擔心自己照片被Deepfake利用?試試波士頓大學這項新研究
換臉視頻是濫用 DL 的一大后果,只要網上有你的照片,那么就有可能被換臉到其它背景或視頻。然而,有了這樣的開源攻擊模型,上傳的照片不再成為問題,deepfake 無法直接拿它做換臉。

看上去效果很好,只需要加一些人眼看不到的噪聲,換臉模型就再也生成不了正確人臉了。這樣的思路不正是對抗攻擊么,之前的攻擊模型會通過「偽造真實圖像」來欺騙識別模型。而現在,攻擊模型生成的噪聲會武裝人臉圖像,從而欺騙 deepfake,令 deepfake 生成不了欺騙人類的換臉模型。
這篇波士頓大學的研究放出來沒多久,就受到很多研究者的熱議,在 Reddit 上也有非常多的討論。看到這篇論文,再加上研究者有放出 GitHub 項目,很可能我們會想到「是不是能在線發(fā)布我們的照片,然后 deepfake 之后就用不了了?」
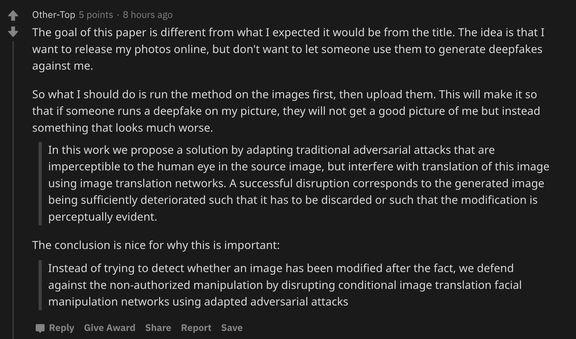
但事情肯定沒我們想的那么簡單,Reddit 用戶 Other-Top 說:「按照這篇論文,我需要先利用該方法對照片進行處理,然后再上傳照片,別人再用這張做換臉就會出錯。」
也就是說,我們的照片、明星的照片先要用攻擊模型過一遍,然后才能上傳到網絡上,這樣的照片才是安全的?
聽起來就比較麻煩,但我們還是可以先看看這篇論文的研究內容,說不定能想出更好的辦法。在這篇論文中,研究者利用源圖像中人眼無法感知的對抗攻擊,借助對抗噪聲干擾圖像的生成結果。
這一破壞的結果是:所生成的圖像將被充分劣化,要么使得該圖像無法使用,要么使得該圖像的變化明顯可見。換而言之,不可見的噪聲,令 deepfake 生成明顯是假的視頻。
論文地址:https://arxiv.org/abs/2003.01279
代碼地址:https://github.com/natanielruiz/disrupting-deepfakes
對抗攻擊,Deepfake 的克星
對抗攻擊,常見于欺騙各種圖像識別模型,雖然也能用于圖像生成模型,但似乎意義不是那么大。不過如果能用在 deepfake 這類換臉模型,那就非常有前景了。
在這篇論文中,研究者正是沿著對抗攻擊這條路「欺騙」deepfake 的換臉操作。具體而言,研究者首先提出并成功應用了:
可以泛化至不同類別的可遷移對抗攻擊,這意味著攻擊者不需要了解圖像的類別;
用于生成對抗網絡(GAN)的對抗性訓練,這是實現魯棒性圖像轉換網絡的第一步;
在灰盒(gray-box)場景下,使輸入圖像變模糊可以成功地防御攻擊,研究者展示了一個能夠規(guī)避這種防御的攻擊方法。
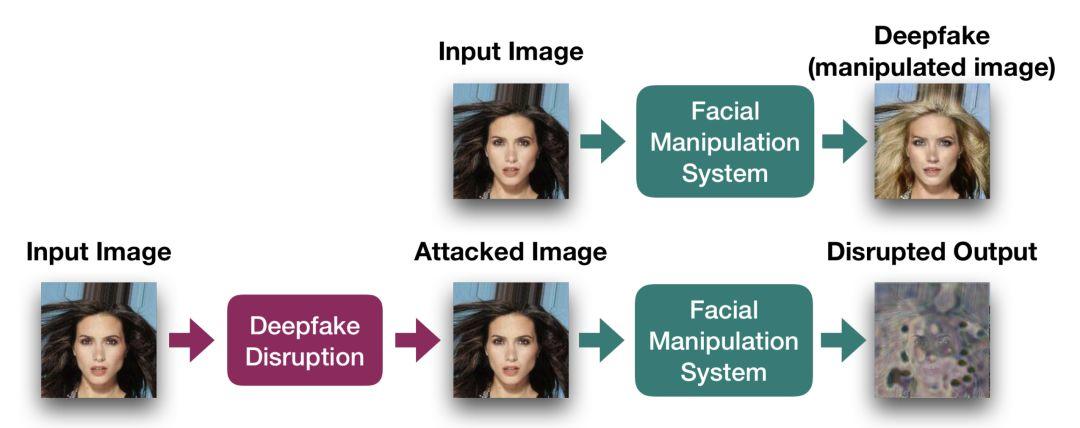
圖 1:干擾 deepfake 生成的流程圖。使用 I-FGSM 方法,在圖像上應用一組無法覺察的噪聲,之后就能成功地干擾人臉操縱系統(tǒng)(StarGAN)的輸出結果。
大多數人臉操縱架構都是用輸入圖像和目標條件類別訓練的,例如使用某些屬性來定義生成人臉的目標表情(如給人臉添加微笑)。如果我們想要阻止他人為圖像中的人臉添加微笑,則需要清楚選擇的是微笑屬性,而不是閉眼等其他不相關屬性。
所以要靠對抗攻擊欺騙 deepfake,首先需要梳理帶條件的圖像轉換問題,這樣才能將之前的攻擊方法遷移到換臉上。研究者并提出了兩種可遷移的干擾變體類別,從而提升對不同類別屬性的泛化性。
在白盒測試場景下,給照片加模糊是一種決定性的防御方式,其中干擾者清楚預處理的模糊類型和大小。此外,在真實場景下,干擾者也許知道所使用的架構,但卻忽略了模糊的類型和大小,此場景下的一般攻擊方法的效果會顯著降低。所以,研究者提出了一種新型 spread-spectrum disruption 方法,它能夠規(guī)避灰盒測試場景下不同的模糊防御。
總的而言,盡管 deepfake 圖像生成有很多獨特的地方,但是經受過「傳統(tǒng)圖像識別」的對抗攻擊,經過修改后就能高效地欺騙 deepfake 模型。
如何攻擊 Deepfake
如果讀者之前了解過對抗攻擊,,那么這篇論文后面描述的方法將更容易理解。總的來說,對于如何攻擊 deepfake 這類模型,研究者表示可以分為一般的圖像轉換修改(image translation disruption),他們新提出的條件圖像修改、用于 GAN 的對抗訓練技術和 spread spectrum disruption。
我們可以先看看攻擊的效果,本來沒修改的圖像(沒加對抗噪聲)是可以完成換臉的。但是如果給它們加上對抗噪聲,盡管人眼看不出輸入圖像有什么改變,不過模型已經無法根據這樣的照片完成換臉了。

