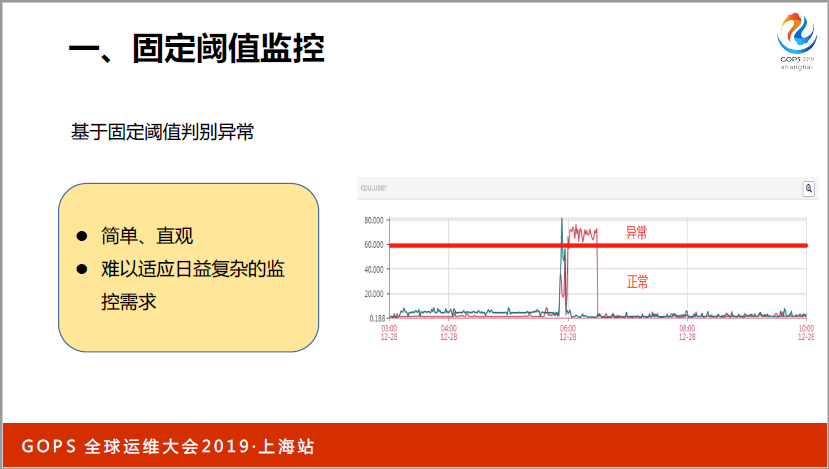
靜態閾值這種方式,初期對主機性能進行監控,對你的CPU和內存使用率進行監控,這種方式還是比較好的,我們可以通過人工方式確定資源使用率達到60%,基本上達到了安全水平線,再高就有風險,就需要告警了,這個指標也有一定的特點,取值是在0到100%之間,可以根據人工的方式,根據我們的經驗確定一個值,然后把它設立為一個告警閾值。
除此之外,當我們進行更多業務監控的時候,面臨的挑戰就更大了。
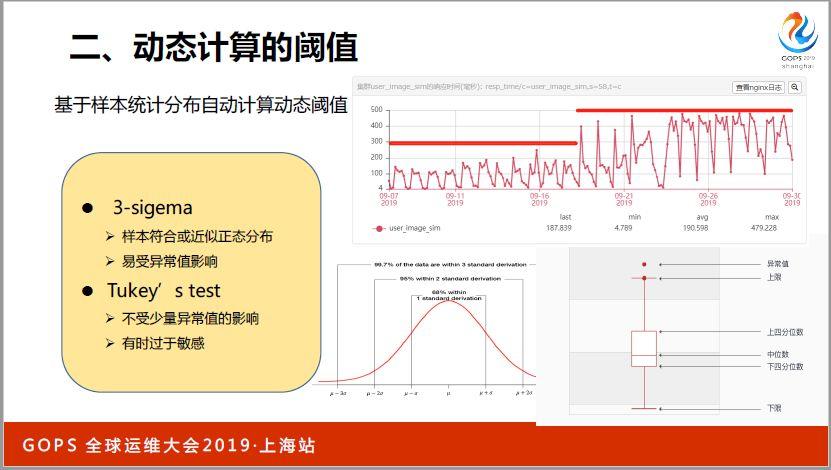
舉個例子,比如說第二幅圖里面,某些集訓由于處理的邏輯比較簡單,所以響應時間會比較低,正常來說,響應時間比較低,是不是設置閾值的時候,閾值也要設置的比較低,一旦發現異常可以馬上發現。
如果基于傳統的方式我們來解決這個問題,其實需要人工有很多分析,但是監控指標數量實在太多了,已經達到了人類不太好人工處理的地步了。怎么辦?我們采用一些基于統計的方法,我們后面再詳細來說一下,比較好解決了這個問題。
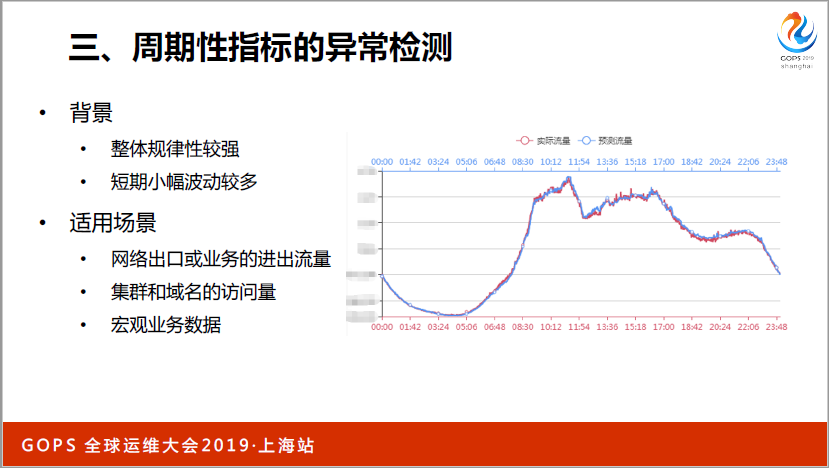
第三種監控指標是隨著每天用戶訪問量,發生變化的,當用戶訪問量比較小,自然數值就下降,達到用戶訪問高峰期的時候,數值就比較高,呈現波動性變化,很難用一個閾值來解決這個問題,我們利用機器學習的方法,學習歷史數據規律,采用分類模型的方式判斷是否有異常。
第一個比較簡單,固定閾值這種方式,好處是比較簡單直觀,壞處是難以適應日益復雜的需求。
第二個方面,某一個機群顯示時間,類似這種指標我們用統計判別的方式來設定是比較好的,其中比較好的方法也能夠比較好的識別出歷史數據大部分時間是分布在哪個區域,從而設定一個合適閾值的。
另外這種方式也有一定好處,當你集群行為發生變化的時候會自適應進行一些調整,比如說如果這個集群最開始響應時間比較低,自動生成閾值,自然也是比較低的,當前幾天突然出現響應時間增高,出現一個變化的時候,那自然是要出現一些告警的,這也是符合需求的,前幾天出現了一些顯示時間增大,我們肯定要進行一些告警,但是如果后續持續每天都出現這些問題的話,就說明這是沒有問題的,可能由于處理邏輯更加復雜了,所以響應時間就增常了。
我們通過統計最近幾天顯示時間歷史數據變化,從而重新生成和調整閾值,逐漸把閾值調高,這樣后續幾天就不會有異常發出了。
