如何從代碼層提高產品質量
一、導讀
文章主要從四個方面說明:
- 產品代碼漏洞檢查的背景和方法
- 代碼漏洞的搜索深挖技術
- 提高產品質量的方法
- 總結與展望
二、產品代碼漏洞檢查的背景和方法
1. why-為什么要檢查產品代碼的漏洞
一般情況下,產品質量的問題多數與程序代碼相關。比如銀行軟件出現漏洞,導致十幾個客戶信用卡被盜刷。2003年阿麗亞娜5型火箭升空爆炸造成5億美元的損失。由于電控系統的軟件問題導致大面積停電事故,給交通,通信,居民生活造成嚴重影響等等,都是和產品代碼相關。代碼的漏洞檢查與分析可以幫助用戶從根源上減少70%-80%的產品崩潰和安全性問題。只有代碼中的崩潰和安全缺陷得以及時消除,最終形成的產品才能具備較高的質量,有效降低整個產品風險。
2. when-什么時候檢查產品代碼的漏洞
在產品開發測試發布過程中,流程越往后,漏洞造成的影響越大。漏洞發現的越早,修復成本越低。
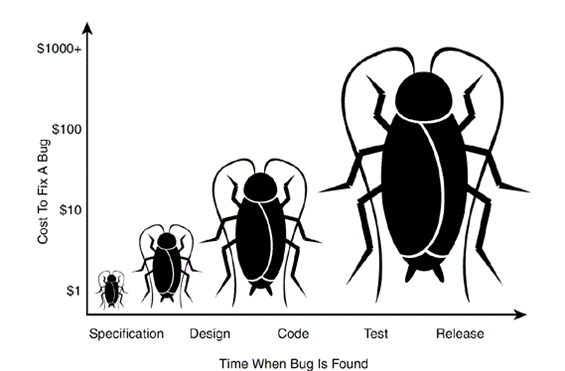
如下圖中紅色的曲線,橫坐標是產品發布流程,縱坐標是修復缺陷成本,可以看出,在測試階段,修復成本比較低,在產品發布之后,修復成本是成指數增長的。
所以在產品測試階段,最好把產品代碼中的漏洞都檢查出來。那怎么對產品代碼的漏洞進行檢查。
3. how-檢查產品代碼漏洞的方法
現階段一般有2種方法,而且這2種方法我們已經實現了。
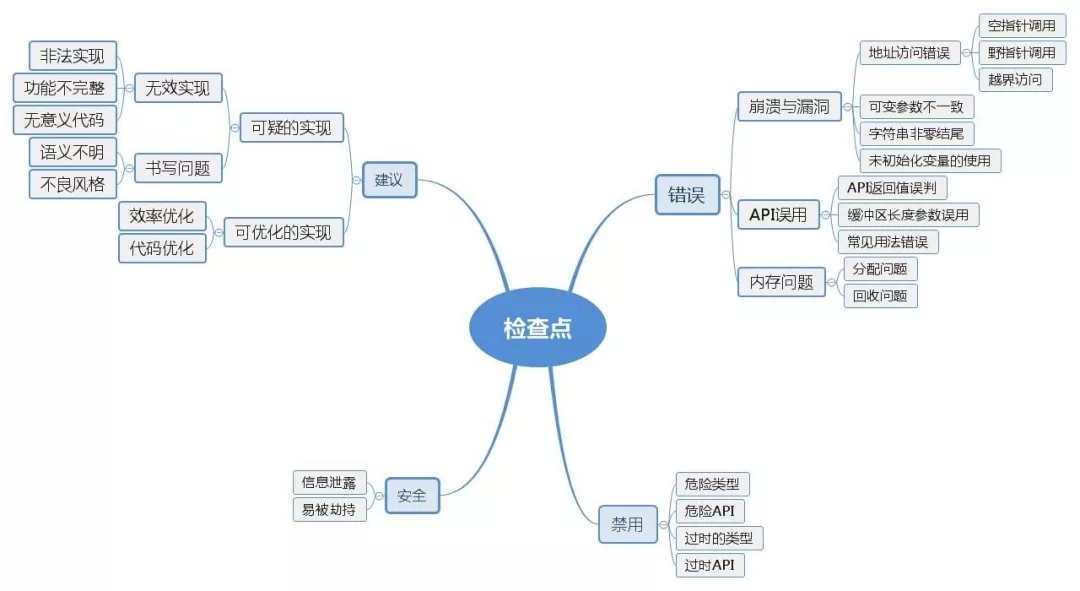
一種是源代碼的漏洞掃描與檢查,主要方法是對編碼規范的檢查,常見的編碼規范有4類,分別是錯誤類,安全類,禁用類和建議類,具體內容詳見下圖。自定義代碼規范的制定與實時更新,根據具體業務場景的代碼規范的制定等等方法都能很好的檢查出產品代碼的漏洞。
另外一種是對二進制文件的漏洞掃描與檢查,比如google提供的veridex工具,可以掃描非法API調用,該工具將非法API分了3類。
4. 深度挖掘產品代碼漏洞的方法
通過上面介紹的2種方法,只能對特定代碼或二進制進行檢查,但是對產品,乃至整個公司的代碼倉庫,隱藏的bug卻是驚人的。
由此,在上述2種基礎的方法上,我們引入了另外一個技術,代碼漏洞的搜索深挖技術,簡而言之,即代碼搜索。
