無(wú)需訓(xùn)練,F(xiàn)ast-DetectGPT讓文本檢測(cè)速度提升340倍
大語(yǔ)言模型如 ChatGPT 和 GPT-4 在各個(gè)領(lǐng)域?qū)θ藗兊纳a(chǎn)和生活帶來(lái)便利,但其誤用也引發(fā)了關(guān)于虛假新聞、惡意產(chǎn)品評(píng)論和剽竊等問題的擔(dān)憂。本文提出了一種新的文本檢測(cè)方法 ——Fast-DetectGPT,無(wú)需訓(xùn)練,直接使用開源小語(yǔ)言模型檢測(cè)各種大語(yǔ)言模型生成的文本內(nèi)容。
Fast-DetectGPT 將檢測(cè)速度提高了 340 倍,將檢測(cè)準(zhǔn)確率相對(duì)提升了 75%,成為新的 SOTA。在廣泛使用的 ChatGPT 和 GPT-4 生成文本的檢測(cè)上,均超過(guò)商用系統(tǒng) GPTZero 的準(zhǔn)確率。
Fast-DetectGPT 同時(shí)做到了高準(zhǔn)確率、高速度、低成本、通用,掃清了實(shí)際應(yīng)用的障礙!

- 論文題目:Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature
- 論文鏈接:https://openreview.net/forum?id=Bpcgcr8E8Z
- 代碼鏈接:https://github.com/baoguangsheng/fast-detect-gpt
研究動(dòng)機(jī)
大語(yǔ)言模型(LLMs)在各個(gè)領(lǐng)域已產(chǎn)生了深遠(yuǎn)影響。這些模型在新聞報(bào)道、故事寫作和學(xué)術(shù)研究等多元領(lǐng)域提升了生產(chǎn)力。然而,它們的誤用也帶來(lái)了一些問題,特別是在假新聞、惡意產(chǎn)品評(píng)論和剽竊方面。這些模型生成的內(nèi)容流暢連貫,甚至讓專家都難以辨別其來(lái)源是人類還是機(jī)器。因此,我們需要可靠的機(jī)器生成文本檢測(cè)方法來(lái)解決這個(gè)問題。
現(xiàn)有的檢測(cè)器主要分為兩類:有監(jiān)督分類器和零樣本分類器。雖然有監(jiān)督分類器在其特定訓(xùn)練領(lǐng)域表現(xiàn)出色,但在面對(duì)來(lái)自不同領(lǐng)域或不熟悉模型生成的文本時(shí),其表現(xiàn)會(huì)變差。零樣本分類器則能夠免疫領(lǐng)域特定的退化,并且在檢測(cè)精度上可以與有監(jiān)督分類器相媲美。
然而,典型的零樣本分類器,如 DetectGPT,需要執(zhí)行大約一百次模型調(diào)用或與 OpenAI API 等服務(wù)交互來(lái)創(chuàng)建擾動(dòng)文本,這導(dǎo)致了過(guò)高的計(jì)算成本和較長(zhǎng)的計(jì)算時(shí)間。同時(shí)它需要用生成文本的源語(yǔ)言模型來(lái)進(jìn)行檢測(cè)的計(jì)算,使得該方法不能用于檢測(cè)由未知模型生成的文本。
在這篇論文中,我們提出了一種新的假設(shè)來(lái)檢測(cè)機(jī)器生成的文本。我們認(rèn)為,人類和機(jī)器在給定上下文的情況下選擇詞匯存在明顯的差異,而機(jī)器和機(jī)器之間的差異不明顯。利用這種差異我們能夠有效地用一套模型和方法檢測(cè)不同模型生成的文本內(nèi)容。
方法