與對抗攻擊相同,如果我們給圖像加上一些人眼無法識別,但機器又非常敏感的噪聲,那么依靠這樣的圖像,deepfakes 就會被攻擊到。
目前比較流行的攻擊方法主要是基于梯度和迭代的方法,其它很多優(yōu)秀與先進的攻擊方法都基于它們的主要思想。這一類方法的主要思想即希望找到能最大化損失函數變化的微小擾動,這樣通過給原始輸入加上這一微小擾動,模型就會誤分類為其它類別。
通常簡單的做法是沿反向傳播計算損失函數對輸入的導數,并根據該導數最大化損失函數,這樣攻擊者就能找到最優(yōu)的擾動方向,并構造對抗樣本欺騙該深度網絡。
例如早年提出的 Fast Gradient Sign Method(FGSM),如果我們令 x 表示輸入圖像、G 為完成換臉的生成模型、L 為訓練神經網絡的損失函數,那么我們可以在當前權重值的鄰域線性逼近損失函數,并獲得令生成圖像 G(x) 與原本換臉效果「r」差別最遠的噪聲η。
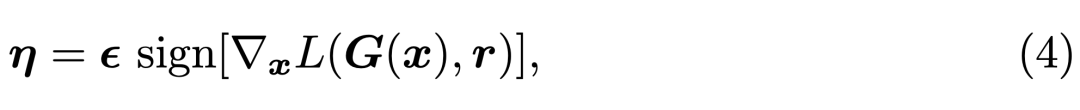
FGSM 能通過反向傳播快速計算梯度,并找到令模型損失增加最多的微小擾動 η。其它如基本迭代方法(BIM)會使用較小的步長迭代多次 FGSM,從而獲得效果更好的對抗樣本。如下圖所示將最優(yōu)的擾動 η 加入原輸入 x「人臉」,再用該「人臉」生成 deepfakes 就會存在問題。
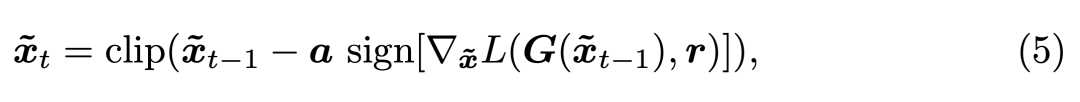
還有三種攻擊法
上面只介紹了對抗攻擊最為核心的思想,它在一定程度上確實能夠欺騙 deepfakes,但是要想有好的效果,研究者在論文中提出了三種更完善的攻擊方法。這里只簡要介紹條件圖像修改的思想,更多的細節(jié)可查閱原論文。
之前添加噪聲是不帶條件的,但很多換臉模型不僅會輸入人臉,同時還會輸入某個類別,這個類別就是條件。如下我們將條件 c 加入到了圖像生成 G(x, c) 中,并希望獲得令損失 L 最大,但又只需修改最小像素 η的情況。
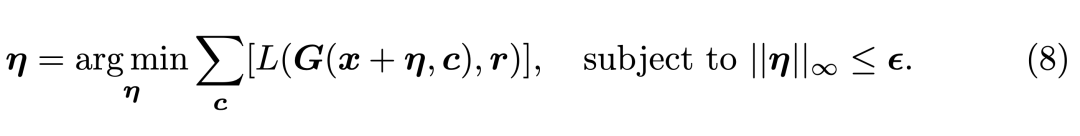
為了解決這一問題,研究者展示了一種新的攻擊方法,它針對條件約束下的圖像轉換方法。這種方法能加強攻擊模型遷移到各種類別的能力,例如類別是「笑臉」,那么將它輸入攻擊模型能更好地生成令 deepfakes 失效的人臉。
具體而言,研究者將 I-FGSM 修改為如下:
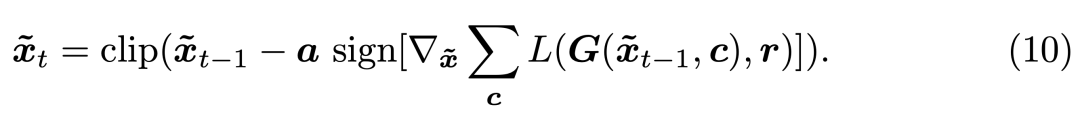
實驗效果
實驗表明,研究者提出的圖像級 FGSM、 I-FGSM 和基于 PGD 的圖像加噪方法能夠成功地干擾 GANimation、StarGAN、pix2pixHD 和 CycleGAN 等不同的圖像生成架構。
為了了解基于 L^2、L^1 度量圖像「修改量」對圖像轉換效果的影響,在下圖 3 中,研究者展示了干擾輸出的定性示例以及它們各自的失真度量。

