講真,應該選擇RabbitMQ還是Kafka?
作為一個有豐富經驗的微服務系統架構師,經常有人問我,應該選擇 RabbitMQ 還是 Kafka?
圖片來自 Pexels
基于某些原因, 許多開發者會把這兩種技術當做等價的來看待。的確,在一些案例場景下選擇 RabbitMQ 還是 Kafka 沒什么差別,但是這兩種技術在底層實現方面是有許多差異的。
不同的場景需要不同的解決方案,選錯一個方案能夠嚴重的影響你對軟件的設計,開發和維護的能力。
這篇文章會先介紹一下基本的異步消息模式,然后再介紹一下 RabbitMQ 和 Kafka 以及他們的內部結構信息。第二部分(未完成)主要介紹這兩種技術的主要不同點以及他們各自的優缺點,最后我們會說明一下怎樣選擇這兩種技術。
異步消息模式
異步消息可以作為解耦消息的生產和處理的一種解決方案。提到消息系統,我們通常會想到兩種主要的消息模式——消息隊列和發布/訂閱模式。
消息隊列
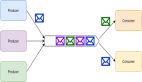
利用消息隊列可以解耦生產者和消費者。多個生產者可以向同一個消息隊列發送消息。
但是,一個消息在被一個消息者處理的時候,這個消息在隊列上會被鎖住或者被移除并且其他消費者無法處理該消息。也就是說一個具體的消息只能由一個消費者消費。
消息隊列
需要額外注意的是,如果消費者處理一個消息失敗了,消息系統一般會把這個消息放回隊列,這樣其他消費者可以繼續處理。
消息隊列除了提供解耦功能之外,它還能夠對生產者和消費者進行獨立的伸縮(scale),以及提供對錯誤處理的容錯能力。
發布/訂閱
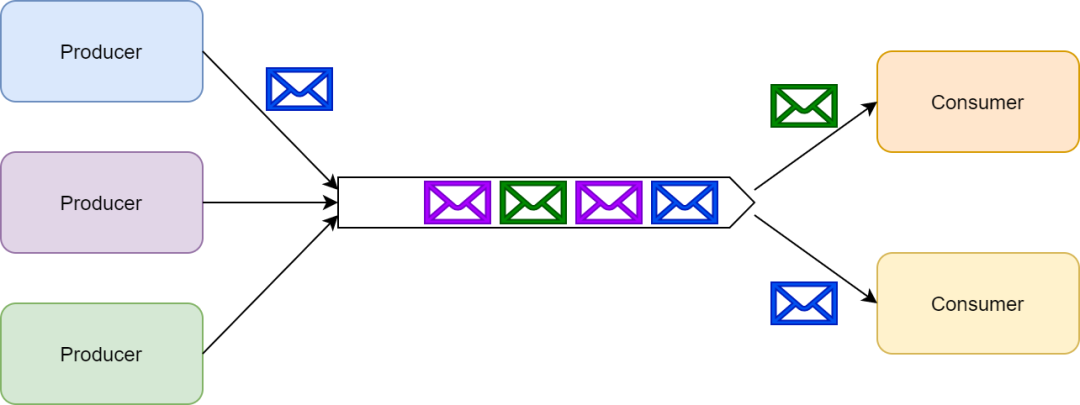
發布/訂閱(pub/sub)模式中,單個消息可以被多個訂閱者并發的獲取和處理。