周期性指標異常檢測,由于這些數據的變化是隨著用戶的訪問量進行變化的,一般來說都是一些關鍵指標,用戶訪問的成交量、訂單量這些指標,對于運維比較關注的,像網絡出口流量和業務流量,以及集群和域名的訪問量,還有一些宏觀業務數據,相對來說,這種類型的指標如果能夠發現異常,并且有問題發出告警,產生的意義會更大一些。
這個事情具體怎么做,我們采用機器學習的方式,用最近一段時間的歷史數據通過對模型進行訓練,然后把實時數據拋到模型里面,從而得出當前數據是正常還是異常,從而發現這些異常。
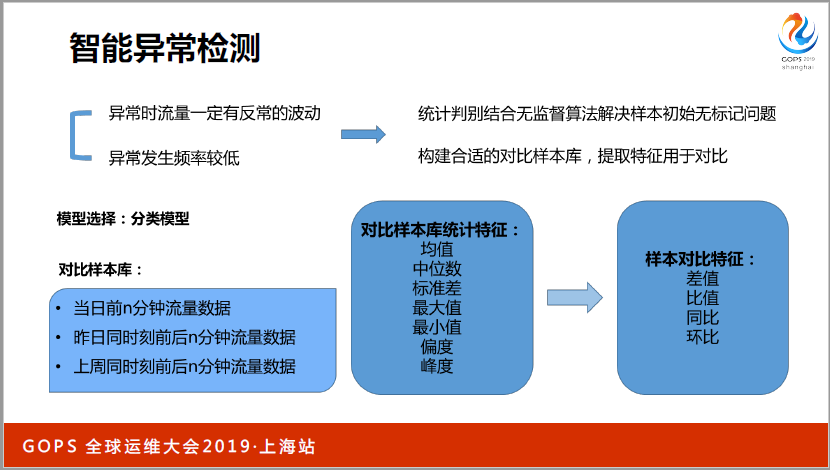
如果用機器學習的方式,是一種有監督學習的方式,運維過程當中指標的數量這么多,怎么樣標記這些數據,得到一個有標記的樣本庫,采用統計判別,首先得到一個基礎樣本庫,一個訓練集,然后經過一定處理,訓練模型,從而得到了通過分裂模型做異常檢測的任務,同時訓練一個回歸模型來得到曲線預測,實現這樣一種功能。
這里面體現了我們用到的對比樣本庫,以及我們選取的一些特征。
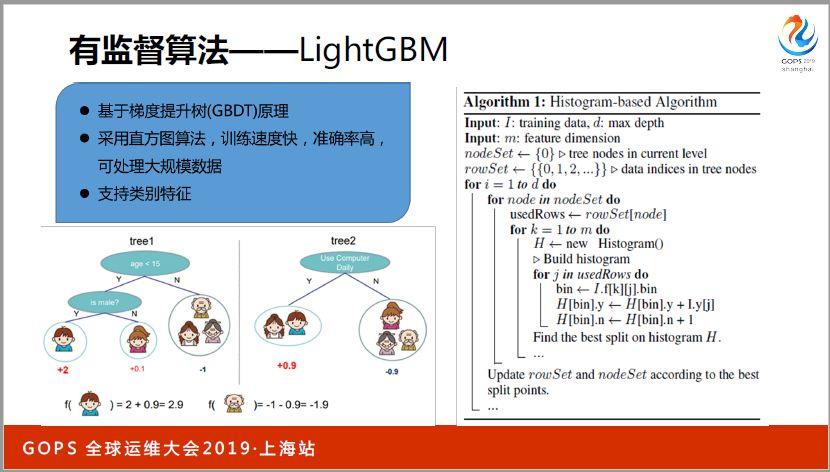
選取這些特征采取的算法是Lightgbm。
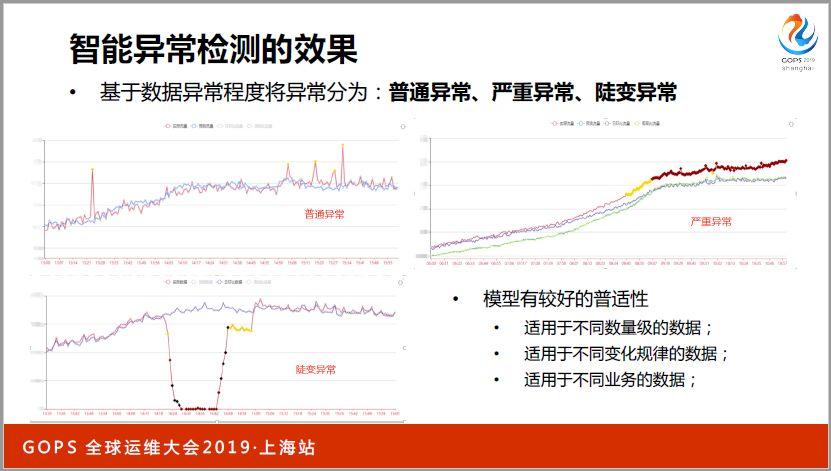
智能異常檢測的效果,普遍異常我們標記為黃色的點,如果出現一些嚴重的異常我們標志成紅色的點,這三個圖當中,異常等級不一樣,第一個圖是普通異常,偶爾有一個毛刺飆上去了,對于整個數據的影響是比較小的。
第二種是嚴重異常,說明一些應戶的推廣活動或者運營活動,也有可能是系統出現了某些方面的問題,導致流量下降。
第三種是陡變異常,這種陡變異常變化,一般來說比較致命,有可能是流量大幅度上升,突然大量攻擊流量,或者說流量突然下降,整個機房網絡這方面有問題了。針對不同類型的異常我們做不同的告警分級,普通的異常我們甚至不用太關注,對于嚴重異常我們可以用告警短信和微信的方式解決。對于特別嚴重的異常可以通過語音告警的方式來進行。
分類模型的方式進行異常檢測效果也是比較好的,尤其具有比較好的普世性。我們對于,尤其做業務指標監控,收入監控和產品線PV、UV監控,以及小的業務集群的監控,這種方式都可以實現,適用于不同級別的數據,包括網絡帶寬比較大,甚至幾十億級別的數據,對于某些業務集群,可能每天的QPS低峰的時候只有幾十,不到一百,所以可以很好解決這個問題。
