實時離線一體化助力渠道分析系統
背景
渠道分析系統,是一個多維度數據分析系統,旨在為渠道運營和渠道評估提供數據支持。隨著精細化運營需求的日益增長,對渠道數據的時效性和準確性要求也越來越高。第一代渠道分析系統,數據主要依賴離線計算產生,最小時間粒度為小時,其中,“新增用戶數”對運營人員及時調整策略起到至關重要的作用,但該數據的滯后性比較明顯,導致相應的運營決策比較被動,決策效果較差。
本文實現了一種實時計算與離線計算一體化的解決方案,為渠道新增數據提供實時、準確、高效的數據支撐。本文將從面臨挑戰、解決方案、難點攻克等幾個方面來詳細描述整個方案實施過程。
面臨挑戰
渠道數據涉及多種產品線,因此數據打點分散,數據源較多,其中包括數據中心數據、商業化數據、反作弊數據等。為了建立通用的渠道評估機制,全面的評估渠道質量從而指導結算,由此面臨的挑戰總結如下:
- 數據量大。渠道數據匯聚了多個產品的數據,每天數據量約為5~6TB,高峰期可達100MB/s。
- 數據復雜度高。產品的多樣性使得數據源種類繁多,且原始日志經過多重加密,增加了日志解析的復雜度。
- 低延遲。渠道運營數據延遲越低,對運營決策的價值越高,而新增數據由于其依賴歷史數據,其本身計算邏輯存在復雜性,增加了低延遲的處理難度。
- 數據準確性要求高。保證渠道評估的準確性才能做到精準投放和公平結算,因此對渠道數據的準確性要求較高,需要有數據校準機制。
解決方案
1. 總體設計
基于面臨的挑戰本文采用了實時計算分流、離線計算補充校準的方式來滿足上述數據要求,以下是整體數據處理架構圖。
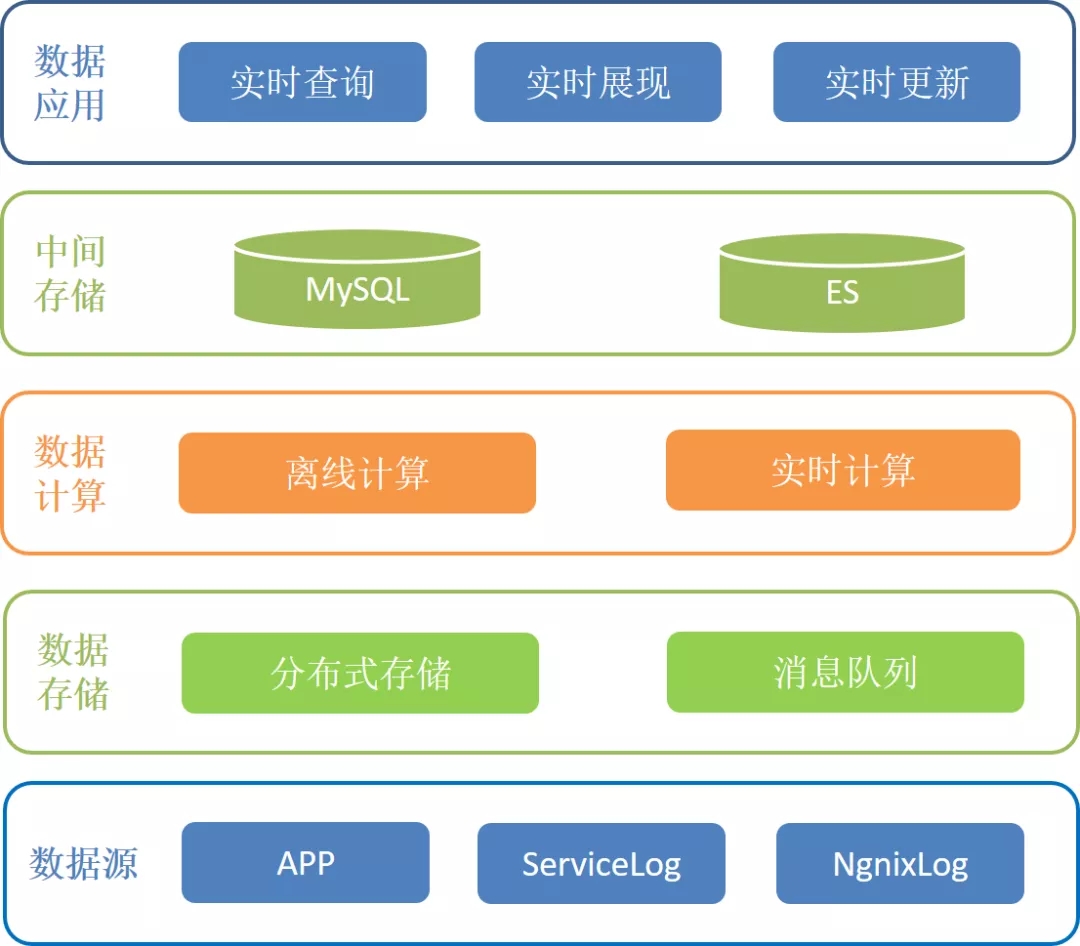
圖1 架構圖
從圖1中可以看到,本文采用雙寫的方式存儲原始數據:實時流式消息隊列存儲和分布式存儲,通過實時計算分流與離線計算補充的方式來實現實時更新數據,實時查詢數據和實時展現數據。
2. 具體實現
正如上文所提到的渠道分析的數據量級龐大,數據復雜度高,并且新增計算本身具有復雜性,同時需求本身在數據低延遲上的要求,在設計過程中,需要考慮:
- 實時流處理復雜數據的時間開銷,比如渠道原始數據經多次加密和壓縮導致解析時間開銷增大;
- 實時計算引擎自身的特性,本文涉及到的是運營投放和結算,對數據統計的正確性要求較高;
- 數據指標計算的復雜性,新增數據計算嚴重依賴歷史庫的數據查詢效率;
- 網絡環境,當不可抗力影響了實時數據的產出,及時報警并啟用離線方案校準數據。
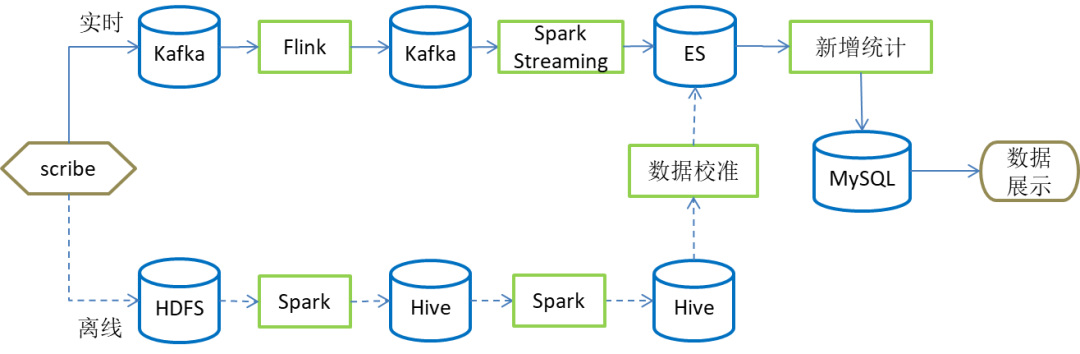
圖2 數據處理流程圖
從圖2中可以看出,為應對大量復雜的數據,盡可能降低處理延遲,實時計算部分采用了數據分層與分流相結合的技術路線,將數據計算流程拉長,采用單功能多階段的數據處理方式將數據處理拆分為三個階段:日志解析,產品分流和新增計算。在實時處理部分,采用了Flink 和Spark Streaming 相結合的方式。Flink 是一種具有高吞吐、低延遲的實時離線統一的流式數據處理引擎,非常適合本文場景中第一階段的日志解析。而Spark Streaming 是微批處理,可以將實時數據流輸入的數據劃分為一個個小批次數據流,保障后續新增計算中聚合操作穩定的分鐘級響應。為了將計算引擎的性能發揮到最大,將新增計算的延遲降到最低,在數據存儲部分,本方案采用了高性能的消息隊列Kafka 和索引速度快的ES 。另外,本文還設計了離線補充校準數據的容災方案,以確保異常情況下數據的準確性。
下面分別對日志解析,產品分流,新增計算三個處理階段和容災部分的數據校準作詳細說明。
3. 日志解析
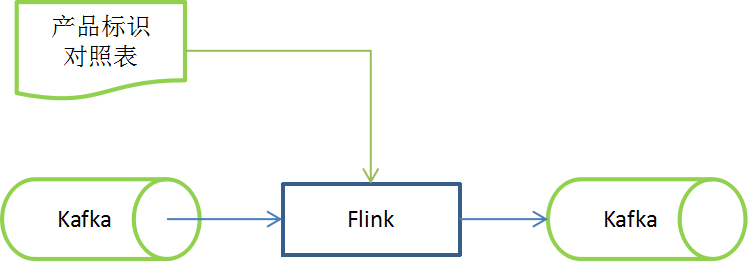
圖3 日志解析圖解
本階段采用高性能消息隊列Kafka 與低延遲計算引擎Flink相結合的方式進行日志解析。利用Flink的雙流特性,在消費原始日志消息隊列的同時會間隔一定時間同步產品標識信息,在原始日志打點規則不變的情況下,動態可配置的按需獲取數據,提升了程序的可擴展性和復用性。