Fast-DetectGPT 的操作基于一個(gè)前提,即人類和機(jī)器在文本生成過(guò)程中傾向于選擇不同的詞匯,人類的選擇比較多樣,而機(jī)器更傾向于選擇具有更高模型概率的詞匯。
這個(gè)假設(shè)源于這樣一個(gè)事實(shí),即在大規(guī)模語(yǔ)料庫(kù)上預(yù)訓(xùn)練的 LLM 反映的是人類的集體寫作行為,而非個(gè)體的寫作行為,這導(dǎo)致它們?cè)诮o定上下文時(shí)的詞匯選擇存在差異。
這個(gè)假設(shè)在一定程度上也得到了文獻(xiàn)中的觀察結(jié)果的支持,這些觀察結(jié)果表明,機(jī)器生成的文本通常具有比人類寫作的文本有更高的統(tǒng)計(jì)概率(或更低的困惑度)。
然而,我們的方法并不僅僅依賴于機(jī)器生成文本具有更高的統(tǒng)計(jì)概率的假設(shè)。而是進(jìn)一步假設(shè),在條件概率函數(shù)中,機(jī)器生成的文本周圍的局部空間存在一個(gè)正曲率。據(jù)此,我們提出條件概率曲率指標(biāo),用以區(qū)分機(jī)器生成文本和人類撰寫文本。
我們的實(shí)驗(yàn)觀察如圖 1 所示,在四個(gè)不同開源模型上,人類撰寫文本的條件概率曲率近似一個(gè)均值為 0 的正態(tài)分布,而機(jī)器生成文本的條件概率曲率近似一個(gè)均值為 3 的正態(tài)分布,這兩個(gè)分布只有少量的重疊。根據(jù)這種分布上的特點(diǎn),我們可以選擇一個(gè)閾值,大于這個(gè)閾值判斷為機(jī)器生成文本,小于則為人類撰寫,從而獲得一個(gè)檢測(cè)器。
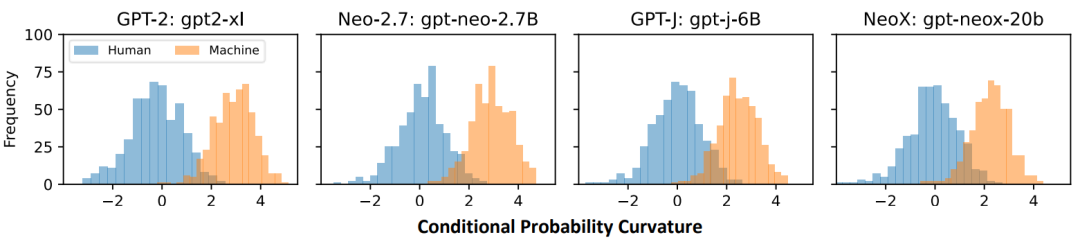
圖 1:條件概率曲率在不同源模型設(shè)定上的分布
條件概率曲率
給定一個(gè)輸入文本段落 x 和模型 ,我們使用的條件概率可以形式化的表達(dá)為:
,我們使用的條件概率可以形式化的表達(dá)為:

可以看到,在給定 x 的條件下, 的不同位置上的 tokens
的不同位置上的 tokens 之間是互相獨(dú)立的。這種條件獨(dú)立性質(zhì)將給我們的采樣帶來(lái)極大的便利。
之間是互相獨(dú)立的。這種條件獨(dú)立性質(zhì)將給我們的采樣帶來(lái)極大的便利。
進(jìn)一步,給定打分模型 和采樣模型
和采樣模型 ,我們將條件概率曲率形式化的表達(dá)為:
,我們將條件概率曲率形式化的表達(dá)為:

其中:


 表示由采樣模型
表示由采樣模型 生成的樣本
生成的樣本 在打分模型
在打分模型 上的期望得分,
上的期望得分, 表示得分的期望方差。我們用隨機(jī)樣本的平均對(duì)數(shù)概率來(lái)近似期望得分
表示得分的期望方差。我們用隨機(jī)樣本的平均對(duì)數(shù)概率來(lái)近似期望得分 ,用對(duì)數(shù)概率的樣本方差來(lái)近似期望方差
,用對(duì)數(shù)概率的樣本方差來(lái)近似期望方差 。
。
條件獨(dú)立采樣
對(duì)替代tokens 的獨(dú)立采樣是 Fast-DetectGPT 能快速計(jì)算的關(guān)鍵。具體來(lái)說(shuō),我們?cè)诠潭ㄎ谋?x 的條件下,從
的獨(dú)立采樣是 Fast-DetectGPT 能快速計(jì)算的關(guān)鍵。具體來(lái)說(shuō),我們?cè)诠潭ㄎ谋?x 的條件下,從 中采樣每個(gè)token