2、智能告警合并
作為技術人員都有一個痛,系統出現異常的時候會出現很多告警,平常有一些關鍵告警,當某一個核心系統真正出現異常的時候,大家肯定有這個體會,同時會有大量的告警發出。

舉個例子,現在比較流行微服務的方式,如果某個集群里面有一百個節點,當由于訪問量變化,導致資源使用率上,或者說因為某次上線,導致程序出現了Bug,我們如果設置一個短信的接受方式,是不是手機一直在響,一方面要檢查出現什么事故,排除問題。
CPU如果有什么問題,導致集群的可惜會上將,也會導致時間上升甚至其他的問題,剛才說的告警數量去翻了,我們需要有一個能夠比較智能的對大量的告警做理解和信息合并,并且提取出一些信息,告訴我們究竟發生了什么。而不是給我們原始數據,我們要的是信息。
因為之前和很多大型中型和小型公司的負責人都溝通過,其實做智能告警處理之前,最好先把告警數量降下來做好告警分類,我們現推薦語音的方式,除此之外大部分的告警還是推薦員工訂閱微信告警,只要員工訂閱了微信公眾號告警,里面可以展示的信息非常多樣化,我們可以展示告警詳情和相關的應對,包括一些合并的信息列表和做一些根根因分析,避免誤告。
我們對內部監控系統也做了分析,有些可能做的不太好的監控系統,有一些設置連續一次異常就告警,這種無效告警非常多,甚至說無效告警內容達到50%或者更多,正常來說,兩次告警間隔時間間隔五分鐘,設置最高的告警次數是多少,如果超三十分鐘,還可以提到更高的優先級進行椎理。
在告警時間窗口選擇上,如果把窗口拉的比較長,相關的告警就可以合并效果更好,但是反而時效性會下降,為了兼顧時效性,在合并維度上我們發現一個集群之內,同時會出現多個告警,我們合并起來效果就會比較好,對于單個節點和IP里面,上面可能會出現異常,上面不同監控指標也會出現異常。
比如說某個機器宕機或者僵死,有一些進程和端口也是不及時的,也有業務指標也是不及時的。另我們服務器也是使用網絡連接起來的,如果某一個網絡設備出現問題,同網段的一些機器也會出現丟包率過高的問題。

另外我們可以按照異常種類進行合并。以上只是常見的維度,真正的維度更加復雜,而且出現的異常不僅僅是單個合并了,往往是幾個維度互相組合了,這樣實踐起來大家很自然最先想到的可以用規則和模板的方法,但是維護代價非常高,而且擴展性比較低。我們用了一個新的方式,我們提出了告警合并數的方式,對告警進行劃分,實時計算出來應該按照哪些維度進行合并。
