













阿里公開自研AI集群細節:64個GPU,百萬分類訓練速度提升4倍
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
從節點架構到網絡架構,再到通信算法,阿里巴巴把自研的高性能AI集群技術細節寫成了論文,并對外公布。
論文名為EFLOPS: Algorithm and System Co-design for a High Performance Distributed Training Platform,被計算機體系結構頂級會議HPCA 2020收錄。阿里是國內唯一有論文收錄的企業,論文作者之一、阿里資深技術專家蔣曉維在會議現場分享了論文內容。

除了展示AI集群技術細節,他還介紹了其如何為阿里巴巴內部業務和算法帶來價值。這一集群已應用于阿里巴巴計算平臺的人工智能訓練平臺(PAI),服務阿里巴巴的人工智能業務的模型訓練:
能將拍立淘百萬分類大模型的訓練速度提升4倍,并首次支持千萬分類模型的訓練;在提升阿里巴巴翻譯模型精度的同時,能將訓練時間從100小時降低至12小時。
而且與世界頂級的AI計算系統相比,阿里的AI集群雖然使用了性能較低的硬件資源,但表現出了相當的性能。
這是阿里巴巴首次對外披露高性能AI集群的性能,具體情況如何?我們根據阿里研究團隊提供的解讀一一來看。
從業務出發,優化AI集群架構
由于深度神經網絡的技術突破,圍繞AI的技術研究,如AI算法模型、訓練框架、以及底層的加速器設計等,引起越來越多的關注,而且應用越來廣泛,已經落地到社會生活的各個方面。
“然而極少有人從集群架構角度探究過,AI業務的運行模式與傳統大數據處理業務的差別,以及AI集群的架構設計應該如何優化,“阿里研究團隊表示。
他們認為,雖然AI業務存在很強的數據并行度,但與大數據處理業務和高性能計算業務特征存在明顯的不同。核心差別有兩點:
第一,AI業務的子任務獨立性很低,需要周期性地進行通信,實現梯度的同步;第二,AI業務的運行以加速部件為中心,加速部件之間直接通信的并發度顯著高于傳統服務器。
因此,在傳統數據中心的服務器架構和網絡架構上運行AI業務,會存在很多嚴重的問題。
具體來說,服務器架構問題,主要是資源配置不平衡導致的擁塞問題,以及PCIe鏈路的QoS問題。
一般情況下,傳統服務器配備一張網卡用于節點間通信,為了支持AI業務會配置多個GPU。
