如何解決分布式系統的Logical Time問題?(一)
前言
在一個分布式系統中存在著各種各樣的并發事件,對于某些存在內在因果關系的事件需要知道事件的先后順序,并且能夠按照正確的順序處理這些事件,區分事件的先后順序在單機系統中可以靠本地時鐘來做到,但在分布式系統中如何做到呢,這就是分布式系統中的logical time問題。
本文為大家介紹logical time算法的鼻祖Lamport Clock。
為了形象地描述logical time問題,我們舉個簡單的例子,假設客戶A下單購買了一本書,這時系統向訂單系統提交a請求(客戶買書的訂單),然后購買該書還有個優惠活動,能夠獲得一本贈書,這時系統需要向優惠活動管理系統發送b請求(客戶要求贈書x),優惠活動管理系統檢查準許客戶的贈書請求,于是將b請求轉發給訂單系統,在該例子中顯然訂單系統應該先收到買書的訂單,然后是贈書的訂單,但是由于網絡延時的原因,可能存在贈書請求先于買書請求到達訂單系統的情況,那么這種情況需要如何處理?
我們用簡單的圖來描述上面的過程,圖中P0代表訂單系統,P1代表客戶,P2代表優惠活動管理系統,a請求就是買書請求,b請求就是贈書請求。

為了解決該問題比較容易想到的做法就是同步通信,發送a請求后等待P0處理完成并回復后再開始發送b請求,該方法簡單易實現但是并不能發揮分布式系統的并發性能,效率低下,也不能簡單地用給時間a和b打上本地時間戳的方式來處理,因為分布式系統中本地時鐘是無法做到完全同步的,所以需要一種適用于分布式系統的能將事件的先后順序信息也被稱為“ happened before”信息識別出來的算法,本文主要介紹logical time算法的鼻祖Lamport clock。
Lamport clock算法
Lamport clock算法的思想很簡單,主要有以下兩個規則:
- 每個process在成功完成一個事件后都增加自己的時間戳,通常是加1;
- 如果process Pi通過消息m發送了事件a,那么該消息m中包含了當前pi的時間戳Ci(a);process Pj收到消息m后,取消息m中帶的時間戳和Pj當前的時間戳Cj中的較大值然后加1;
例如一個較為復雜的例子,已經用Lamport clock算法為每個事件加了時間戳,如下圖:
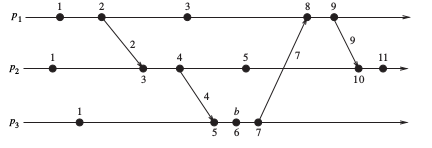
通過該例子可以發現存在一些并沒有明確的先后關系的并發事件,比如p1上的時間戳為3的事件和p2上的時間戳為4的事件,這些事件可以是任意先后或者同時發生,但在Lamport clock算法中這些事件卻有了明確的時間戳,該時間戳的大小并不代表事件的先后順序。
重要屬性
用簡單的公式來描述logical time算法的Clock Condition,C表示時間戳,ei 和 ej表示兩個事件,假設ei先于ej發生,并用->表示該“happened before”關系,那么存在以下兩個Clock Condition:
1) ei -> ej => C(ei) < C(ej)
表示如果ei先于ej發生,那么ei的時間戳C(ei)必定小于C(ej)。
2) ei -> ej <=> C(ei) < C(ej)
表示如果ei先于ej發生,那么ei的時間戳C(ei)必定小于C(ej),如果C(ei)小于C(ej),那么ei必定先于ej發生。
根據算法是否滿足以上Clock Condition來區分其所具備的屬性,如果一個算法滿足Clock Conditon 2,那么該算法具備strongly consistent屬性,本篇文章介紹的Lamport clock算法只滿足Clock Condition 1,所以不具備strongly consistent屬性,但后續介紹的vector clock算法具備strongly consitent屬性。
