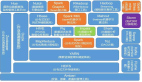
企業大數據平臺倉庫架構建設思路
總體思路
![企業大數據平臺倉庫架構建設思路[轉]](https://s4.51cto.com/oss/202003/21/7317e4a5cd0bdc0948a5d5f3cb32b336.jpeg)
隨著互聯網規模不斷的擴大,數據也在爆炸式地增長,各種結構化、半結構化、非結構化數據不斷地產生。新環境下的數據應用呈現業務變化快、數據來源多、系統耦合多、應用深度深等特征。那么基于這些特征,該如何構建數據倉庫呢?我認為應該從穩定、可信、豐富、透明四個關鍵詞入手。其中,穩定要求數據的產出穩定、有保障;可信意味著數據的質量要足夠高;豐富是指數據涵蓋的業務面要足夠豐富;透明要求數據構成流程體系是透明,讓用戶放心使用。
![企業大數據平臺倉庫架構建設思路[轉]](https://s4.51cto.com/oss/202003/21/bf41bd00d0658ae707420fec7baa9a04.jpeg)
我們之所以選擇基于大數據平臺構建數據倉庫,是由大數據平臺豐富的特征決定的:
- 強大的計算和存儲能力,使得更扁平化的數據流程設計成為可能,簡化計算過程;
- 多樣的編程接口和框架,豐富了數據加工的手段;
- 豐富的數據采集通道,能夠實現非結構化數據和半結構化數據的采集;
- 各種安全和管理措施,保障了平臺的可用性。
![企業大數據平臺倉庫架構建設思路[轉]](https://s2.51cto.com/oss/202003/21/e5d6b611629439baed821f679a268184.jpeg)
倉庫架構設計原則包括四點:第一自下而上結合自上而下的方式,保障數據搜集的全面性;第二高容錯性,隨著系統耦合度的增加,任何一個系統出現問題都會對數倉服務產生影響,因此在數倉構建時,高容錯性是必不可少的因素;第三數據質量監控需要貫穿整個數據流程,毫不夸張地說,數據質量監控消耗的資源可以等同于數據倉庫構建的資源;第四無需擔心數據冗余,充分利用存儲換易用。
模型設計
構建數倉的首要步驟就是進行模型設計。
維度莫建模或實體關系建模
![企業大數據平臺倉庫架構建設思路[轉]](https://s3.51cto.com/oss/202003/21/81c9ab5fd422c1ec4652a9d47c381803.jpeg)
常見的模型設計思路包括維度建模和實體關系建模。維度建模實施簡單,便于實時數據分析,適用于業務分析報表和BI;實體關系建模結構較復雜,但它便于主體數據打通,適合復雜數據內容的深度挖掘。
每個企業在構建自己數倉時,應該根據業務形態和需求場景選擇合適的建模方式。對于應用復雜性企業,可以采用多種建模結合的方式,例如在基礎層采用維度建模的方式,讓維度更加清晰;中間層采用實體關系建模方式,使得中間層更容易被上層應用使用。
星型模型和雪花模型
![企業大數據平臺倉庫架構建設思路[轉]](https://s5.51cto.com/oss/202003/21/17f98bc6eb52e30da7ddc44e555620c7.jpeg)
除了建模方式之外,在星型模型和雪花模型的選擇上也有可能讓使用者左右為難。事實上,兩種模型是并存的,星型是雪花模型的一種。理論上真實數據的模型都是雪花模型;實際數據倉庫中兩種模型是并存的。
由于星型模型相對結構簡單,我們可以在數據中間層利用數據冗余將雪花模型轉換成星型模型,從而有利于數據應用和減少計算資源消耗。
數據分層
![企業大數據平臺倉庫架構建設思路[轉]](https://s4.51cto.com/oss/202003/21/f270f3e333b366e70e7618eb71c61527.jpeg)
在確定建模思路和模型類型之后,下一步的工作是數據分層。數據分層可以使得數據構建體系更加清晰,便于數據使用者快速對數據進行定位;同時數據分層也可以簡化數據加工處理流程,降低計算復雜度。
我們常用的數據倉庫的數據分層通常分為集市層、中間層、基礎數據層上下三層結構。由傳統的多層結構減少到上下三層結構的目的是為了壓縮整體數據處理流程的長度,同時扁平化的數據處理流程有助于數據質量控制和數據運維。