發布/訂閱
例如,一個系統中產生的事件可以通過這種模式讓發布者通知所有訂閱者。在許多隊列系統中常常用主題(topics)這個術語指代發布/訂閱模式。
在 RabbitMQ 中,主題就是發布/訂閱模式的一種具體實現(更準確點說是交換器(exchange)的一種),但是在這篇文章中,我會把主題和發布/訂閱當做等價來看待。
一般來說,訂閱有兩種類型:
- 臨時(ephemeral)訂閱,這種訂閱只有在消費者啟動并且運行的時候才存在。一旦消費者退出,相應的訂閱以及尚未處理的消息就會丟失。
- 持久(durable)訂閱,這種訂閱會一直存在,除非主動去刪除。消費者退出后,消息系統會繼續維護該訂閱,并且后續消息可以被繼續處理。
RabbitMQ
RabbitMQ 作為消息中間件的一種實現,常常被當作一種服務總線來使用。RabbitMQ 原生就支持上面提到的兩種消息模式。
其他一些流行的消息中間件的實現有 ActiveMQ,ZeroMQ,Azure Service Bus 以及 Amazon Simple Queue Service(SQS)。
這些消息中間件的實現有許多共通的地方;這邊文章中提到的許多概念大部分都適用于這些中間件。
隊列
RabbitMQ 支持典型的開箱即用的消息隊列。開發者可以定義一個命名隊列,然后發布者可以向這個命名隊列中發送消息。最后消費者可以通過這個命名隊列獲取待處理的消息。
消息交換器
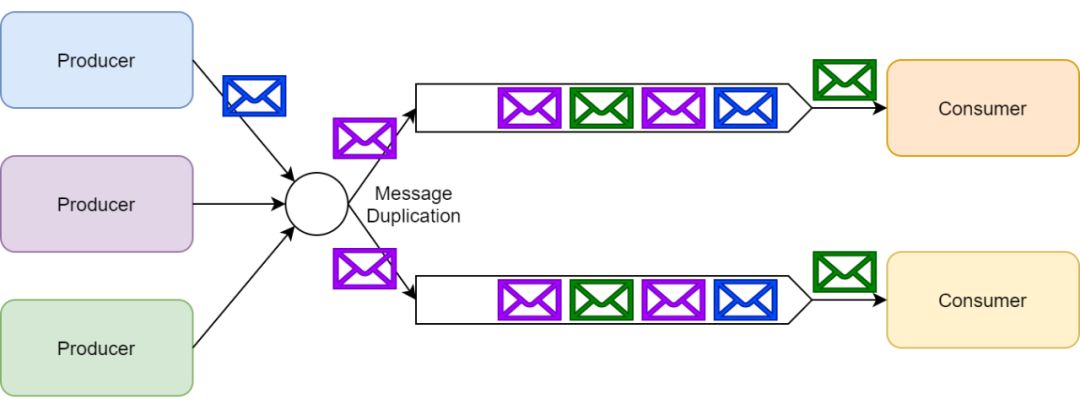
RabbitMQ 使用消息交換器來實現發布/訂閱模式。發布者可以把消息發布到消息交換器上而不用知道這些消息都有哪些訂閱者。