此外,經過調研發現,國外也有類似的研究,NASA,microsoft等機構已經利用代碼搜索技術,發現了多個零日漏洞。
三、代碼漏洞的搜索深挖技術
1. 代碼搜索的問題和挑戰
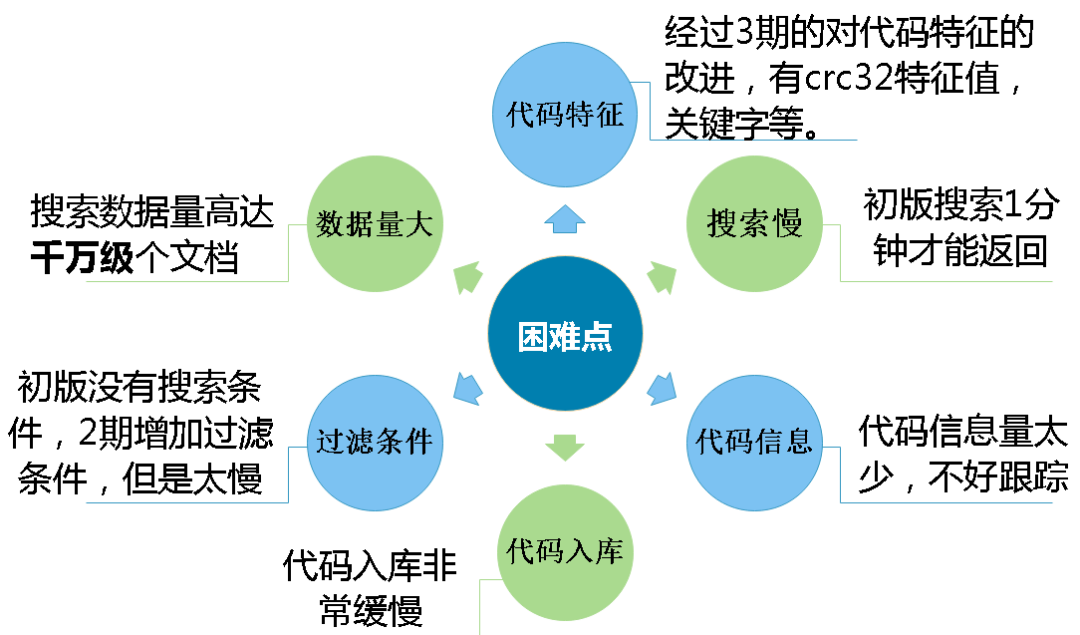
主要是6個困難點,如下圖所示。
- 代碼特征的確定
- 搜索速度慢
- 代碼信息量太少,不好定位漏洞。
- 代碼入庫非常緩慢
- 過濾條件不好兼容
- 數據量大,搜索數據量高達千萬級代碼文件。
針對這些問題我們做了一序列的優化和改進。
2. 代碼搜索的技術架構
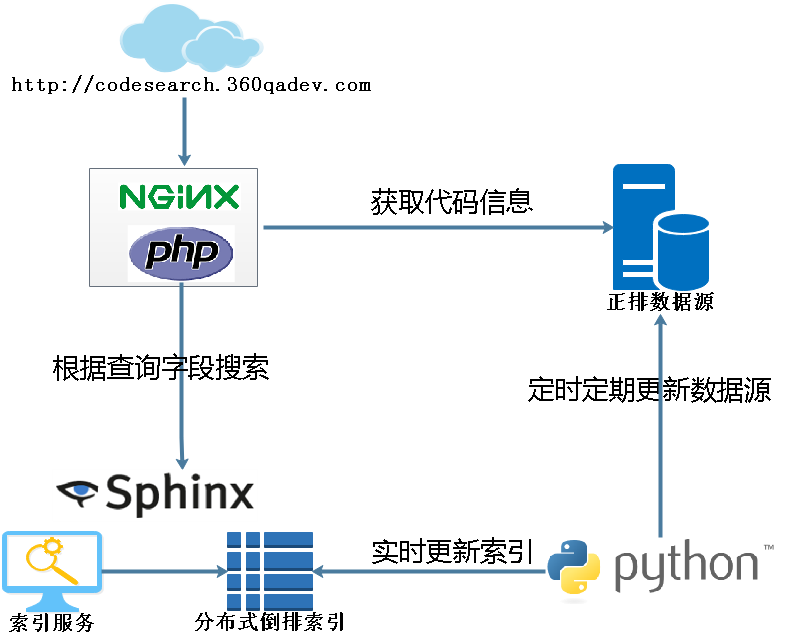
主要是5部分,如下圖所示。
- python后臺部分用于增量更新數據源信息和實時更新索引。
- 正排數據源,主要采用mysql數據庫,包括表結構的設計,索引和分表設計等。
- Sphinx實時分布式索引,用于提供索引創建服務和搜索索引服務等。
- Php+nginx服務端部分,為前端提供接口服務。
- 前端部分,用于展示搜索結果和后臺管理等。
3. 代碼搜索的服務端
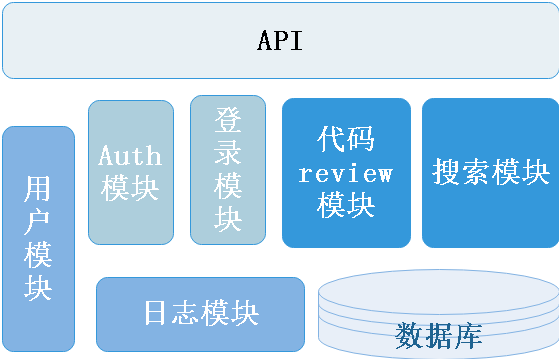
代碼搜索的服務端為前端或其他系統提供API接口,一共有6大模塊,包括搜索模型,登錄模型,校驗模型,用戶模塊,日志模塊,代碼review模塊。數據庫為上述6大模塊提供數據支持。
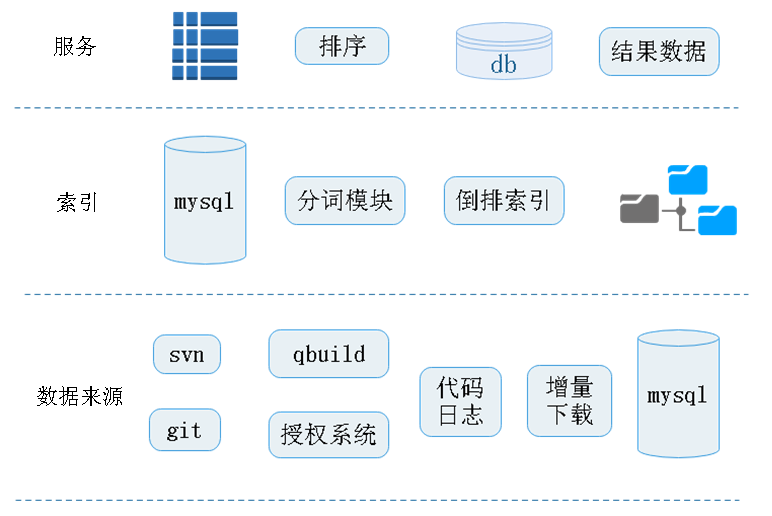
4. 代碼搜索的后臺
大致分為3層:最下面一層數據來源層,支持svn和git的代碼倉庫,來源包括qbuild系統和授權系統,獲取代碼日志,增量下載文件,最后存儲在數據庫中。索引層主要是從數據源中獲取文檔信息,然后經過分詞模型,倒排索引算法,將索引存儲在文件系統中。
服務層主要是sphinx索引工具提供的索引服務,通過排序,獲取索引文檔信息后,從正排數據庫中拿到文檔全部信息,返回結果數據。
5. 數據源增量入庫方案
代碼搜索的困難點之一是數據源入庫非常慢,針對這個問題,我們有如下的優化方案,數據源的增量入庫方案。

主要有8個步驟:
- 分別是從qbuild或授權系統獲取代碼地址
- 獲取當前代碼地址的提交日期
- 根據提交日期獲取代碼提交日志
- 通過解析日志,獲取增量文件列表,然后每個文件進行下面的處理,先進行去重判斷
- 然后下載該文件,再進行去重判斷
- 存儲在數據源中
- 經過分詞工具
- 最終實時存儲索引
這個過程比較長,但是分解到每一步,卻比較容易實現,比如獲取代碼提交日志和代碼文件下載,svn對應的命令可以參考如下。
- svn log -r {0} --xml -v "{1}" --username "{2}" --password "{3}" --non-interactive --no-auth-cache --trust-server-cert> {4}
- svn export -r {0} "{1}" "{2}" --force --username {3} --password "{4}" --non-interactive --no-auth-cache --trust-server-cert
在數據源增量入庫方案中,有一個很大的問題需要解決,就是重復的問題。可以看一下,對于svn有路徑包含重復的問題,下面那個路徑是包含上面那個路徑的,上面那個路徑將會被入庫2次。
- http://svn.example.com/svn/testxxx/111/222/333
- http://svn.example.com/svn/testxxx/111
Git也有相似的問題,分支重復,不同分支代碼會有大量重復提交的記錄。
- http://git.example.com/root/11 分支:master
- http://git.example.com/root/11 分支:v1.1
我們的去重方法是,針對svn,利用模塊id+revision的方式,對于svn,同一個模塊id下的revison是遞增的,不會有重復問題。相應的,git是通過倉庫id+提交sha1值去重的,對于同一個倉庫,提交的sha1值是唯一的。
6. 實時分布式索引技術
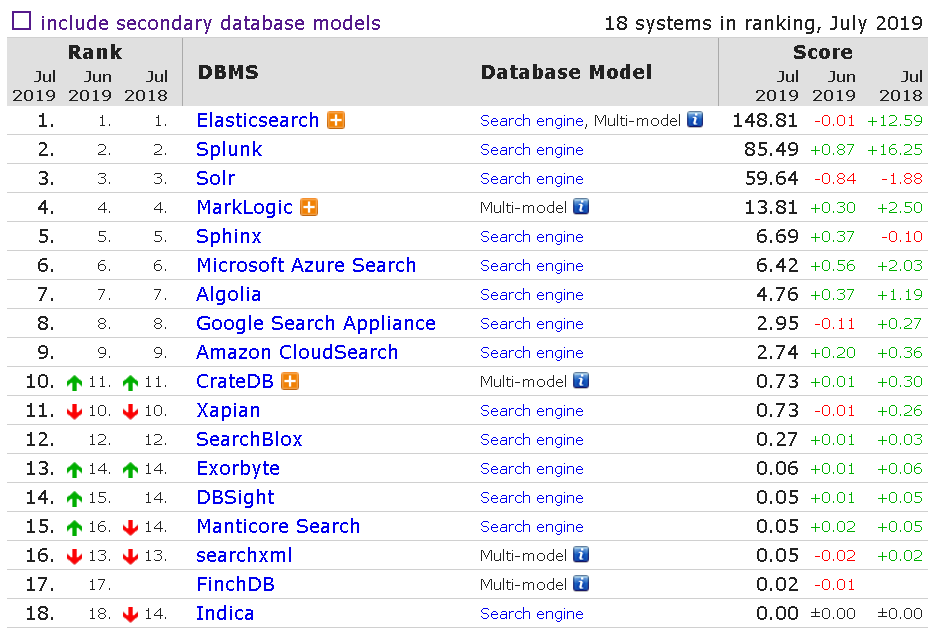