這個算法簡單理解起來我們按照一分鐘的告警信息進行合并的,我們那一分鐘的告警進行集合,需要到每個人的告警進行合并,對于每個人相關告警的類型,以及不同的告警方式,按照這幾個維度,如果一致的情況下會對這個人的告警進行合并。
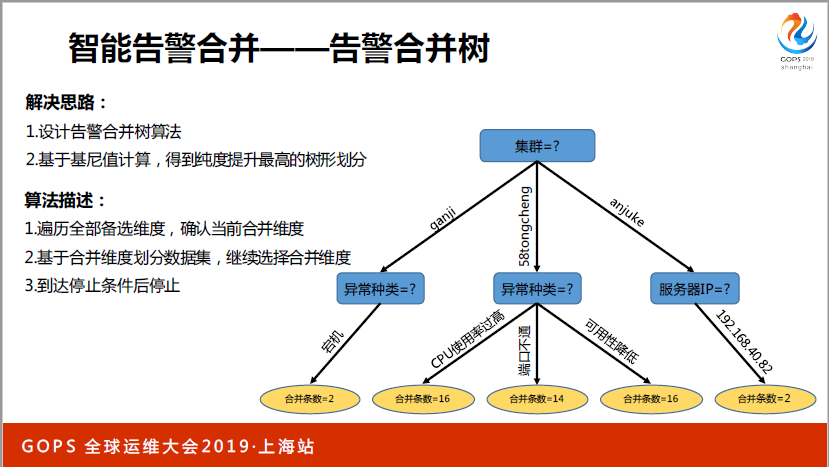
具體合并過程是什么樣的,其實可以理解為樹型結構,一分鐘的所有告警,根據剛才的維度劃分,生成一個集合,可以理解為一個樹的根節點,嘗試用不同的幾個備選維度進行集合劃分,按照集群的維度,IP的維度或者網段的維度進行劃分。
這樣我們有一個備選集合,再針對備選集合,計算基尼值,看是不是把同類消息劃分到同一個下級節點,如果是的話會帶來這棵樹的信息純度上升,我們就是為了讓同樣的告警劃分到同一個地方去,這樣的話我們除了根節點之外,我們就得到了第二層節點,以此類推,如果當前告警數量還是比較多,可以看其他維度。
如果嘗試合并的話是否也可以再進一步拆分出節點,基于這些規則,告警里面信息條數和程度提升到了什么程度,從這棵樹的根節點,最終到達葉子節點,其實經過了多個維度的告警合并,我們就可以確定我們應該按照哪些維度把這些告警進行劃分,推送給我們的用戶了。
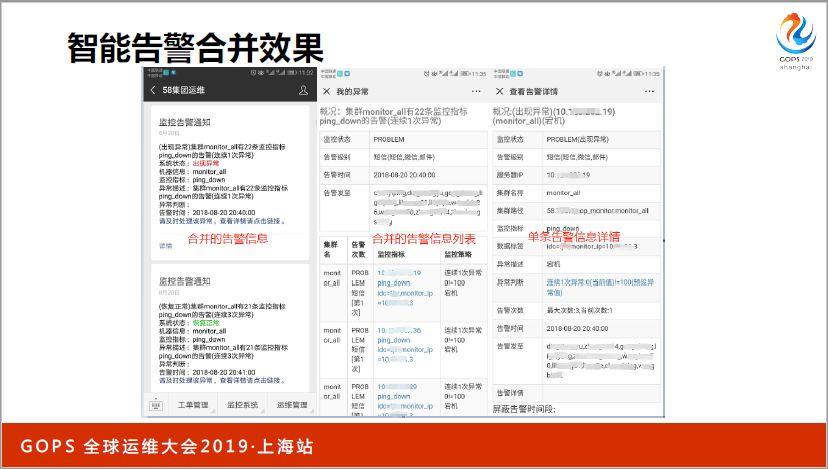
這是告警合并的效果,剛才已經提到了,我們比較推薦微信告警,因為里面展示的信息可以把我們想展示的表格和一些數據,甚至一些圖形化的信息都展示進去。
我們收到第一個告警,告訴我有一個集群里面有22條宕機告警,傳統的方式是22條告警,現在只告訴我一條,而且告訴我合并的告警異常機器占總體機器數的比例,如果我想看這22個宕機告警分別是哪些,點進去看可以看到一個列表,再往下可以看到每臺機器的具體情況和監控指標的變化曲線圖。
這里面也是我們智能告警合并,按照多個不同維度合并之后的效果展示,首先我們看一下第一個方面,某一個集群有22個宕機告警,可以提示當前服務器異常比例84%,整個集群里面26臺機器,現在有22個有問題,不僅僅是說把告警機器人簡單合并,而是說從22個告警里面能夠提取出一些有用的信息,并且展示給運維人員,這樣就很方便讓我們判斷,什么地方出現了什么問題。