每一個訂閱了交換器的消費者都會創建一個隊列;然后消息交換器會把生產的消息放入隊列以供消費者消費。消息交換器也可以基于各種路由規則為一些訂閱者過濾消息。
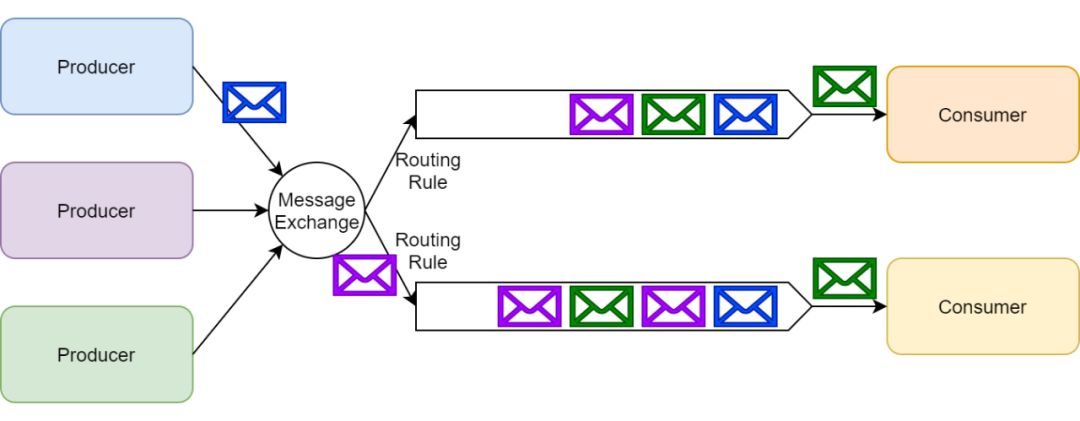
RabbitMQ 消息交換器
需要重點注意的是 RabbitMQ 支持臨時和持久兩種訂閱類型。消費者可以調用 RabbitMQ 的 API 來選擇他們想要的訂閱類型。
根據 RabbitMQ 的架構設計,我們也可以創建一種混合方法——訂閱者以組隊的方式然后在組內以競爭關系作為消費者去處理某個具體隊列上的消息,這種由訂閱者構成的組我們稱為消費者組。
按照這種方式,我們實現了發布/訂閱模式,同時也能夠很好的伸縮(scale-up)訂閱者去處理收到的消息。
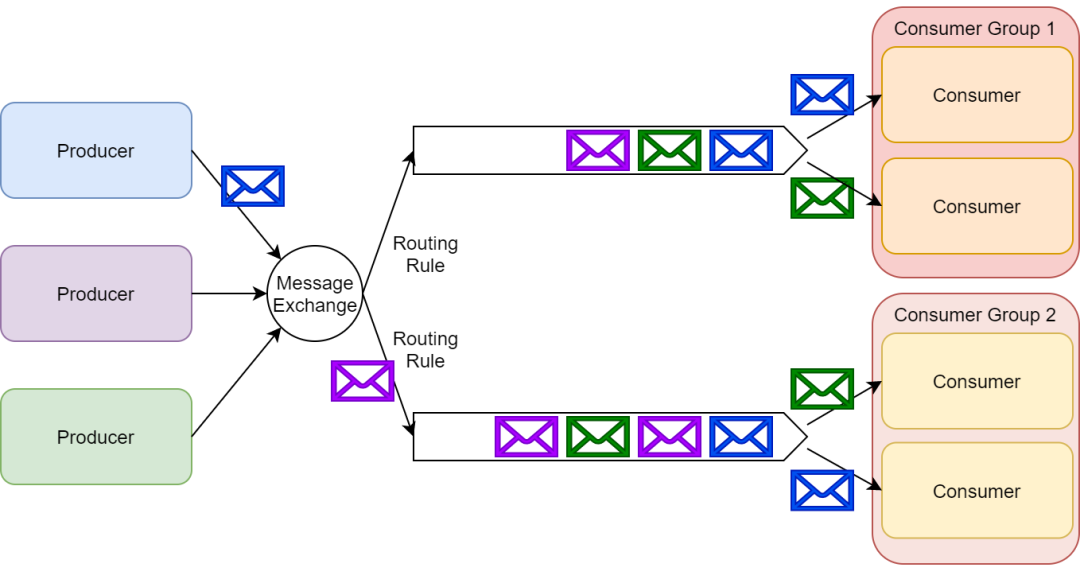
發布/訂閱與隊列的聯合使用
Apache Kafka
Apache Kafka 不是消息中間件的一種實現。相反,它只是一種分布式流式系統。
不同于基于隊列和交換器的 RabbitMQ,Kafka 的存儲層是使用分區事務日志來實現的。
Kafka 也提供流式 API 用于實時的流處理以及連接器 API 用來更容易的和各種數據源集成;當然,這些已經超出了本篇文章的討論范圍。
云廠商為 Kafka 存儲層提供了可選的方案,比如 Azure Event Hubsy 以及 AWS Kinesis Data Streams 等。
對于 Kafka 流式處理能力,還有一些特定的云方案和開源方案,不過,話說回來,它們也超出了本篇的范圍。
主題
Kafka 沒有實現隊列這種東西。相應的,Kafka 按照類別存儲記錄集,并且把這種類別稱為主題。