代碼搜索系統遇到的另外一個困難是搜索太慢,為此我們引入了sphinx索引工具,為什么選擇sphinx索引工具呢。該工具支持高達數十億個文檔,數TB的數據和每秒數千個查詢。支持各種數據源,包括xml,sql,python等。支持結果的各種過濾聚合功能,快速高效的索引,應用場合廣泛,比如維基百科,優酷土豆,github等。下圖是今年的索引工具的排行榜,可以看到sphinx排在第5,受眾范圍廣。
(1) sphinx工具使用
Sphinx主要包括3個可用的工具:
分別是index實時索引工具,主要是對數據源的數據進行倒排索引,并存儲,使用命令如下,sphinx.conf是sphinx的配置文件。
- eg: /usr/local/sphinx/bin/indexer -c sphinx.conf code
Searchd搜索服務工具,php可以通過sphinx擴展,訪問該服務,使用命令如下。
- eg: /usr/local/sphinx/bin/searchd -c sphinx.conf &
Search搜索工具,客戶端搜索工具,可以用該工具測試索引的正確性,一般只是測試使用。
- eg: /usr/local/sphinx/bin/search -c sphinx.conf mykeyword
可以看到這3個命令都用到了sphinx的配置文件,那么這個文件怎么配置。
(2) sphinx實時分布式的配置詳情
一般情況下,最初會采用主索引和增量索引的方式,但是隨著數據的增加,服務和運維都有壓力,通過優化,我們最終采用實時分布式的方式。實時索引的好處有,代碼索引無延時,沒有額外的定時程序更新和合并索引服務,降低運維成本,提高搜索精確性和可靠性。分布式的好處有,資源利用率提高,搜索效率提高,搜索并發性提高等
實時分布式的配置如下:
- 第1個實時索引的配置,type是rt,也就是realtime,path表示該索引存儲的位置,下面幾行是字段的定義,rt_field就是需要索引的字段,rt_attr_uint和rt_attr_timestamp是索引字段的屬性,一個是int類型,一個是時間戳類型。
- 第2個配置是分布式配置,type是distributed,下面幾行是分布式位置。
- 第3個配置是索引服務配置,9312接口是提供索引服務的,9306是接收實時索引服務的,下面2行是日志位置。
