













如何解決分布式系統中的“幽靈復現”?
阿里妹導讀:“幽靈復現”的問題本質屬于分布式系統的“第三態”問題,即在網絡系統里面,對于一個請求都有三種返回結果:成功,失敗,超時未知。對于超時未知,服務端對請求命令的處理結果可以是成功或者失敗,但必須是兩者中之一,不能出現前后不一致情況。
1、“幽靈復現”問題
我們知道,當前業界有很多分布式一致性復制協議,比如Paxos,Raft,Zab及Paxos的變種協議,被廣泛用于實現高可用的數據一致性。Paxos組通常有3或5個互為冗余的節點組成,它允許在少數派節點發生停機故障的情況下,依然能繼續提供服務,并且保證數據一致性。作為一種優化,協議一般會在節點之間選舉出一個Leader專門負責發起Proposal,Leader的存在,避免了常態下并行提議的干擾,這對于提高Proposal處理的效率有很大提升。
但是考慮在一些極端異常,比如網絡隔離,機器故障等情況下,Leader可能會經過多次切換和數據恢復,使用Paxos協議處理日志的備份與恢復時,可以保證確認形成多數派的日志不丟失,但是無法避免一種被稱為“幽靈復現”的現象。考慮下面一種情況:

如上表所示,在第一輪中,A成為指定Leader,發出1-10的日志,不過后面的6-10沒有形成多數派,隨機宕機。隨后,第二輪中,B成為指定Leader,繼續發出6-20的日志(B沒有看到有6-10日志的存在),這次,6以及20兩條日志形成了多數派。隨機再次發生切換,A回來了,從多數派拿到的最大LogId為20,因此決定補空洞,事實上,這次很大可能性是要從6開始,一直驗證到20。我們逐個看下會發生什么:
- 針對Index 6的日志,A重新走一輪basic paxos就會發現更大proposeid形成決議的6,從而放棄本地的日志6,接受已經多數派認可的日志;
- 針對Index 7到Index 10,因為多數派沒有形成有效落盤,因此A隨機以本地日志發起提議并形成多數派;
- 針對Index 11到Index 19,因為均沒有形成有效落盤數據,因此,以noop形成補空洞;
- 針對Index 20,這個最簡單,接受已經多數派認可的日志;
在上面的四類情況分析中,1,3,4的問題不大。主要在場景2,相當于在第二輪并不存在的7~10,然后在第三列又重新出現了。按照Oceanbase的說法,在數據庫日志同步場景的情況,這個問題是不可接受的,一個簡單的例子就是轉賬場景,用戶轉賬時如果返回結果超時,那么往往會查詢一下轉賬是否成功,來決定是否重試一下。如果第一次查詢轉賬結果時,發現未生效而重試,而轉賬事務日志作為幽靈復現日志重新出現的話,就造成了用戶重復轉賬。
2、基于 Multi-Paxos 解決“幽靈復現”問題