對于服務器和指標級別進行合并,某一個服務器現在有內存過高的告警,我們知道這個服務器內存有問題,影響面就是服務器。
對于集群和指標維度進行合并,能夠看到某個集群現在已經有六表磁盤空間不足的告警,當前集群服務器的日常比例,百分比是多少。
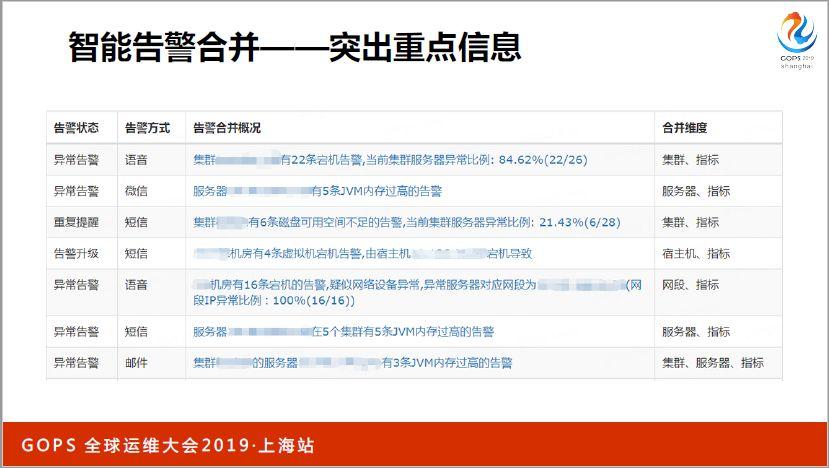
其實難點就在于合并的時候是按照多個維度進行合并的,而且是實時對數據進行分析的,看哪個維度進行合并會帶來信息純度提升最大。某一個機房有四條虛擬機宕機告警,由于宿主機都是同一臺,從而判斷出虛擬機由于物理機宕機導致的。再往后某一個機房,這些機器歸屬于同一個網段,很有可能是某一個網絡設備出現了問題,非常方便運維人員判斷究竟哪個點出現了異常。
服務器維度和指標維度相結合,服務器在五個集群有五條GAM過高的報警,最后一條是服務器維度,某個集群的服務器有三條GAM內存過高的告警。
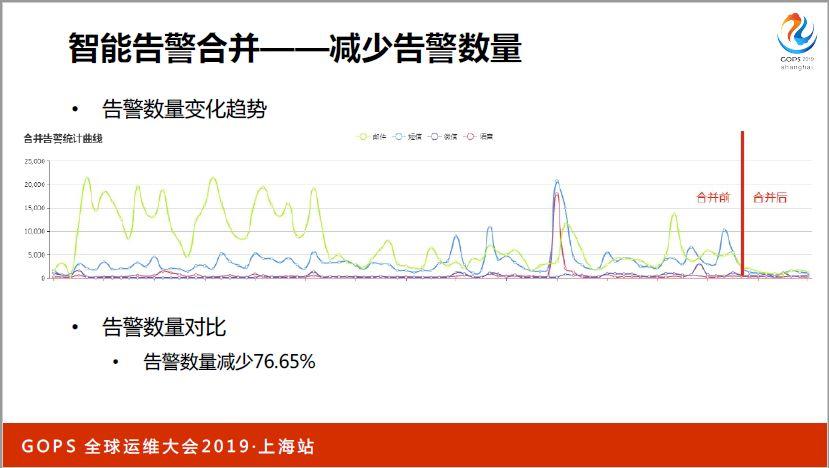
展示這個,我們可以通過實時分析數據,按照報警合并的這種做法,按照不同的維度進行最恰當的方式進行合作,并且在合并國境里面提取出一些更加更加有用的實習。告警合并最重要的目的是減少告警數量,這里面可以看到告警數量的變化趨勢,紅線之前可以看到不同的方式,包括、鍛煉、語音,每天變化比較劇烈,數值比較大。
3、知識圖譜構建
同時和大家分析一些知識圖譜構建,如果我們想打造一個更聰明的運維智慧大腦的話,想做更深入的分析,比如說根因分析,現在人為什么有智能化的處理能力,或者說這種分析能力,其實一方面是有知識,另外一個方面是相關經驗,對于同學來說,知識和經驗這兩方面都是空白。

所以說可能要進行更加智能化的判斷,先要建設好知識圖譜,知識圖譜很重要的兩點,一個是知識一個是經驗,首先對于知識來說,需要把運維相關的各個系統的知識進行整合打通,現在有很多系統CMDB,監控、管理、云平臺,如果出現故障,可能和各個系統之間都有關聯,尤其是一些變更上的事件,導致引起一些問題。把所有系統聯動,把信息整合起來。
我們關注的這些運維相關的數據對象也比較多,包括機群、服務器、端口、進程。我們通過挖掘得到了主題之間的關系,包括關聯、因果、部署這些。

獲取到運營主體的各個特性和變化規律,從而得到和集群和服務的畫像。