在上下三層的結構的右側,我們增加了流式數據,將其添加成數據體系的一部分。這是因為當前的數據應用方向會越來越關注數據的時效性,越實時的數據價值度越高。
但是,由于流式數據集的采集、加工和管理的成本較高,一般都會按照需求驅動的方式建設;此外,考慮到成本因素,流式數據體系的結構更加扁平化,通常不會設計中間層。
下面來具體看下每一層的具體作用。
數據基礎層
![企業大數據平臺倉庫架構建設思路[轉]](https://s5.51cto.com/oss/202003/21/9d2971631ff24ef5642812b20398a77a.jpeg)
數據基礎層主要完成的工作包括以下幾點:
- 數據采集:把不同數據源的數據統一采集到一個平臺上;
- 數據清洗,清洗不符合質量要求的數據,避免臟數據參與后續數據計算;
- 數據歸類,建立數據目錄,在基礎層一般按照來源系統和業務域進行分類;
- 數據結構化,對于半結構化和非結構化的數據,進行結構化;
- 數據規范化,包括規范維度標識、統一計量單位等規范化操作。
數據中間層
![企業大數據平臺倉庫架構建設思路[轉]](https://s2.51cto.com/oss/202003/21/b2feb69a3ffa8ce811abe4d85419114a.jpeg)
數據中間層最為重要的目標就是把同一實體不同來源的數據打通起來,這是因為當前業務形態下,同一實體的數據可能分散在不同的系統和來源,且這些數據對同一實體的標識符可能不同。此外,數據中間層還可以從行為中抽象關系。從行為中抽象出來的基礎關系,會是未來上層應用一個很重要的數據依賴。例如抽象出的興趣、偏好、習慣等關系數據是推薦、個性化的基礎生產資料。
在中間層,為了保證主題的完整性或提高數據的易用性,經常會進行適當的數據冗余。比如某一實事數據和兩個主題相關但自身又沒有成為獨立主題,則會放在兩個主題庫中;為了提高單數據表的復用性和減少計算關聯,通常會在事實表中冗余部分維度信息。
數據集市層
![企業大數據平臺倉庫架構建設思路[轉]](https://s2.51cto.com/oss/202003/21/40ddedcff779bf7372b5e2f4dbbdee12.jpeg)
數據集市層是上下三層架構的最上層,通常是由需求場景驅動建設的,并且各集市間垂直構造。在數據集市層,我們可以深度挖掘數據價值。值得注意的是,數據集市層需要能夠快速試錯。
數據架構
![企業大數據平臺倉庫架構建設思路[轉]](https://s5.51cto.com/oss/202003/21/f2680ff5639f4a7ab6f14c79f8abf452.jpeg)
數據架構包括數據整合、數據體系、數據服務三部分。其中,數據整合又可以分為結構化、半結構化、非結構化三類。
數據整合
![企業大數據平臺倉庫架構建設思路[轉]](https://s5.51cto.com/oss/202003/21/7ce53346bcc4506cf8a78dc11c08c651.jpeg)
結構化數據采集又可細分為全量采集、增量采集、實時采集三類。三種采集方式的各自特點和適應場合如上圖所示,其中全量采集的方式最為簡單;實時采集的采集質量最難控制。
![企業大數據平臺倉庫架構建設思路[轉]](https://s1.51cto.com/oss/202003/21/b4d8ee57a61612c502101cc885568c67.jpeg)
在傳統的架構中,日志的結構化處理是放在數倉體系之外的。在大數據平臺倉庫架構中,日志在采集到平臺之前不做結構化處理;在大數據平臺上按行符分割每條日志,整條日志存儲在一個數據表字段;后續,通過UDF或MR計算框架實現日志結構化。
在我們看來,日志結構越規范,解析成本越低。在日志結構化的過程中,并不一定需要完全平鋪數據內容,只需結構化出重要常用字段;同時,為了保障擴展性,我們可以利用數據冗余保存原始符合字段(如useragent字段)。