為了處理“幽靈復現”問題,基于Multi-Paxos實現的一致性系統,可以在每條日志內容保存一個epochID,指定Proposer在生成這條日志時以當前的ProposalID作為epochID。按logID順序回放日志時,因為leader在開始服務之前一定會寫一條StartWorking日志,所以如果出現epochID相對前一條日志變小的情況,說明這是一條“幽靈復現”日志,要忽略掉這條日志(說明一下,我認這里順序是先補空洞,然后寫StartWorkingID,然后提供服務)。
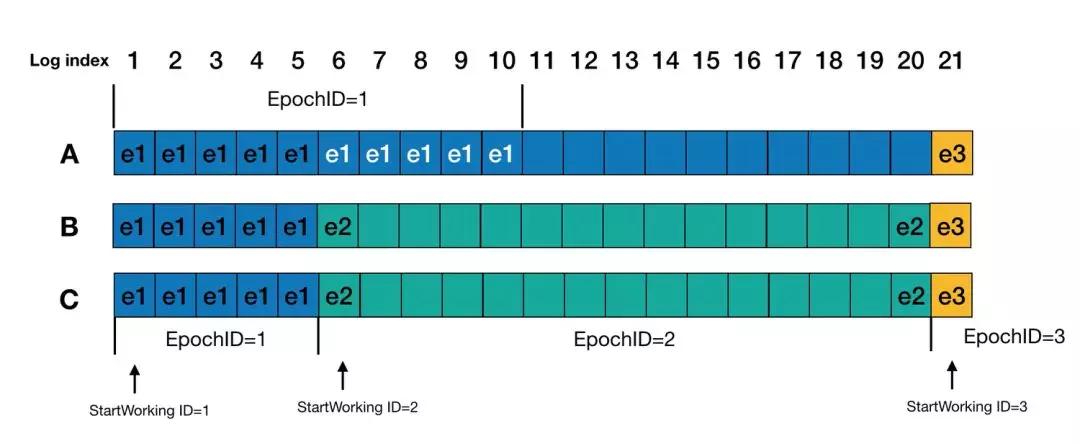
以上個例子來說明,在Round 3,A作為leader啟動時,需要日志回放重確認,index 1~5 的日志不用說的,epochID為1,然后進入epochID為2階段,index 6 會確認為epochID為2的StartWorking日志,然后就是index 7~10,因為這個是epochID為1的日志,比上一條日志epochID小,會被忽略掉。而Index 11~19的日志,EpochID應該是要沿襲自己作為Leader看到的上上一輪StartWorkingID(當然,ProposeID還是要維持在3的),或者因為是noop日志,可以特殊化處理,即這部分日志不參與epochID的大小比較。然后index 20日志也會被重新確認。最后,在index 21寫入StartWorking日志,并且被大多數確認后,A作為leader開始接收請求。
3、基于Raft解決“幽靈復現”問題
3.1 關于Raft日志恢復
首先,我們聊一下Raft的日志恢復,在 Raft 中,每次選舉出來的Leader一定包含已經Committed的數據(抽屜原理,選舉出來的Leader是多數中數據最新的,一定包含已經在多數節點上Commit的數據),新的Leader將會覆蓋其他節點上不一致的數據。雖然新選舉出來的Leader一定包括上一個Term的Leader已經Committed的Log Entry,但是可能也包含上一個Term的Leader未Committed的Log Entry。這部分Log Entry需要轉變為Committed,相對比較麻煩,需要考慮Leader多次切換且未完成Log Recovery,需要保證最終提案是一致的,確定的,不然就會產生所謂的幽靈復現問題。
因此,Raft中增加了一個約束:對于之前Term的未Committed數據,修復到多數節點,且在新的Term下至少有一條新的Log Entry被復制或修復到多數節點之后,才能認為之前未Committed的Log Entry轉為Committed。
為了將上一個Term未Committed的Log Entry轉為Committed,Raft 的解決方案如下:
Raft算法要求Leader當選后立即追加一條Noop的特殊內部日志,并立即同步到其它節點,實現前面未Committed日志全部隱式提交。
從而保證了兩個事情:
- 通過最大Commit原則保證不會丟數據,即是保證所有的已經Committed的Log Entry不會丟;
- 保證不會讀到未Committed的數據,因為只有Noop被大多數節點同意并提交了之后(這樣可以連帶往期日志一起同步),服務才會對外正常工作;Noop日志本身也是一個分界線,Noop之前的Log Entry被提交,之后的Log Entry將會被丟棄。
3.2 Raft解決“幽靈復現”問題
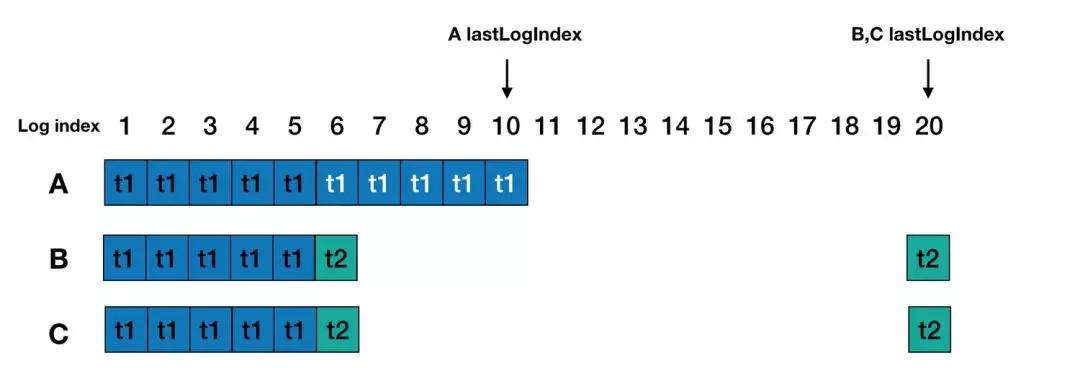
針對第一小節的場景,Raft中是不會出現第三輪A當選leader的情況,首先對于選舉,候選人對比的是最后一條日志的任期號(lastLogTerm)和日志的長度(lastLogIndex)。B、C的lastLogTerm(t2)和lastLogIndex(20)都比A的lastLogTerm(t1)和lastLogIndex(10)大,因此leader只能出現在B、C之內。假設C成為leader后,Leader運行過程中會進行副本的修復,對于A來說,就是從log index為6的位置開始,C將會把自己的index為6及以后的log entry復制給A,因此A原來的index 6-10的日志刪除,并保持與C一致。最后C會向follower發送noop的log entry,如果被大多數都接收提交后,才開始正常工作,因此不會出現index 7-10能讀到值的情況。
這里考慮另一個更通用的幽靈復現場景。考慮存在以下日志場景:
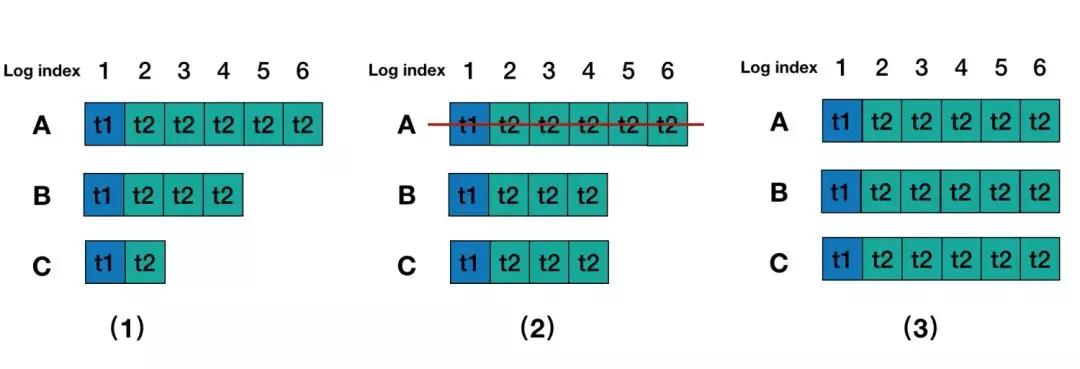
1)Round 1,A節點為leader,Log entry 5,6內容還沒有commit,A節點發生宕機。這個時候client 是查詢不到 Log entry 5,6里面的內容。
2)Round 2,B成為Leader, B中Log entry 3, 4內容復制到C中, 并且在B為主的期間內沒有寫入任何內容。
3)Round 3,A 恢復并且B、C發生重啟,A又重新選為leader, 那么Log entry 5, 6內容又被復制到B和C中,這個時候client再查詢就查詢到Log entry 5, 6 里面的內容了。
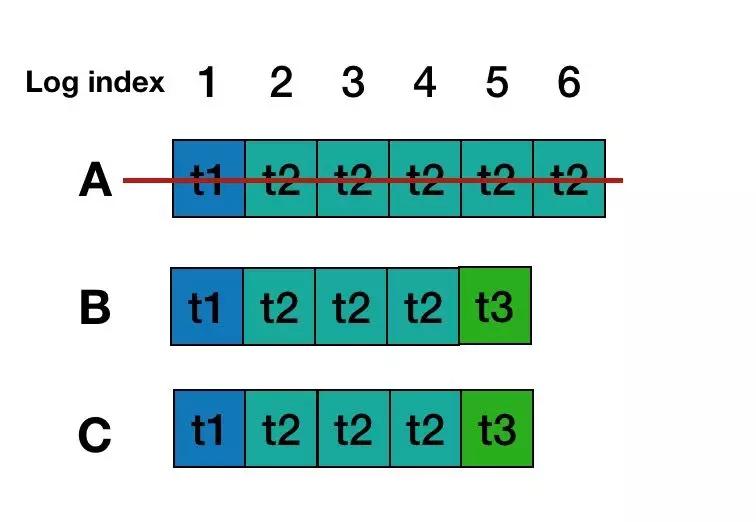
Raft里面加入了新Leader 必須寫入一條當前Term的Log Entry 就可以解決這個問題, 其實和MultiPaxos提到的寫入一個StartWorking 日志是一樣的做法, 當B成為Leader后,會寫入一個Term 3的noop日志,這里解決了上面所說的兩個問題:
- Term 3的noop日志commit前,B的index 3,4的日志內容一定會先復制到C中,實現了最大commit原則,保證不會丟數據,已經 commit 的 log entry 不會丟。
- 就算A節點恢復過來, 由于A的lastLogTerm比B和C都小,也無法成了Leader, 那么A中未完成的commit只是會被drop,所以后續的讀也就不會讀到Log Entry 5,6里面的內容。
4、基于Zab解決“幽靈復現”問題
4.1 關于Zab的日志恢復
Zab在工作時分為原子廣播和崩潰恢復兩個階段,原子廣播工作過程也可以類比raft提交一次事務的過程。
崩潰恢復又可以細分為Leader選舉和數據同步兩個階段。
早期的Zab協議選舉出來的Leader滿足下面的條件:
a) 新選舉的Leader節點含有本輪次所有競選者最大的zxid,也可以簡單認為Leader擁有最新數據。該保證最大程度確保Leader具有最新數據。
b) 競選Leader過程中進行比較的zxid,是基于每個競選者已經commited的數據生成。
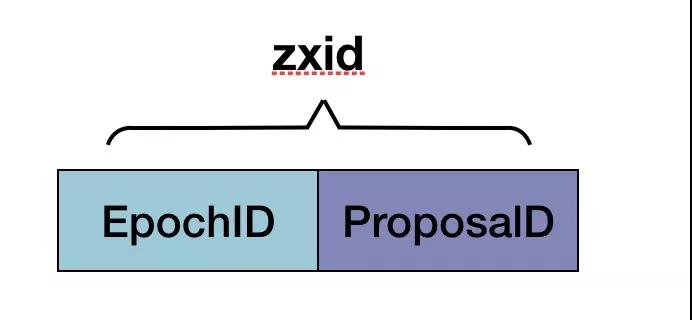
zxid是64位高32位是epoch編號,每經過一次Leader選舉產生一個新的leader,新的leader會將epoch號+1,低32位是消息計數器,每接收到一條消息這個值+1,新leader選舉后這個值重置為0。這樣設計的好處在于老的leader掛了以后重啟,它不會被選舉為leader,因此此時它的zxid肯定小于當前新的leader。當老的leader作為follower接入新的leader后,新的leader會讓它將所有的擁有舊的epoch號的未被commit的proposal清除。
選舉出leader后,進入日志恢復階段,會根據每個Follower節點發送過來各自的zxid,決定給每個Follower發送哪些數據,讓Follower去追平數據,從而滿足最大commit原則,保證已commit的數據都會復制給Follower,每個Follower追平數據后均會給Leader進行ACK,當Leader收到過半Follower的ACK后,此時Leader開始工作,整個zab協議也就可以進入原子廣播階段。
4.2 Zab解決“幽靈復現”問題