但AI訓練經常需要在GPU之間進行梯度的同步,多GPU并發訪問網絡,唯一的網卡就會成為系統的瓶頸。
此外,PCIe鏈路上的帶寬分配與路徑長度密切相關,長路徑獲得的帶寬分配較低,而跨Socket通信的問題更加嚴重。
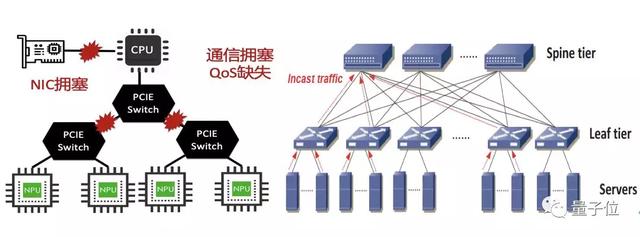
網絡架構問題,主要在于AI訓練中同步通信導致的短板效應。網絡擁塞本是一個非常普遍的問題,相關研究已經持續了幾十年。
但擁塞控制算法的最終目的,在于對兩個碰撞的流進行限速,使其盡快達到均分物理帶寬的目的,并不能解決AI訓練集群的通信效率問題。
由于AI業務通信的同步性,每個通信事務的最終性能決定于最慢的連接。均分帶寬意味著事務完成時間的成倍提升,會嚴重影響AI通信的性能。
基于此,阿里巴巴決定為AI業務自研高性能AI集群。
阿里AI集群的關鍵技術
阿里巴巴自研的高性能AI集群名為EFlops,關鍵技術一共有三個:網絡化異構計算服務器架構、高擴展性網絡架構、與系統架構協同的高性能通信庫。
為了避免網卡上的數據擁塞,他們為每個GPU提供專用的網卡,來負責與其他GPU的通信。
此外,基于Top-of-Server的設計思想,將節點內加速器之間的通信導出到節點外,并利用成熟的以太網QoS機制來保證擁塞流量之間的公平性。
研究團隊認為,隨著加速器芯片計算能力的快速提升,對通信性能提出越來越高的需求,這種多網卡的網絡化異構計算服務器架構將很快成為主流。
在網絡架構層面,EFlops設計了BiGraph網絡拓撲,在兩層網絡之間提供了豐富的鏈路資源,提供了跨層路由的可控性。
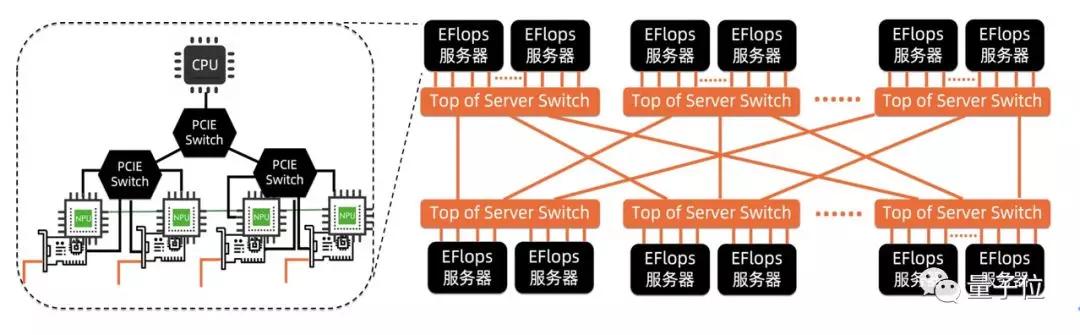
配合多網卡服務器結構,他們在EFlops項目中提出了BiGraph網絡拓撲,其與傳統的Fat-tree拓撲有相似之處,也存在根本的區別。
與Fat-tree拓撲類似的地方在于,他們將網絡中的分為兩部分(Upper和Lower),各部分之間通過Clos架構進行互連,形如兩層Fat-tree拓撲的Spine和Leaf交換機。
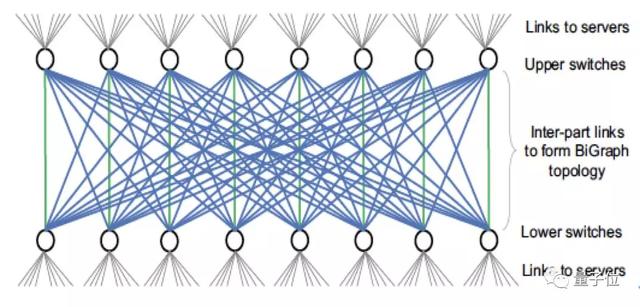
與Fat-tree不同的是,他們在兩部分交換機上都可以直接接入計算服務器;即每一個交換機都扮演了Fat-tree拓撲中的Spine和Leaf兩個角色,最大跳步數為3。