運維知識圖譜當中這些點是最實用的,比如說整個網站結構是一定要清楚的,整個用戶的流量,通過VIP進入網站,也一個流量分組,在Nginx上有流量變化,有一些外部服務,還有一些數據服務、屯出服務,每層的關聯關系是什么樣的,病人有什么特性。
調用鏈毋庸置疑也是非常重要的方面,是服務之間的調用關系,現在在微服務部署的背景下,現在有很多業務非常復雜,相關的服務也是非常多,而且關聯關系也非常復雜,如果有了這個調用鏈信息,就可以很容易判斷故障之間的關聯。
對于監控指標也要進行分層,服務器層、系統層、業務層,這些都是相互之間一定的因果關系。服務故障關系方面,緩存掛掉,數據庫壓力比較大,也是比較常用的一些知識,包括對于基礎設施的依賴,內網對于DNS的依賴。

這些知識和經驗需要怎么挖掘出來,剛才提到數據也是智能化的基礎,我們首先要收集到各方面的數據,然后從這里面挖掘出一些信息。首先第一步有各方面的基礎數據,將平臺打通,使數據之間建立起一定的關聯。第三步要進行關系挖掘,比如說故障之間有什么關聯,服務部署調用的狀態是什么樣的,每個集群每個服務的變化規律和特性是什么的,能夠達到運維畫像。
這里面有一個例子,不同的平臺不同的實體是有一定的關聯關系的,但是由于不同的系統是在不同的時期開發完成的,所以當時設計的時候沒有考慮到進行一定的關聯,后期為了更好的打造運維大腦,必須把相關的中心關聯起來。
CMDB里面有一個集群名的概念,更早有服務名的概念,要在多層服務之間,A和B之間有很多機器和節點,時間實現自動化調度,實現了服務器管理平臺,調動都是通過服務管理平臺連在一起,所以很自然我們要把集群和集群名進行。
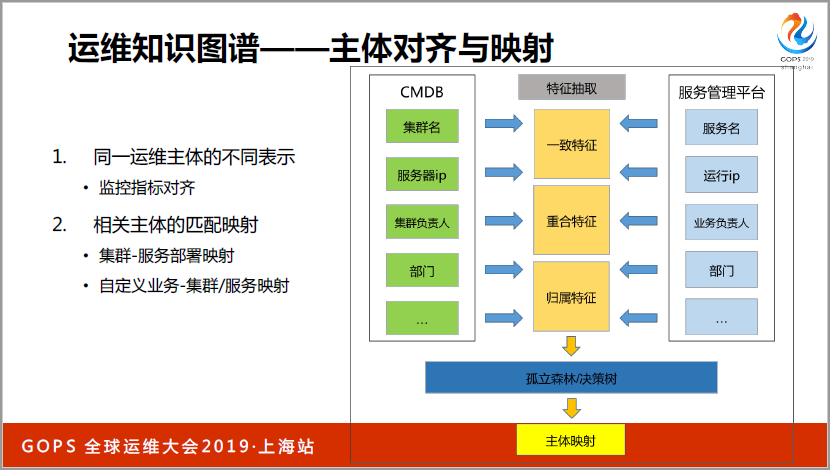
我們抽取了很多的一些特征,比如說歸屬于哪個部門,負責人有哪些,集群做什么用途,以及一些流量變化的趨勢和集群當中有哪些服務器,最終抽象成為有哪些是一致的特征,有哪些是重合的特征,哪些是歸屬的特征,最后用孤立森林的決策方式,完全了主體影射,從而把各個系統之間進行打通。
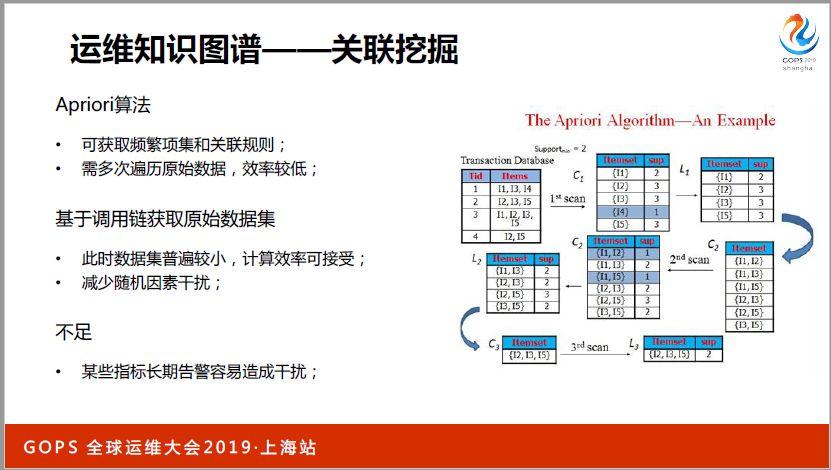
關聯挖掘方面我們使用一些其他的改進算法,發掘出哪些是常常會一塊出現的異常。同樣使用這些算法過程當中,也可以根據我們的業務,調用鏈或者常見的根因經驗,從而減少算法的復雜性。
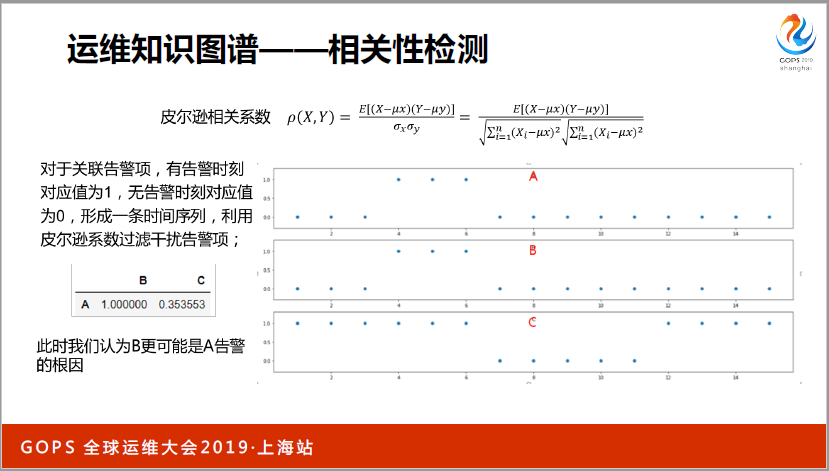