對于第 1 節的場景,根據ZAB的選舉階段的機制保證,每次選舉后epoch均會+1,并作為下一輪次zxid的最高32位。所以,假設Round 1階段,A,B,C的EpochId是1,那么接下來的在Round 2階段,EpochId為2,所有基于這個Epoch產生的zxid一定大于A上所有的zxid。于是,在Round 3,由于B, C的zxid均大于A,所以A是不會被選為Leader的。A作為Follower加入后,其上的數據會被新Leader上的數據覆蓋掉。可見,對于情況一,zab是可以避免的。
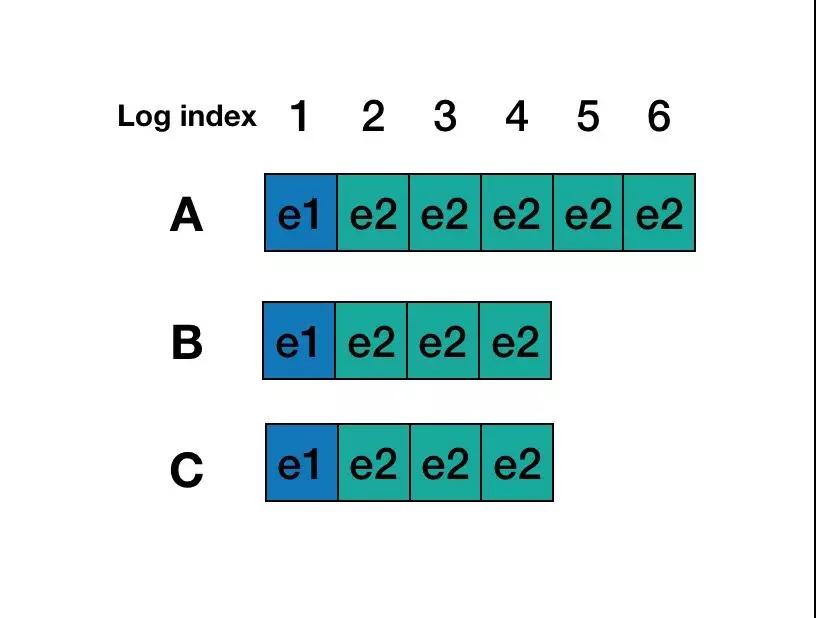
對于 3.2 節的場景,在Round 2,B選為leader后,并未產生任何事務。在Round 3選舉,由于A,B,C的最新日志沒變,所以A的最后一條日志zxid比B和C的大,因此A會選為leader,A將數據復制給B,C后,就會出現”幽靈復現“現象的。
為了解決“幽靈復現”問題,最新Zab協議中,每次leader選舉完成后,都會保存一個本地文件,用來記錄當前EpochId(記為CurrentEpoch),在選舉時,會先讀取CurrentEpoch并加入到選票中,發送給其他候選人,候選人如果發現CurrentEpoch比自己的小,就會忽略此選票,如果發現CurrentEpoch比自己的大,就會選擇此選票,如果相等則比較zxid。因此,對于此問題,Round 1中,A,B,C的CurrentEpoch為2;Round 2,A的CurrentEpoch為2,B,C的CurrentEpoch為3;Round 3,由于B,C的CurrentEpoch比A的大,所以A無法成為leader。
5、 進一步探討
在阿里云的女媧一致性系統里面,做法也是類似于Raft與Zab,確保能夠制造幽靈復現的角色無法在新的一輪選舉為leader,從而避免幽靈日志再次出現。從服務端來看“幽靈復現”問題,就是在failover情況下,新的leader不清楚當前的committed index,也就是分不清log entry是committed狀態還是未committed狀態,所以需要通過一定的日志恢復手段,保證已經提交的日志不會被丟掉(最大 commit 原則),并且通過一個分界線(如MultiPaxos的StartWorking,Raft的noop,Zab的CurrentEpoch)來決定日志將會被commit還是被drop,從而避免模糊不一的狀態。“幽靈復現”的問題本質屬于分布式系統的“第三態”問題,即在網絡系統里面, 對于一個請求都有三種返回結果:成功,失敗,超時未知。對于超時未知,服務端對請求命令的處理結果可以是成功或者失敗,但必須是兩者中之一,不能出現前后不一致情況。在客戶端中,請求收到超時,那么客戶端是不知道當前底層是處于什么狀況的,成功或失敗都不清楚,所以一般客戶端的做法是重試,那么底層apply的業務邏輯需要保證冪等性,不然重試會導致數據不一致。