中采樣每個(gè)token ,而不依賴于其他采樣的token。
,而不依賴于其他采樣的token。
在實(shí)踐中,我們可以簡(jiǎn)單地通過(guò)一行 PyTorch 代碼生成 10,000 個(gè)樣本(我們的默認(rèn)設(shè)置):samples = torch.distributions.categorical.Categorical (logits=lprobs).sample ([10000]),其中 lprobs 是 的對(duì)數(shù)概率分布,j 從 0 到 x 的長(zhǎng)度。
的對(duì)數(shù)概率分布,j 從 0 到 x 的長(zhǎng)度。
采樣過(guò)程對(duì)我們理解 Fast-DetectGPT 的機(jī)制起著關(guān)鍵的作用。為了判斷給定上下文中的一個(gè)token是機(jī)器生成的還是人類編寫的,必須將其與同一上下文中的一系列替代token進(jìn)行比較。通過(guò)采樣大量的替代token(比如說(shuō) 10,000 個(gè)),我們可以有效地描繪出它們的 值的分布。將原始文本token的
值的分布。將原始文本token的 值放在這個(gè)分布中,可以清楚地看到它的相對(duì)位置,使我們能夠確定它是一個(gè)異常值還是一個(gè)更典型的選擇。這個(gè)基本的洞察形成了 Fast-DetectGPT 方法的核心理念。
值放在這個(gè)分布中,可以清楚地看到它的相對(duì)位置,使我們能夠確定它是一個(gè)異常值還是一個(gè)更典型的選擇。這個(gè)基本的洞察形成了 Fast-DetectGPT 方法的核心理念。
檢測(cè)過(guò)程
如圖 2 所示,F(xiàn)ast-DetectGPT 提出了一個(gè)新的三步檢測(cè)過(guò)程,包括 1)采樣 -- 我們引入一個(gè)采樣模型,給定條件 x 生成備選樣本 ,2)打分 -- 通過(guò)將 x 作為輸入的評(píng)分模型的單次前向傳遞,可以輕易獲得條件概率。所有樣本都可以在同一預(yù)測(cè)分布中進(jìn)行評(píng)估,因此我們不需要多次調(diào)用模型,以及 3)比較 -- 段落和樣本的條件概率被比較以計(jì)算條件概率曲率。更多的細(xì)節(jié)在論文的算法部分進(jìn)行了詳細(xì)描述。
,2)打分 -- 通過(guò)將 x 作為輸入的評(píng)分模型的單次前向傳遞,可以輕易獲得條件概率。所有樣本都可以在同一預(yù)測(cè)分布中進(jìn)行評(píng)估,因此我們不需要多次調(diào)用模型,以及 3)比較 -- 段落和樣本的條件概率被比較以計(jì)算條件概率曲率。更多的細(xì)節(jié)在論文的算法部分進(jìn)行了詳細(xì)描述。

圖 2:Fast-DetectGPT vs DetectGPT
我們發(fā)現(xiàn) “采樣” 和 “打分” 兩個(gè)步驟在實(shí)現(xiàn)上可以進(jìn)一步合并,并有一個(gè)解析解,而不是采樣近似,詳細(xì)論述和證明見論文附錄 B。此外,我們發(fā)現(xiàn)使用相同的模型進(jìn)行采樣和評(píng)分時(shí),條件概率曲率與簡(jiǎn)單的似然函數(shù)和熵基線有緊密的聯(lián)系,具體論述見論文第 2 章結(jié)束部分。
實(shí)驗(yàn)結(jié)果

表 1:結(jié)果概況