4. 產品分流
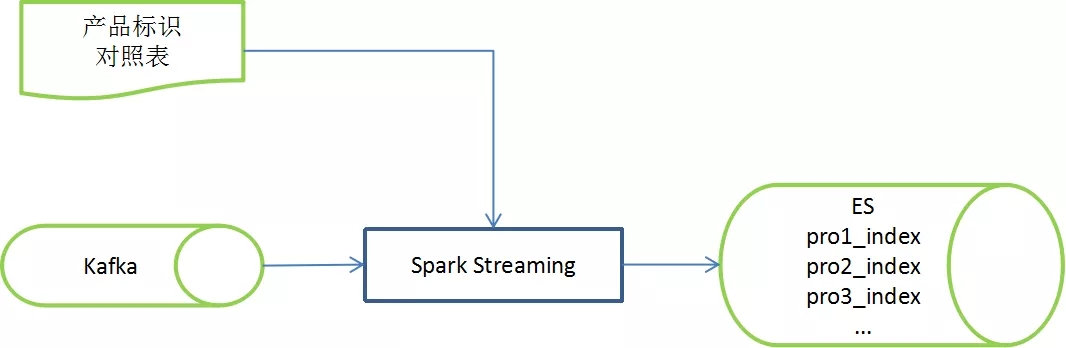
圖4 產品分流圖解
本階段采用Spark Streaming和ES對合規數據進行分流。經過日志解析,數據的量級下降,此時,使用Spark Streaming可以將流式數據轉換成微批處理,提高ES的更新效率。同時,利用ES 的主鍵唯一性,按照不同的產品標識進行數據更新。因此,ES中始終維護著一個包含所有歷史記錄數據的大表,即累計新增庫。
5. 新增計算
本階段利用ES自身的高性能,按照產品類別定期查詢ES以達到統計小時新增和累計新增的目的。借助之前的兩個階段,日志解析和產品分流,將新增計算的響應速度從小時級降到分鐘級,使得運營人員在做出決策調整投放策略后,可以在分鐘級看到投放效果。
6. 容災
容災的主要目的是在不可抗力因素發生,影響實時數據的情況下,盡可能快的將數據補回來,盡力保證數據的準確性。我們方案實現了一套與實時功能等價的離線數據校準流程。如上圖2所示,容災過程通過離線數據處理完成主要分為兩個階段:
- 第一階段日志解析階段,此階段通過離線數據處理將數據按照產品分類的方式按小時解析完成存入HIVE引擎。
- 第二階段新增計算,通過與歷史累計新增表的對比計算出新增數據。
這兩個階段是獨立于實時數據處理按小時周期進行的,當發生實時數據異常時,即會觸發補數流程進行補數。這個方案通過幾次線上實操驗證,能保證數據校準的響應維持在小時級別,數據誤差率控制在0.5%以內。
方案效果
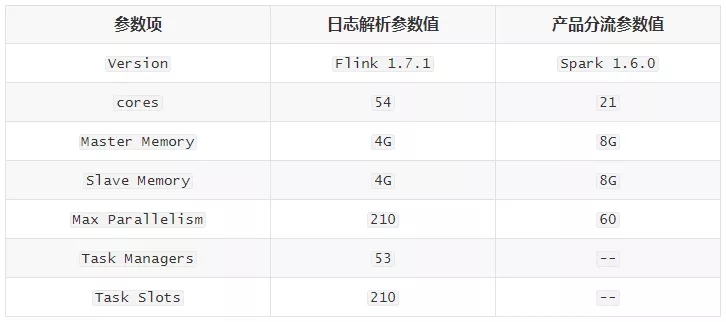
根據業務要求,渠道分析的數據延遲應控制在10分鐘以內,分析本方案中各個階段處理性能,參數配置如下:
日志解析和產品分流階段的數據處理能力如下圖所示:
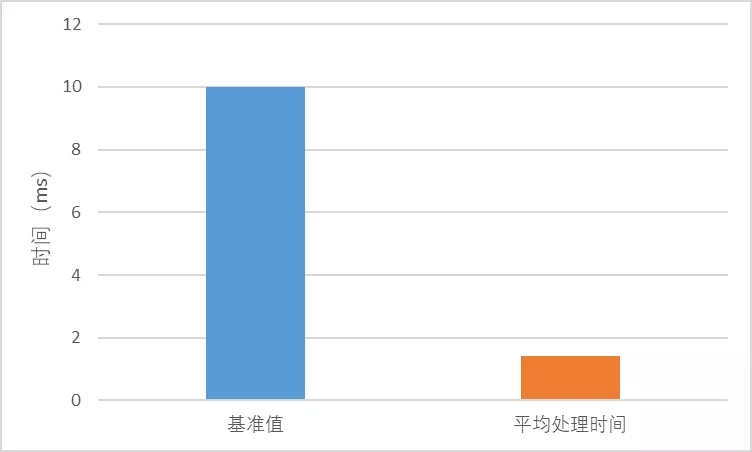
圖5 日志解析處理能力統計
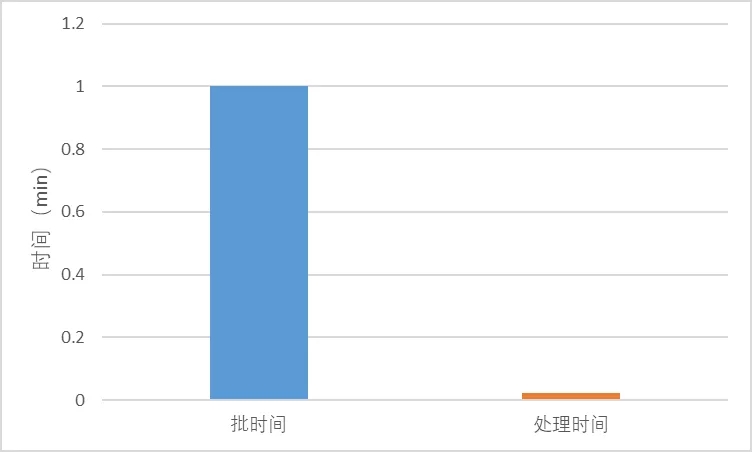