圖 3:L_2 和 L_1 距離之間的等值規(guī)模(equivalence scale)以及 StarGAN 干擾圖像上的定性失真。
對于文中提出的迭代類別可遷移干擾和聯(lián)合類別可遷移干擾,研究者給出了下圖 4 中的定性示例。這些干擾的目的是遷移至 GANimation 的所有動作單元輸入。

圖 4:研究者提出這種攻擊換臉模型的效果。
如上圖所示,a 為原始輸入圖像,它在不加入噪聲下的 GANimation 生成結果為 b。如果以類別作為約束,使用正確類別后的攻擊效果為 c,而沒有使用正確類別的攻擊效果為 d。后面 e 與 f 分別是研究者提出的迭代類別可遷移攻擊效果、聯(lián)合類別可遷移攻擊效果,它們都可以跨各種類別攻擊到 deepfakes 生成模型。
在灰盒測試的設置中,干擾者不知道用于預處理的模糊類型和大小,因此模糊是一種有效抵御對抗性破壞的方式。低幅度的模糊可以使得破壞失效,但同時可以保證圖像轉換輸出的質量。下圖 5 展示了在 StarGAN 結構中的示例。

圖 5:高斯模糊防御的成功示例。
如果圖像控制器使用模糊來阻擋對抗性干擾,對方可能不知道所使用模糊的類型和大小。下圖 6 展示了該擴頻方法在測試圖像中成功實現干擾的比例。
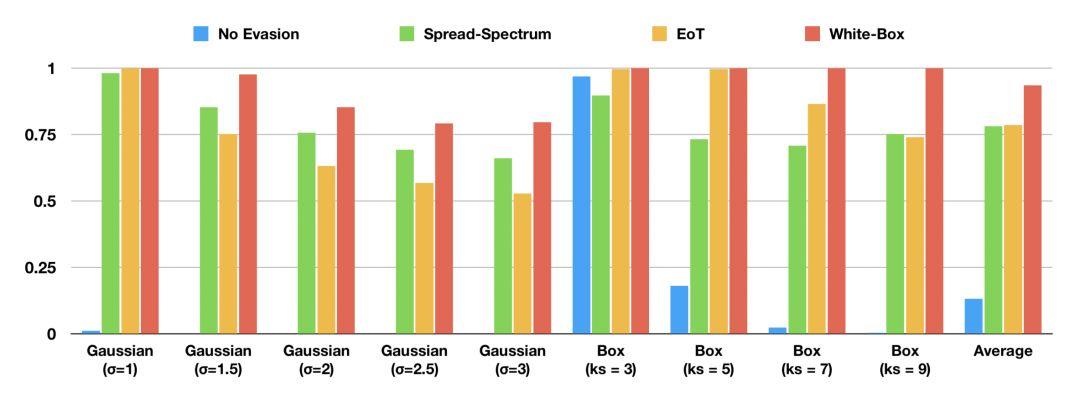
圖 6:不同模糊防御下的不同模糊規(guī)避所造成的圖像干擾比例 (L^2 ≥ 0.05)。

圖 7:對于采用高斯模糊(σ = 1.5)的防御手段,spread-spectrum disruption 方法的效果。第一行展示了最初不針對模糊處理進行攻擊的方法;第二行為 spread-spectrum disruption 方法方法,最后一行是 white-box 測試條件下的攻擊效果。