如表 1 所示,F(xiàn)ast-DetectGPT 和基線 DetectGPT 相比,在速度上提升 340 倍,在檢測(cè)準(zhǔn)確率上相對(duì)提升約 75%,具體展開如下。
340 倍的推理加速
我們比較了 Fast-DetectGPT 和 DetectGPT 在 Tesla A100 GPU 上的推理時(shí)間(不包括初始化模型的時(shí)間)。盡管 DetectGPT 使用了 GPU 批處理,將 100 個(gè)擾動(dòng)分成 10 個(gè)批次,但它仍然需要大量的計(jì)算資源。它在五次運(yùn)行中(對(duì)應(yīng) 5 個(gè)源模型)總共需要 79,113 秒(大約 22 小時(shí))。相比之下,F(xiàn)ast-DetectGPT 僅用 233 秒(大約 4 分鐘)就完成了任務(wù),實(shí)現(xiàn)了約 340 倍的顯著加速,突顯出其顯著的性能提升。
準(zhǔn)確的 ChatGPT 和 GPT-4 文本檢測(cè)
我們進(jìn)一步在黑盒環(huán)境中評(píng)估 Fast-DetectGPT,使用由 ChatGPT 和 GPT-4 生成的段落來(lái)模擬真實(shí)世界場(chǎng)景。我們?yōu)槊總€(gè)數(shù)據(jù)集和源模型生成了 150 個(gè)樣本,包括 150 個(gè)模型生成的文本段落和 150 個(gè)人工撰寫的文本段落。

表 2:ChatGPT 和 GPT-4 生成內(nèi)容的檢測(cè)效果(AUROC)
如表 2 所示,F(xiàn)ast-DetectGPT 展現(xiàn)出一致的優(yōu)越的檢測(cè)能力。它在 ChatGPT 和 GPT-4 的相對(duì) AUROC 上分別超過(guò)了 DetectGPT 的 78.3%和 75.1%。與監(jiān)督檢測(cè)器 RoBERTa-base/large 相比,F(xiàn)ast-DetectGPT 實(shí)現(xiàn)了更高的整體準(zhǔn)確性。這些結(jié)果展示 Fast-DetectGPT 在真實(shí)世界場(chǎng)景中工作的潛力。
更有趣的是,商業(yè)模型 GPTZero 在新聞(XSum)上表現(xiàn)較好,但在故事(WritingPrompts)和技術(shù)寫作(PubMedQA)上表現(xiàn)較差。我們猜測(cè)該模型是有監(jiān)督的檢測(cè)器,其訓(xùn)練數(shù)據(jù)中可能包含比較多的新聞?wù)Z料。雖然商用模型一般都有額外的針對(duì)性的效果上的改進(jìn),但總體上 Fast-DetectGPT 比 GPTZero 還是要好 2 到 3 個(gè)點(diǎn)。
低誤報(bào)率、高召回率
在實(shí)際使用中,我們希望檢測(cè)器有較低的誤報(bào)率,否則會(huì)給用戶帶來(lái)困擾,傷害真實(shí)的內(nèi)容創(chuàng)作者。在較低誤報(bào)率的前提下,我們希望檢測(cè)器有較高的召回率,能夠識(shí)別出大部分機(jī)器生成的內(nèi)容。
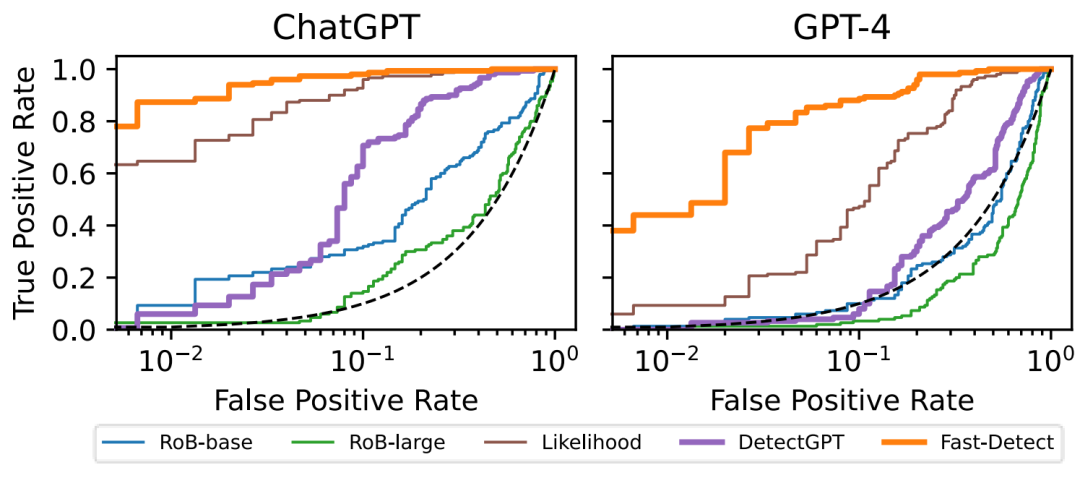
圖 3:誤報(bào)率(False Positive Rate) vs 召回率(True Positive Rate)