圖6 產品分流處理能力統計
日志解析階段,如上圖5為一天內所有數據的平均處理時間,可以看出,單條數據處理延遲約為1.43ms,無累積延遲。產品分流階段,如上圖6為一天內所有批次的平均處理時間,可以看出,數據處理時間約為1.39s,遠小于批時間,即本方案中數據消費能力遠大于數據生產速度,無累積延遲。
從分析結果可知,本方案整體數據延遲控制在秒級左右,遠小于業務所要求的10分鐘,滿足業務需求。其中新增計算與實時查詢部分的延遲均為ms級別,可忽略不計。
難點攻克
1. 低延遲
渠道數據原始日志里包含眾多產品,在高峰期數據量可以達到100MB/s,并且打點結構設計復雜,需要經過多重解碼和結構拆分才能得到所需字段。為了保證新增計算低延遲,本方案將數據處理流程拉長,通過數據分層,將一個復雜的數據流程分解成多個處理流程。雖然拉長了數據處理流程,但可以針對性的對不同的處理階段進行調優,例如,當日志解析階段出現堆積,可以通過調整并行度提高執行效率。細粒度的拆分數據處理流程也提高了數據的利用率,原始數據經過日志解析,將數據變成有效的規則的明細層數據,再根據明細層數據進行分流獲得不同產品的主題層數據,最終根據主題層數據計算獲得應用層數據。
2. 數據準確性穩定性保障
實時處理流程配置有完善的預警和報警措施,可一旦發生極端情況,如網絡或集群問題導致的實時任務失敗,數據丟失不可避免。因此,本方案同時設計了一套穩定的小時級離線災備流程,當發現實時處理出現故障,可及時開啟離線補數,矯正業務數據。離線校準不僅為實時計算提供正確性校驗,更保證渠道評估的準確性,為運營做到精準投放和公平結算保駕護航。
總結
本文實現了一種以實時計算為主體、離線計算為校準的分鐘級累計新增計算解決方案,在原有的小時級離線新增基礎上,將新增統計提升到分鐘級,有效的降低了響應延遲,將運營決策被動等待轉換成主動調整,為渠道運營和渠道評估提供有力的數據支持。
【本文是51CTO專欄機構360技術的原創文章,微信公眾號“360技術( id: qihoo_tech)”】