













運維老鳥才知道:三個 Ansible 腳本玩轉千臺服務器
凌晨三點的緊急電話——運維的噩夢
如果你是運維老鳥,想必經歷過這樣的場景:
凌晨三點,電話狂震,驚醒的你看著屏幕上熟悉的報警信息——線上某個核心業務服務器異常!
你迷迷糊糊地爬起來,遠程登錄服務器,開始排查問題。服務崩潰、CPU飆高、磁盤占滿……各種可能性在腦中快速閃過。但更糟糕的是,這次故障波及的不止一臺服務器,而是整個集群的上千臺機器!

怎么辦?這就是Ansible登場的時刻!
運維的終極目標,不是“救火”,而是“讓故障消失于無形”。
今天,我就分享 3 個 Ansible 腳本,讓你輕松駕馭千臺服務器,不再被半夜的電話支配!
10秒內檢查千臺服務器的關鍵狀態
遇到故障時,第一步就是快速找到問題所在。如果有成百上千臺服務器,逐臺排查根本不現實。這時,用一個簡單的playbook劇本,就能在10秒內一次性獲取所有服務器的資源狀態。比如CPU使用率、內存占用、磁盤空間等關鍵指標,方便又高效。你可以根據自己的需求設置相應的指標。
- name:快速檢查服務器狀態
hosts:all
gather_facts:no
tasks:
-name:獲取CPU、內存、磁盤使用情況
shell:|
echo "CPU: $(top -bn1 | grep 'Cpu' | awk '{print $2"%"}')"
echo "MEM: $(free -m | awk '/Mem/ {print $3"MB/"$2"MB"}')"
echo "DISK: $(df -h / | awk 'NR==2 {print $5}')"
register:server_status
-name:輸出所有服務器狀態
debug:
msg: "{{ inventory_hostname }} -> {{ server_status.stdout_lines }}"執行下面的命令執行劇本的任務:
ansible-playbook check_status.yml可以通過添加-i,如果不指定默認是讀取/etc/ansible/hosts這個清單。
執行完上述命令后,會輸出如下結果:
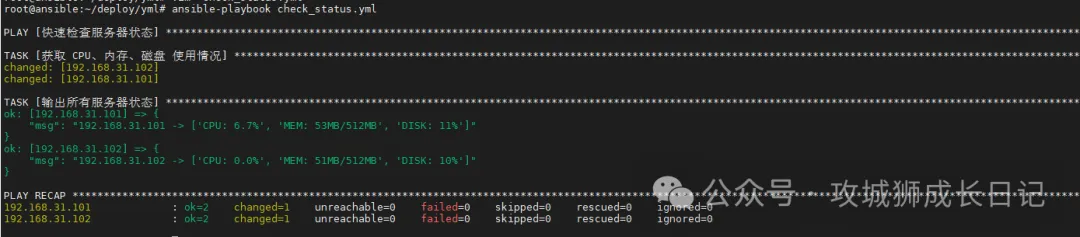
這個腳本能 一秒內連接所有服務器并執行檢查,然后把結果直接輸出,幫助你快速鎖定問題服務器!
30秒內批量修復服務器故障
面對多臺服務器同時出現服務故障,傳統的逐一處理方式耗時費力。但有了Ansible,只需簡單幾步,就能高效完成批量重啟,輕松解決運維難題。
- name:批量重啟Nginx
hosts:all
tasks:
-name:重新啟動Nginx
service:
name:nginx
state: restarted編寫好劇本后,通過下面的命令執行重啟任務。
ansible-playbook restart_nginx.yml -i inventory不管你有10臺還是1000臺服務器,一條命令全部搞定,再也不用逐臺SSH登錄,省時省力!
徹底杜絕半夜故障——自動化巡檢與修復
不想被半夜報警聲吵醒?自動化巡檢與修復是不二之選!設置定時任務,每小時巡檢,問題即刻修復。輕松實現,使用Ansible腳本!
- name:自動巡檢并修復
hosts:all
tasks:
-name:檢查Nginx是否存活
shell:systemctlis-activenginx
register:nginx_status
ignore_errors:yes
-name:自動重啟Nginx(如果檢測到異常)
service:
name:nginx
state:restarted
when:nginx_status.stdout!= "active"然后,配合crontab定時任務,讓它每小時自動執行:
echo "0 * * * * ansible-playbook auto_fix.yml -i inventory" >> /etc/crontab小結
傳統SSH逐臺手動管理服務器的方式早已outdated,現代運維早已擁抱Ansible等自動化工具。頂尖運維高手都在用Ansible玩轉千臺服務器,讓運維工作更高效、更精準。真正的運維高手,靠的不是加班和熬夜,而是強大的工具和自動化能力!讓Ansible成為你的“運維外掛”