通過關聯挖掘方式可以拿到哪些是相關的,可以對因果關系進行驗證。根據實際監控指標曲線,監控曲線的變化看是不是真的相關,相關度如何,就可以用皮爾遜相關指數方式進行驗證。
最終我們得出的一些指標關聯圖比較復雜,我們也是為了方便大家理解選了一些比較簡單的。比如說CPU.idle,或者說ping.down,通過這樣一個比較大的圖,所有的監控指標之間的因果關系就比較清楚了。
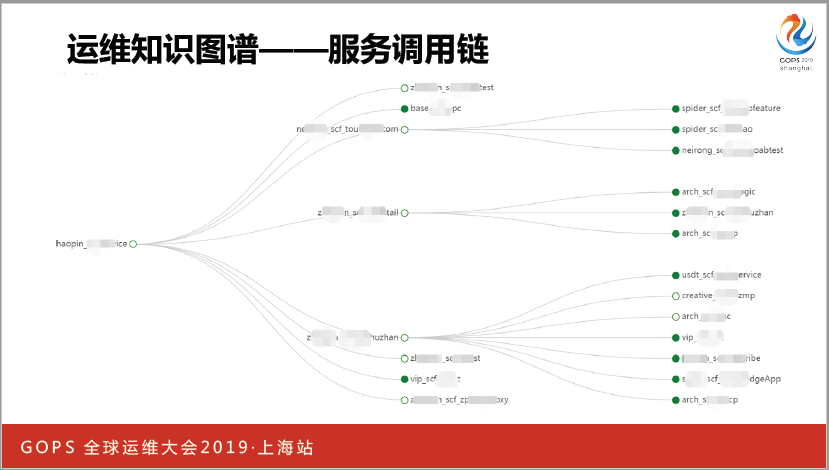
調用鏈也是非常重要的知識,服務之間有非常復雜的調用關系,出現一些異常我們必然會根據調用鏈判斷它們之間誰是因誰是果。我們公司有一個公共框架,大家在寫代碼的時候會把這個框架包含進去,我們也會自動采集服務的調用鏈。
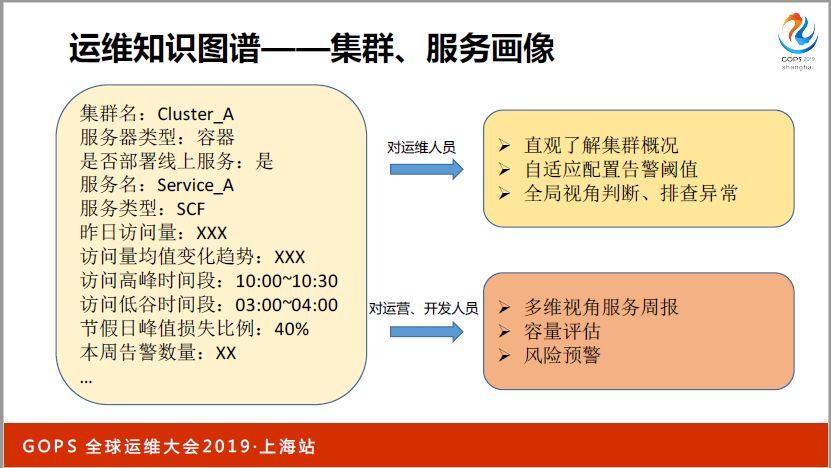
這些是更高級一些的東西,我們可以搞一些集群和服務的畫像,從而應用在低負載管理、容量管理、容量預測、預算各個方面的系統里,建立起一個類似于大家比較熟悉的用戶畫像,我們對于集群和服務的一些特征和一些日常運行的規范規則進行服務畫像,其中也包含一些基礎信息,比如說集群名,是不是全容器,全上云的集群,部署方式是什么樣的,服務類型,以及訪問量,訪問量的變化和規律,流量是屬于比較低中等還是比較高,以及訪問時間段,我們做一些流量預測或者說容量評估的時候其實都會用到類似于這些相關的系統。
4、智能根因分析
講到根因分析,只要我們收集到大量的數據知道當前時刻所有的監控指標的變化的數據,并且能夠標記當前出現了什么故障,收集了足夠多的數據訓練模型,只要把數據扔給模型就知道這個根因分析了,這是一個比較理想化的想法,實踐起來比較難。

因為首先整個系統非常復雜,相對來說需要非常龐大的訓練集。但是我們的訓練集基本上都是一些故障或者事故的數據,這些事故數據是不可能非常多的,如果非常多的話說明穩定性做的非常差,基本上這種方式不太好實現。
所以我們采用動態決策的方式,輸入一些實時異常和變更實踐,通過根因分析組件,每個系統動態決策哪個地方出現了問題。
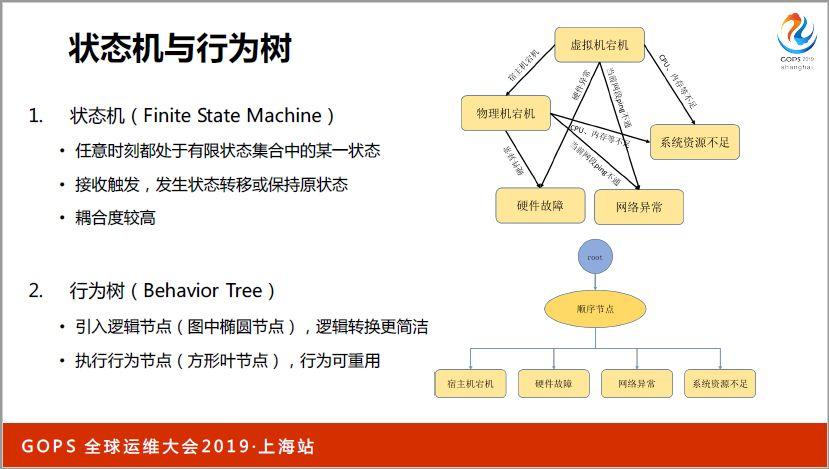
實現根據人的經驗,根本這些知識判斷哪個地方出現問題,其實又有兩種可選擇的方案,一種是狀態機的方式,一種是行為樹的方式,這兩種方式在之前游戲開發的時候比較類似,應用比較廣泛,因為游戲里面有很多角色,會有一些動作。