也給BiGraph拓撲帶來了兩個重要的特性:
一方面,在兩層交換機之間提供了豐富的物理鏈路資源。在N個計算服務器的系統中,兩層交換機之間至少存在著N/2個物理鏈路可供使用。另一方面,接入不同層次的任意兩個計算服務器之間的最短路徑具有唯一性。
因此,他們可以充分利用這一特性,在通信庫甚至更高層次進行服務器間通信模式的管理。比如,在建立連接的時候,選擇合適源和目的服務器,來控制網絡上的路徑選擇。
想要說清楚這一點,需要引入一個新的概念:Allreduce——數據并行訓練場景下的最主要集合通信操作。
其中常用的通信算法有Ring-based(Ring)、Tree-based(Tree)和Halving-Doubling(HD)等。
在阿里巴巴的這篇論文中,主要關注的是Ring和HD,前者是應用范圍最廣的算法之一,后者是他們在這一研究中的優化對象。
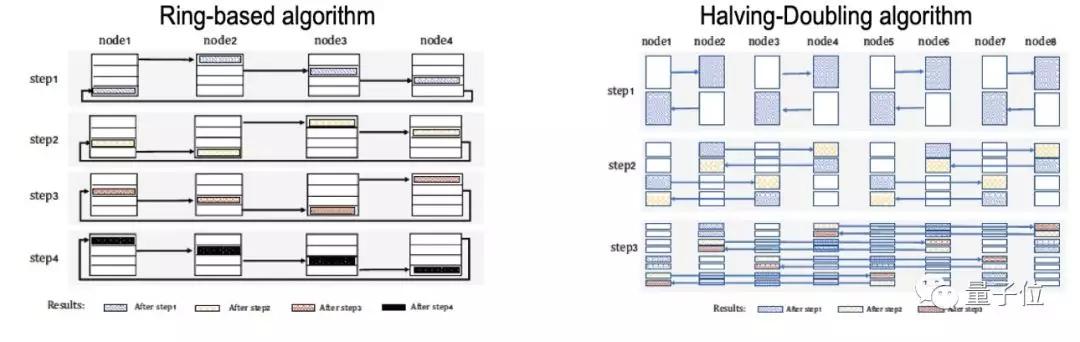
Ring和HD算法在數據傳輸量上沒有區別,都是2S;其中S是Message的大小。從通信次數角度看,Ring算法需要N-1個Step的通信,而HD算法只需要log2N個Step;其中N是參與節點個數。
而Ring算法只需要N個連接,而HD算法需要N*log2N個連接。需要特別指出的是,HD算法的每個Step只需要N/2個連接。
結合BiGraph拓撲的特性進行分析,可以看到:BiGraph拓撲兩層交換機之間存在N/2個物理鏈路,而HD算法每個step需要N/2個連接。
BiGraph拓撲兩層交換機之間最短路徑的確定性,提供了一種可能性:將HD算法的連接和BiGraph拓撲的物理鏈路進行一一映射,避免它們之間的鏈路爭用,以徹底解決網絡擁塞問題。
基于此,他們也進一步提出了Rank映射算法,將HD算法的通信連接一一映射至BiGraph網絡的物理鏈路,避免了網絡的擁塞,該算法Halving-Doubling with Rank-Mapping(HDRM)已經在阿里定制的集合式通信庫ACCL實現。具體步驟如下:

如此集群,性能如何?
為了評估EFlops系統的性能,他們部署了16個節點,共計64個GPU的訓練集群。其中每個節點配置了4個Tesla V100-32G的GPU,以及4個ConnectX-5 100Gbps網卡。
