













別再讓數據科學家管理Kubernetes集群了……
生產機器學習具有組織性問題。
該問題是伴隨其出現的副產品,因為生產機器學習出現時間相對較短。
盡管更成熟的領域(如網絡開發)經過數十年的探索已開發到極致,但生產機器學習還沒有步入這一階段。
舉個例子,假如你的任務是為初創企業建立一個產品工程團隊,來負責開發某個網絡應用程序。即使沒有組建團隊的經驗,你也能找到很多有關如何建立和發展工程團隊的文章和書籍。
現在,假如你的公司是一家涉足機器學習的初創企業。你已經聘請了一位數據科學家來領導完成最初的工作,且成效顯著。機器學習與公司產品的關系越來越緊密,數據科學家承擔的責任越來越重大,很明顯,機器學習團隊需要發展。
這種情況下,沒有那么多有關如何組建生產機器學習團隊的文章和書籍供人參考。
這種情況十分普遍,機器學習公司的新責任(尤其是基礎設施)交由數據科學家承擔的情況時有發生。
這樣是不對的。
機器學習和機器學習基礎設施之間的區別
現在,平臺工程師和產品工程師之間的區別已經很清楚了。同樣,數據分析師和數據工程師之間也有著明顯的不同。
很多公司的機器學習仍然缺少這樣的專業知識。
要了解區分機器學習和機器學習基礎設施為什么這么重要,這對于研究兩者各自的工作內容和所需工具會很有幫助。
為了設計和訓練新模型,數據科學家需要:
- 花時間在notebook上分析數據、進行實驗。
- 考慮數據結構、為數據集選擇正確的模型體系等問題。
- 使用Python、R、Swift或Julia之類的編程語言。
- 在PyTorch或TensorFlow等機器學習框架方面有自己的見解。
換句話說,數據科學家的職責、技能和工具將圍繞操縱數據來開發模型,最終輸出的將是能夠提供最準確預測的模型。
機器學習基礎設施與之截然不同。
將模型投入生產的普遍做法是將其作為微服務部署到云端。要將模型部署為生產應用程序界面,工程師需要:
- 同時關注分配文件、終端和云服務商的控制臺,以優化穩定性、延遲和成本。
- 考慮自動伸縮實例、更新模型(前提是應用程序界面不崩潰)、在圖形處理器上進行推理等問題。
- 使用Docker、Kubernetes、Istio、Flask等工具,以及云服務商提供的任何服務或應用程序界面。
下圖展示了機器學習和機器學習基礎設施之間的區別,十分形象,易于理解:
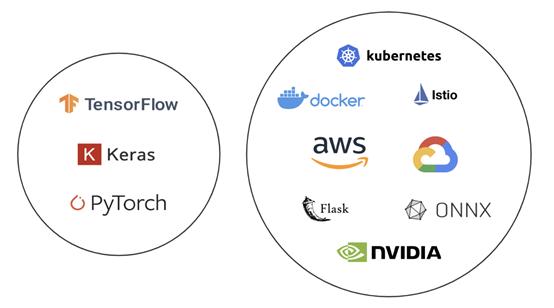
機器學習vs.機器學習基礎設施
直觀來看,數據科學家應該處理左邊的圓圈,而不是右邊的圓圈。
非專業人士管理基礎設施有什么問題?
假如必須指定某個人來管理你的機器學習基礎設施,但你又不想讓他專職完成這項工作,那么只有兩個選擇:
- 數據科學家,因為他們熟悉機器學習。
- 開發運營工程師,因為他們熟悉通用基礎設施。
這兩個選擇都有問題。
首先,數據科學家應該用盡可能多的時間做他們擅長的工作——數據科學。雖然學習基礎設施對他們來說并不是難事,但基礎設施和數據科學都是專職工作,將數據科學家的時間分配給這兩項工作會降低工作質量。
其次,公司需要專門負責機器學習基礎設施的人員。在生產過程中提供模型與托管網絡應用程序不同,需要有人專門負責該項工作,能夠在組織內部宣傳機器學習基礎設施。
事實證明,這樣的宣傳至關重要。筆者接觸過很多機器學習公司,令人驚訝的是,公司內部成員的瓶頸通常不是來自技術方面的挑戰,而是來自公司自身的挑戰。
例如,筆者見過某些機器學習團隊需要圖形處理器 (GPUs)進行推理——GPT-2這樣的大模型基本上需要圖形處理器提供合理的延遲——卻無法獲得它們,因為這些團隊的基礎設施由更大的開發運營團隊管理,而開發運營團隊并不想把費用記在自己的賬上。
有人專門負責機器學習基礎設施,意味著該公司不僅擁有了能夠不斷改進基礎設施的團隊成員,還擁有了能夠滿足團隊需要的宣傳者。
那么誰來管理基礎設施呢?
機器學習基礎設施工程師。
這樣一個頭銜也許并不能讓人認同,先把頭銜的事放到一邊,必須承認的是,生產機器學習仍然處于發展的早期階段,更不用說頭銜了。不同的公司可能會賦予其不同的稱呼:
- 機器學習基礎設施工程師
- 數據科學平臺工程師
- 機器學習生產工程師
成熟的機器學習公司(比如Spotify)正在招聘這樣的職位:
網飛公司也是如此:

隨著支持機器學習的功能(比如Gmail的Smart Compose、優步的ETA預測和網飛公司的內容推薦)在軟件中越來越普遍,機器學習基礎設施也變得越來越重要。
如果人們希望未來存在大量支持機器學習的軟件,那么消除基礎設施瓶頸至關重要——為此,人們需要將其視為真正的專業知識,讓數據科學家專注于數據科學工作。
別再讓數據科學家管理Kubernetes集群了……

