比如說一些簡單的游戲,有衛兵在守衛城堡進行巡邏,這些邏輯都是用狀態機或者行為樹的方式呈現,這種方式不是特別好的方式,整體來說系統耦合度較高,因為每個狀態都是有一個節點來表示的。之間的關聯比較復雜,可擴展性會比較差,所以我們使用了行為樹的這種方式。
行為樹這種方式比較好的一點是有幾種節點,有邏輯節點和執行節點,邏輯節點可以理解為控制節點,根據經驗去追查這個問題,我應該按照哪個邏輯,按照哪個順序查什么信息,得出判斷。
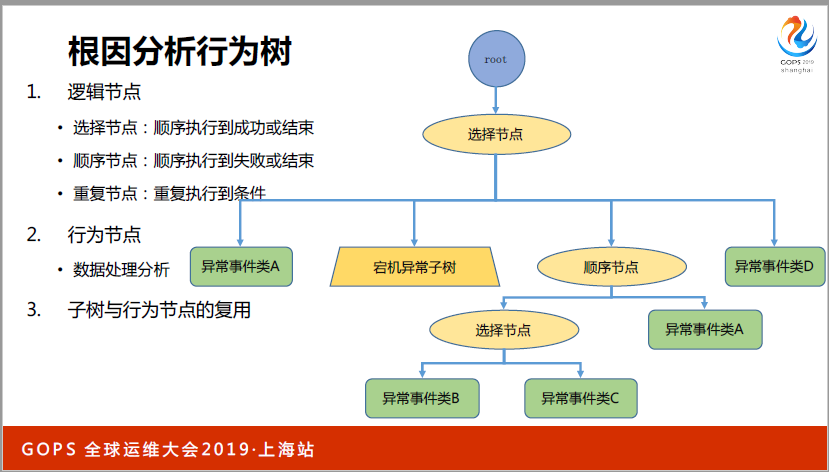
這是我們和根因分析相關的行為樹,在邏輯節點上可以分為選擇節點,底層的這些節點如果執行的成功就結束了,數需節點是數需執行一直到失敗或者結束,主要目標也是為了控制我們根據人的經驗。
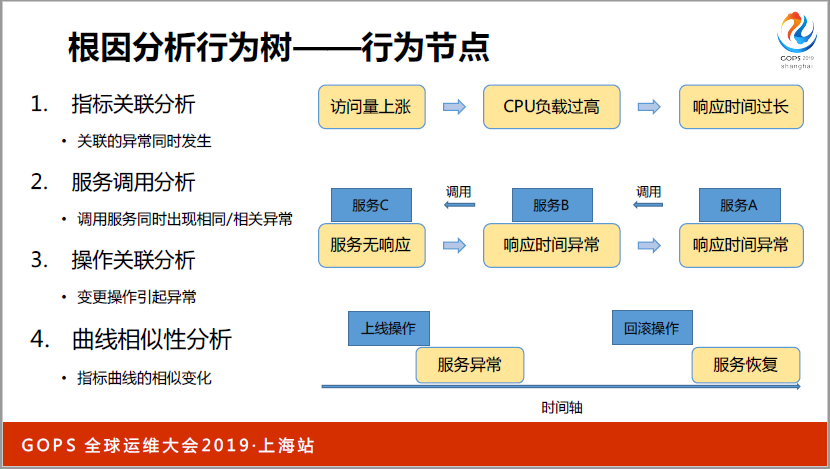
如果我們要判斷在哪些領域哪些方面排查這些問題。很關鍵是行為節點,主要執行的是數據的處理分析任務,人的經驗用來判斷我從哪些方面排查問題,定位到問題的時候要用到監控不同指標之間的因果關系,兩者結合起來就可以比較好的完成這個任務。
這里面有一些行為節點可以發現的一些問題,能夠關聯起來的一些根因,指標關聯分析,如果你的訪問量上漲了,CPU負載會比較高,如果一個底層的服務出現問題,會影響上層服務。
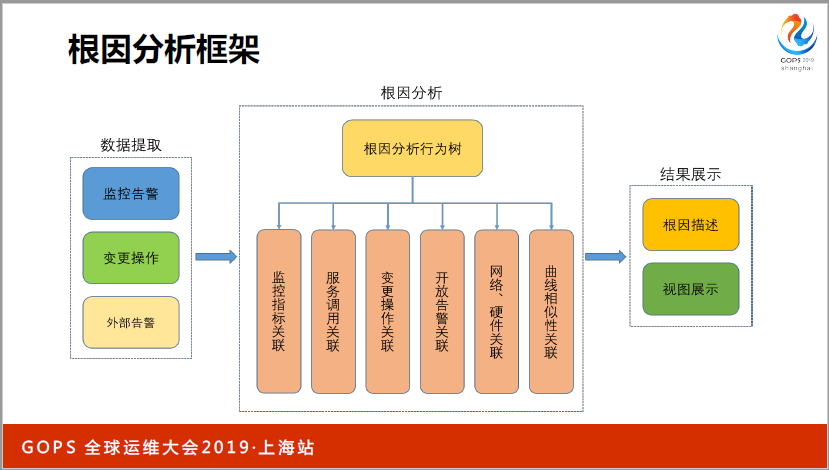
這是一個根因分析框架,左側主要是數據提取方面,中間這部分其實也涉及到很多監控指標的關聯或者服務調用的關聯,以及變更操作的關聯,以及底層網關硬件相關的狀態關聯。最終我們如果說去驗證關聯是不是真的有比較高的相關性,可以用曲線相似度再判別一下。
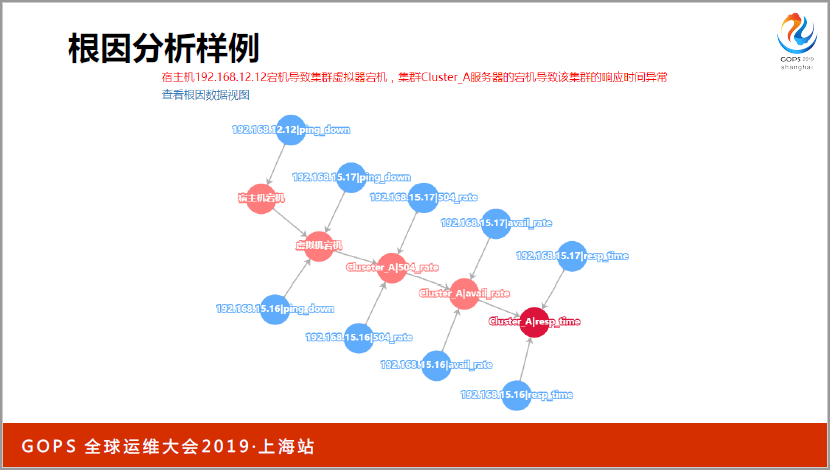
這是幾個例子,這是根因分析,某一個宿主機出現宕機了,會導致兩臺虛擬機出現問題,導致這個集群出現了504比較高的問題,通過這種比較圖形化的方式,能夠比較好的展示異常,紅色節點經過點擊可以收縮起來再展開。
這是另兩個例子,當集群左側的訪問量升高的時候會導致丟棄率比較高,從而影響響應時間和可能性。右側是由于一次上線事件,導致了可能性下降,這樣可以把多個集群和多個監控指標之間的異常串起來,而且很好的展示給我們的用戶。