strongly consistent屬性的意義在于是否可以通過C時間戳來判斷出事件ei與ej的順序關系,具備該屬性的算法,當時間戳C(ei) > C(ej)時,可以確定ei先于ej發生,否則可以認為ei與ej是沖突的(這里的沖突表示ei與ej可以是任意的先后關系),所以可以用來檢測事件的沖突。
案例分析
使用Lamport clock對之前的例子做排序,如下圖:
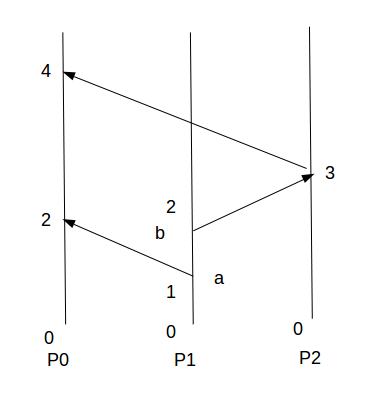
P1發送a消息和b消息,因為P1的初始時間戳為0,所以按照Lamport clock算法事件a和b的發送時間戳為1和2。
P0收到P1的消息a,取兩者時間戳的較大值max(0,1)并+1得到時間戳為2。
P2收到b消息后,取兩者時間戳的較大值max(0,2)并+1得到時間戳為3。
P0收到P2轉發的事件b后,取兩者時間戳的較大值max(2,3)并+1得到時間戳為4。
所以在P0端可以得到事件a是先于事件b的。
但在實際的應用中由于存在網絡延時,會出現以下情況:
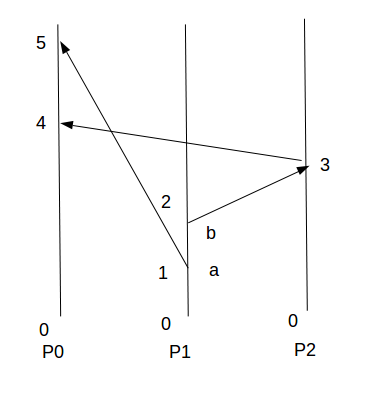
因為網絡延時導致P0先收到P2轉發的b事件,再收到P1的a事件,然后根據Lamport clock算法計算出來的時間戳也變成了b事件先于a事件了,這顯然是錯誤的,那么要如何避免出現這個情況,為了關注解決該問題的實際算法,假定系統已經滿足以下條件:
- 消息的接受順序與發送順序一致;
- 所有的消息最終都會被收到;
每個process都有自己的請求隊列,并且對其他process不可見,請求隊列中的初始時間戳為0,算法由以下5條規則組成:
1) 請求資源時,process Pi發送消息Tm,給其他所有process,并且將消息Tm置于它的請求隊列中
2) prcocess Pj收到Pi的資源請求消息Tm后,將該消息置于自己的請求隊列中并發送一個帶有時間戳的回復給Pi
3) 釋放資源時,Pi將消息Tm從請求隊列中移除,并發送資源釋放消息給所有其他process
4) process Pj收到Pi的資源釋放消息后將之前的資源請求消息Tm從請求隊列中移除
5) 當滿足以下2個條件時認為Pi獲取了資源
- Pi的請求隊列中有請求消息Tm,并且按照順序排列好的,這里以消息的發送順序為準;
- Pi收到了任意一個時間戳比Tm要大的消息;
把這個算法帶入到上面的例子中,相當于P1發起了兩個事件a和b來請求資源,a比b要先發生,那么也期望a比b要先被P0處理(這里處理可以理解為獲取了P0的資源),那么當出現上述例子中的情況,事件b先被P0收到,按照算法,P0發送Tm給所有其他process,然后等待回復,當收到P1的回復時a事件也必然被收到了(按照系統假定滿足的條件1)消息的接受順序與發送順序一致),這時按照規則5的(i)條件,會根據事件a和b的發送端的時間戳比較,重新排序為a事件先于b事件,這樣就解決了因為網絡延時導致的消息亂序問題。
總結
Lamport clock雖然作為分布式系統中解決logical time問題的鼻祖,為后續其他算法提供了思路,但其不具備strongly consistent,無法滿足分布式數據庫場景中寫沖突的檢測,所以實際場景中更多是使用后來的vector clock,后面我們將會給大家介紹vector clock。
【本文是51CTO專欄機構作者“大U的技術課堂”的原創文章,轉載請通過微信公眾號(ucloud2012)聯系作者】