網絡環境按照BiGraph拓撲進行設計,其中8個物理交換機劃分為16個虛擬交換機,分別部署于BiGraph的兩層。
研究團隊用MLPerf的ResNet50模型評估了集群性能,具體方式是在達到指定準確率之后,計算單位時間圖片處理數量。
下圖呈現了EFlops系統和單網卡系統的性能對比,包括全系統吞吐量和單GPU平均吞吐量。
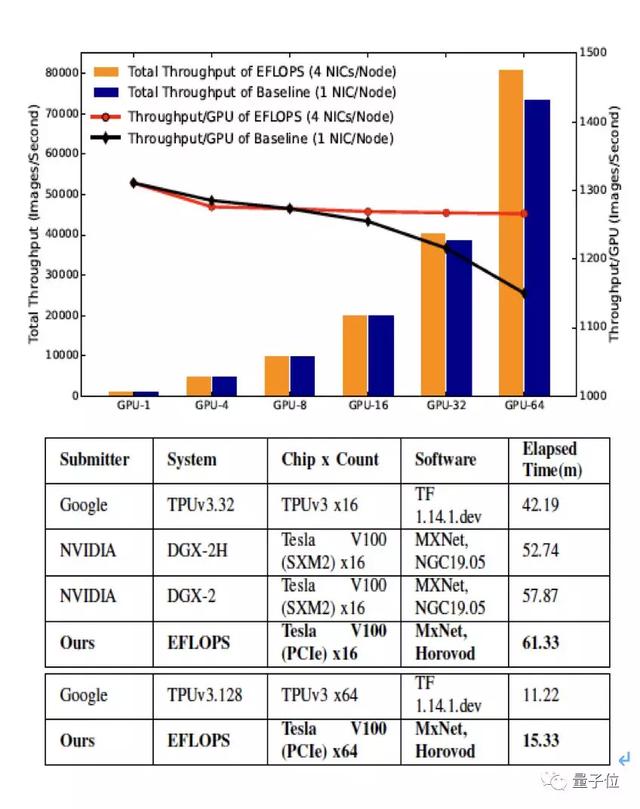
可以看到,EFlops系統的性能基本達到了線性擴展,而單網卡系統的單位吞吐量明顯隨著規模逐步下降。
與世界頂級的AI計算系統相比,EFlops雖然使用了性能較低的硬件資源(V100-PCIe性能低于V100-SXM2約10%)也表現出了相當的性能。
此外,他們還分析了阿里巴巴內部應用的性能收益。以拍立淘百萬分類模型為例,EFlops系統可以提升通信性能5.57倍,端到端性能34.8%。
因為通信量占比不高,HDRM算法提升通信性能43.5%,整體性能4.3%。對BERT模型而言,通信量明顯高于拍立淘百萬分類模型,僅HDRM算法就可以提升通信性能36%,端到端性能15.8%。
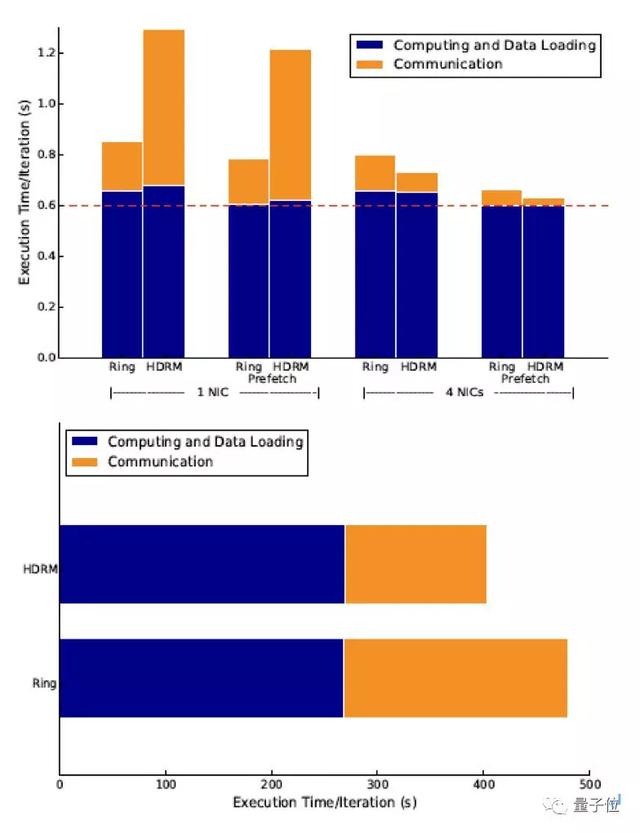
研究團隊表示,可以預見,隨著系統規模進一步增長,EFlops的性能收益將顯著提升。基于64節點集群的收益,他們進一步搭建了512 GPUs的高性能AI訓練集群。
初步的評測結果顯示,基于ImageNet訓練集,在Resnet50模型上,EFlops集群仍然能保持接近線性的擴展性。
阿里巴巴基礎設施團隊打造
EFlops集群一共有17名阿里的技術專家參與打造,大多來自阿里巴巴基礎設施團隊,平頭哥團隊提供支持。

論文的第一作者是董建波,畢業于中科院計算所,現在是阿里巴巴高級技術專家。論文的通訊作者是謝源——阿里巴巴達摩院高級研究員、平頭哥首席科學家。
謝源是計算體系結構、芯片設計領域大牛級別的存在,研究方向是計算機體系結構、集成電路設計、電子設計自動化、和嵌入式系統設計,已發表過300多篇頂級期刊和會議論文。
在獲得IEEE、AAAS、ACM Fellow稱號之后,他在2月28日再次獲得國際學術榮譽——IEEE CS 2020年度技術成就獎。



