- index coderealtime
- {
- type = rt
- path = user/local/sphinx/indexer/files/coderealtime
- rt_field = content
- rt_field = filename
- rt_attr_uint = rpid
- rt_attr_timestamp = cdate
- }
- index codedistributed
- {
- type = distributed
- local = coderealtime
- agent = localhost:9312:crt1
- agent = localhost:9312:crt2
- }
- searchd
- {
- listen = 9312
- listen = 9306:mysql41
- log = /user/local/sphinx/indexer/logs/searchd.log
- query_log = /user/local/sphinx/indexer/logs/query.log
- }
(3) 代碼搜索排序方法
代碼搜索最重要的一個指標就是排序方法,本方案,主要從3個方面對代碼結果進行排序,分別是詞組評分,代碼提交時間,和BM25算法。這3個指標中最重要的是BM25算法,下面簡單的介紹該算法的實現方法,公式如下:
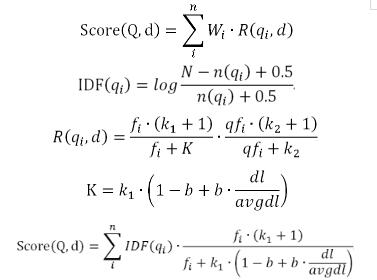
Score(Q,d)是衡量某次query查詢和文檔的相關性計算公式,d表示當前文檔,Q是query中所有的關鍵字集合,qi是其中的某個關鍵詞,n是Q的長度,Wi是這個詞的權重,R(q,d)是這個詞和文檔的權重。Wi默認是IDF值,N表示所有文檔數,n(qi)表示包含該關鍵詞的文檔數,0.5是避免n(qi)為0的情況。大致的意思是關鍵詞在所有文檔中出現頻率越多說明越普遍,就越不重要,權重越低。R(q,d)是這個詞和文檔的權重,大致的意思是某個關鍵詞在該篇文檔出現的次數越多,說明越重要。