![企業大數據平臺倉庫架構建設思路[轉]](https://s3.51cto.com/oss/202003/21/48cacc746acffd5da33a61f545666f5a.jpeg)
非結構化的數據需要結構化才能使用。非結構化數據特征提取包括語音轉文本、圖片識別、自然語言處理、圖片達標、視頻識別等方式。盡管目前數倉架構體系中并不包含非結構化數據特征提取操作,但在未來,這將成為可能。
數據服務化
![企業大數據平臺倉庫架構建設思路[轉]](https://s3.51cto.com/oss/202003/21/86c98556cd7476b30426017d126b2482.jpeg)
數據服務化包括統計服務、分析服務和標簽服務:
- 統計服務主要是偏傳統的報表服務,利用大數據平臺將數據加工后的結果放入關系型數據庫中,供前端的報表系統或業務系統查詢;
- 分析服務用來提供明細的事實數據,利用大數據平臺的實時計算能力,允許操作人員自主靈活的進行各種維度的交叉組合查詢。分析服務的能力類似于傳統cube提供的內容,但是在大數據平臺下不需要預先建好cube,更靈活、更節省成本;
- 標簽服務,大數據的應用場景下,經常會對主體進行特征刻畫,比如客戶的消費能力、興趣習慣、物理特征等等,這些數據通過打標簽轉換成KV的數據服務,用于前端應用查詢。
架構設計中一些實用的點
![企業大數據平臺倉庫架構建設思路[轉]](https://s2.51cto.com/oss/202003/21/18d7f923481d6696f74110437dc0196b.jpeg)
在架構設計中有一些實用的點,這里給大家分享一下:
第一,通過巧用虛擬節點實現多系統數據源同步,實現跨系統間的數據傳輸,實現多應用間數據交互。通過巧用虛擬節點減少運維人員在實際出現問題時的運維成本。
第二,采用強制分區,在所有的表都上都加上時間分區。通過分區,保證每個任務都能夠獨立重跑,而不產生數據質量問題,降低了數據修復成本;此外通過分區裁剪,還可以降低計算成本。
![企業大數據平臺倉庫架構建設思路[轉]](https://s1.51cto.com/oss/202003/21/d22b8b2b76f7dcc7b7c30e520087fb75.jpeg)
第三,應用計算框架完成日志結構化、同類數據計算過程等操作,減輕了開發人員的負擔,同時更容易維護。
第四,優化關鍵路徑。優化關鍵路徑中耗時最長的任務是最有效的保障數據產出時間的手段。
數據治理
![企業大數據平臺倉庫架構建設思路[轉]](https://s2.51cto.com/oss/202003/21/aac2d7aae8cb160f9458de106e97c698.jpeg)
數據治理不是獨立于系統之外的保障,它應該貫穿在數倉架構內部和數據處理的流程之中。
數據質量
![企業大數據平臺倉庫架構建設思路[轉]](https://s3.51cto.com/oss/202003/21/a875e92bcb0ad3a4834ac4689a2c9aa2.jpeg)
保障數據質量,可以從事前、事中、事后入手。事前,我們可以通過制定每份數據的數據質量監控規則,越重要的數據對應的監控規則應該越多;事中,通過監控和影響數據生產過程,對不符合質量要求的數據進行干預,使其不影響下流數據的質量;事后,通過對數據質量情況進行分析和打分,將一些不足和改進反饋數據監控體系,推動整體的數據質量提升。
數據生命周期管理
![企業大數據平臺倉庫架構建設思路[轉]](https://s4.51cto.com/oss/202003/21/74a69e4d5024ad81363867dfaf3e968b.jpeg)
出于成本等因素的考慮,在大數據平臺上我們依然需要對數據生命周期進行管理。根據使用頻率將數據分為冰、冷、溫、熱四類。一個合理的數據生命周期管理要保證溫熱數據占整個數據體系大部分;同時為了保障數據資產的完整性,對于重要的基礎數據會長久保留。
對于數據中間計算過程數據,在保障滿足絕大部分應用訪問歷史數據需要的前提下,縮短數據保留周期,有助于降低存儲成本;最后一點值得注意的是,冷備已經成為歷史,在大數據平臺下不需要單獨的冷備設備。