如圖 3 所示,在正負(fù)樣本一比一的 WritingPrompts 評(píng)測(cè)數(shù)據(jù)集上,橙色線標(biāo)示的 Fast-DetectGPT 對(duì)比紫色線標(biāo)示的 DetectGPT 和其它方法。我們可以看到,在誤報(bào)率為 1% 的條件下,使用 Fast-DetectGPT 能獲得的召回率比其它方法高出很多。比如說(shuō),在 ChatGPT 生成文本上,F(xiàn)ast-DetectGPT 能達(dá)到 87% 的召回率,而 Likelihood 和 DetectGPT 只有 64% 和 6% 的召回率。在 GPT-4 生成文本上,差距進(jìn)一步拉大,F(xiàn)ast-DetectGPT 能達(dá)到 44% 的召回率,而 Likelihood 和 DetectGPT 只有 9% 和 0% 的召回率。
文本越長(zhǎng)準(zhǔn)確率越高
零樣本檢測(cè)器由于其統(tǒng)計(jì)性質(zhì),對(duì)較短的文本段落表現(xiàn)通常比較差。我們通過(guò)將 WritingPrompts 評(píng)測(cè)數(shù)據(jù)集中的文本段落截?cái)嗟礁鞣N目標(biāo)長(zhǎng)度來(lái)進(jìn)行評(píng)估。

圖 4:不同長(zhǎng)度上的魯棒性
如圖 4 所示,這些檢測(cè)器在由 ChatGPT 生成的段落上,整體檢測(cè)準(zhǔn)確率隨著段落長(zhǎng)度的增加而增加。在 GPT-4 生成的段落上,檢測(cè)準(zhǔn)確率顯示出不一致的趨勢(shì)。
具體來(lái)說(shuō),當(dāng)段落長(zhǎng)度增加時(shí),有監(jiān)督檢測(cè)器的性能表現(xiàn)出下降趨勢(shì),而 DetectGPT 在開始時(shí)經(jīng)歷了一個(gè)增漲,然后在段落長(zhǎng)度超過(guò) 90 個(gè)詞時(shí)出現(xiàn)了顯著的下降。
我們推測(cè),有監(jiān)督檢測(cè)器和 DetectGPT 的非單調(diào)趨勢(shì)源于它們將段落視為一個(gè)整體的token鏈(token chain),導(dǎo)致其檢測(cè)效果不能泛化到不同長(zhǎng)度的文本上。相比之下,F(xiàn)ast-DetectGPT 在段落長(zhǎng)度增加時(shí)表現(xiàn)出一致的、單調(diào)的準(zhǔn)確性增加,展示穩(wěn)健的效果。
結(jié)語(yǔ)
主要結(jié)論: 通過(guò)研究發(fā)現(xiàn),條件概率曲率是機(jī)器生成文本上更本質(zhì)的指標(biāo),驗(yàn)證了我們關(guān)于機(jī)器和人類文本生成過(guò)程區(qū)別的假設(shè)。基于這個(gè)新假設(shè),檢測(cè)器 Fast-DetectGPT 在 DetectGPT 基礎(chǔ)上加速了兩個(gè)數(shù)量級(jí),并在白盒和黑盒設(shè)置中都顯著提高了檢測(cè)精度。
未來(lái)展望: Fast-DetectGPT 依賴于預(yù)訓(xùn)練語(yǔ)言模型來(lái)覆蓋多個(gè)領(lǐng)域和語(yǔ)言,但沒有單一的模型可以覆蓋所有的語(yǔ)言和領(lǐng)域,要使檢測(cè)器更通用,我們可能需要聯(lián)合多個(gè)語(yǔ)言模型以獲得更全面的覆蓋。另一方便,條件概率曲率能區(qū)分機(jī)器生成文本和人類撰寫文本,也可能區(qū)分由兩個(gè)不同模型生成的文本(作者識(shí)別),還可能用于判別 OOD 文本(OOD 檢測(cè))。這些方向的應(yīng)用值得進(jìn)一步研究。