Wi突出的全局的權重,R(q,d)表示的局部權重。舉個通俗的例子,在圖書查找過程中,比如[作者]這個詞,幾乎在所有書中都會出現,所以[作者]這個詞的權重很低,[人工智能]這個詞不常見,如果某個圖書中經常提到人工智能這個詞,大概率這本書在講人工智能。BM25算法通過統計的方法,就能對代碼進行合理的排序。
四、提高產品質量的方法
如何利用代碼搜索技術提高產品質量,主要是2種方法:
- 第1種方法是結合業務督促開發修復代碼漏洞,一方面根據前面介紹的檢查產品代碼漏洞的2種方法,根據這些檢查出來的漏洞進行深度搜索,將產品和公司代碼庫中隱藏的漏洞都修復了,去除產品隱患,另一方面結合業務,比如某個函數實現有漏洞,可以根據函數名進行搜索,查看函數調用的模塊,避免代碼漏洞的擴散。
- 第2種方法是對產品代碼的敏感詞的檢查,比如代碼審計系統的敏感詞和禁用api的檢查,文件簽名系統的敏感簽名信息的檢查等。
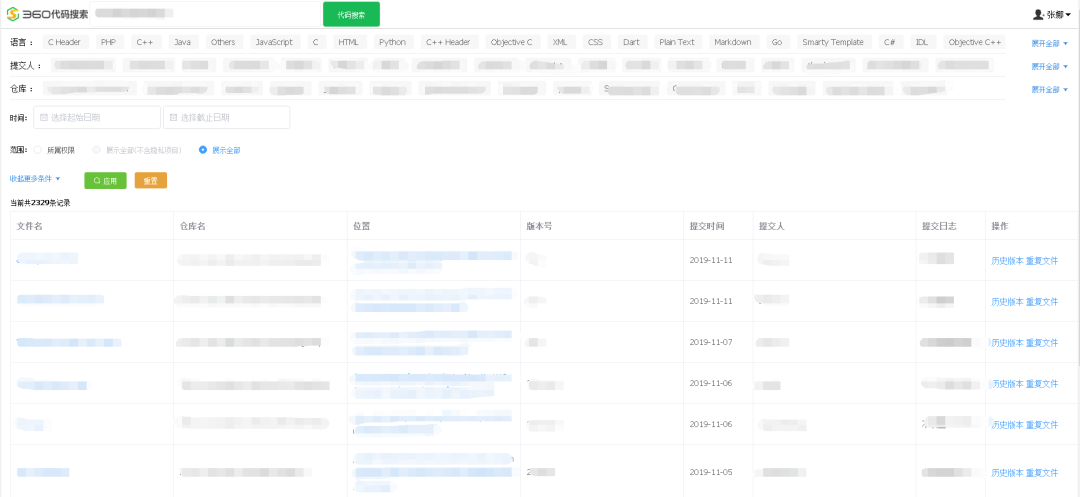
下面這個圖是代碼搜索的一個demo,主要有3部分構成,最上面是搜索輸入,中間是過濾條件,包括時間,代碼語言,歸屬人,代碼倉庫。最下面是搜索的結果,主要包括文件名,倉庫名,文件位置,版本號,提交日期和歸屬人,測試人員可以根據倉庫和歸屬人信息找到對應的開發負責人,進而督促修復漏洞。
五、總結與展望
本文主要從3個部分闡述了如何從代碼層提高產品質量:
- 第一部分是產品代碼漏洞檢查的背景和方法,主要講了檢查產品代碼漏洞的2種方法,即源代碼漏洞掃描與檢查、二進制文件漏洞掃描與檢查,但是這2種方法只能對特定項目的代碼進行檢查,隱藏的bug量是巨大的,從而引出第二部分,代碼漏洞的搜索深挖技術。
- 第二部分是本文的重點,展開講了代碼搜索的技術方案及實現細節
- 第三部分從2個方面說明了如何利用代碼搜索技術提高產品質量。
代碼搜索系統能夠快速定位問題,通過對細節的不斷探索,搜索速度顯著提升,搜索排序質量提高了,本系統輔助優化了產品代碼質量。接下來,我們將從2方面進一步優化,分別是代碼推薦結合代碼語義上下文和AI的方法,進一步提升代碼推薦的精確度,以及函數式的代碼推薦。
【本文是51CTO專欄機構360技術的原創文章,微信公眾號“360技術( id: qihoo_tech)”】