Kafka 為每個主題維護一個消息分區日志。每個分區都是由有序的不可變的記錄序列組成,并且消息都是連續的被追加在尾部。
當消息到達時,Kafka 就會把他們追加到分區尾部。默認情況下,Kafka 使用輪詢分區器(partitioner)把消息一致的分配到多個分區上。
Kafka 可以改變創建消息邏輯流的行為。例如,在一個多租戶的應用中,我們可以根據每個消息中的租戶 ID 創建消息流。
IoT 場景中,我們可以在常數級別下根據生產者的身份信息(identity)將其映射到一個具體的分區上。
確保來自相同邏輯流上的消息映射到相同分區上,這就保證了消息能夠按照順序提供給消費者。
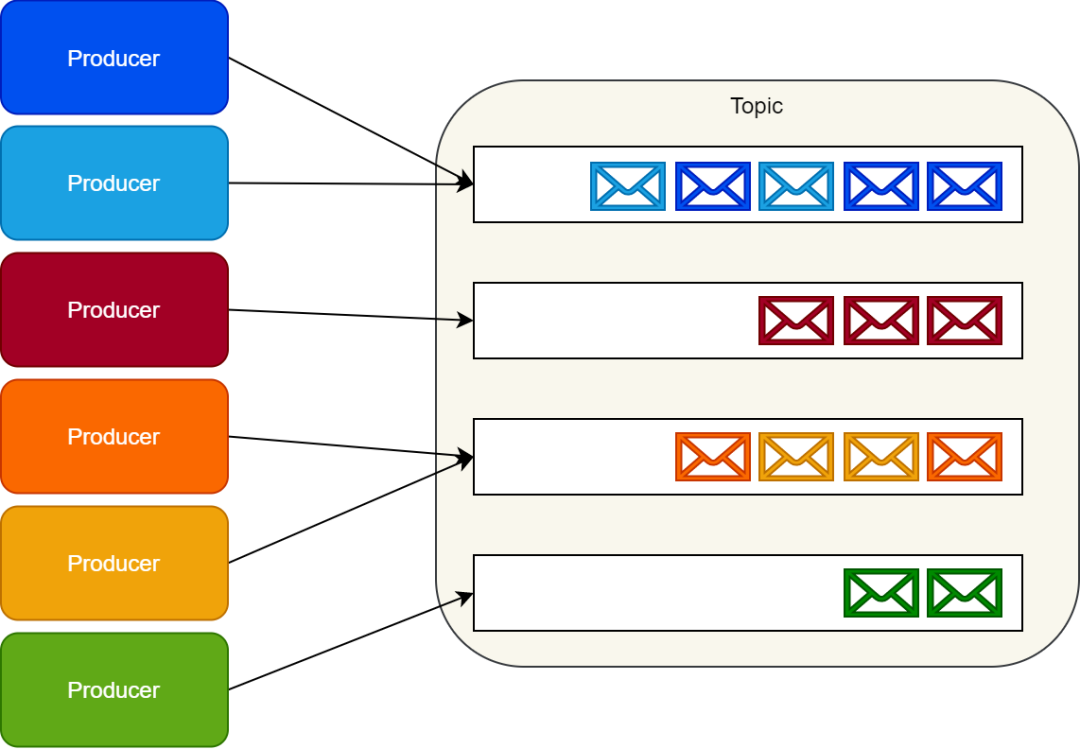
Kafka 生產者
消費者通過維護分區的偏移(或者說索引)來順序的讀出消息,然后消費消息。
單個消費者可以消費多個不同的主題,并且消費者的數量可以伸縮到可獲取的最大分區數量。
所以在創建主題的時候,我們要認真的考慮一下在創建的主題上預期的消息吞吐量。消費同一個主題的多個消費者構成的組稱為消費者組。
通過 Kafka 提供的 API 可以處理同一消費者組中多個消費者之間的分區平衡以及消費者當前分區偏移的存儲。
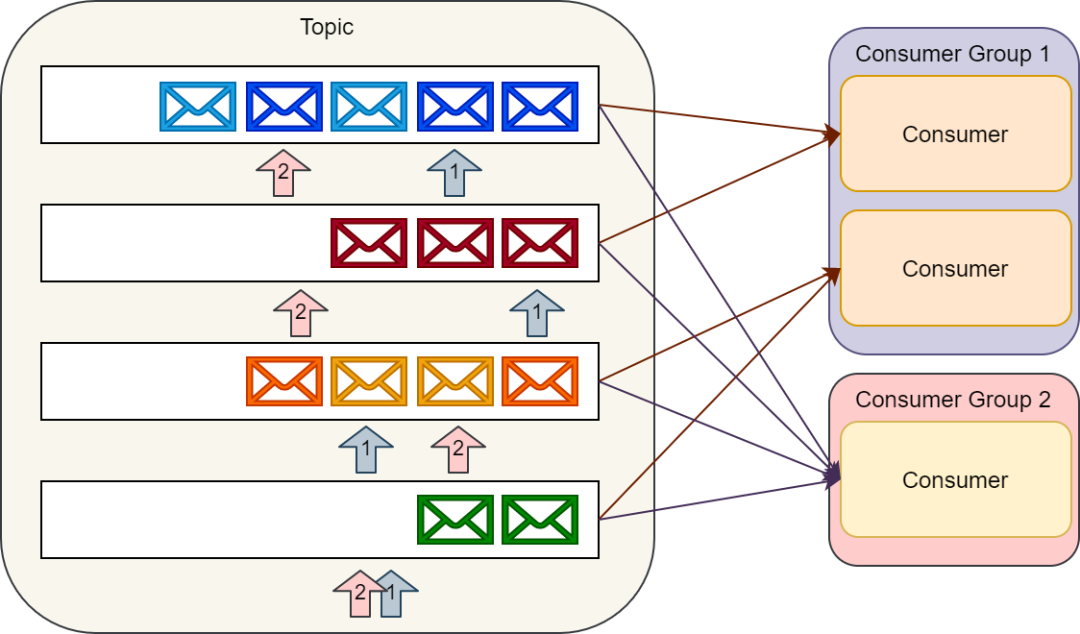
Kafka 消費者
Kafka 實現的消息模式
Kafka 的實現很好地契合發布/訂閱模式。生產者可以向一個具體的主題發送消息,然后多個消費者組可以消費相同的消息。每一個消費者組都可以獨立的伸縮去處理相應的負載。
由于消費者維護自己的分區偏移,所以他們可以選擇持久訂閱或者臨時訂閱,持久訂閱在重啟之后不會丟失偏移而臨時訂閱在重啟之后會丟失偏移并且每次重啟之后都會從分區中最新的記錄開始讀取。
但是這種實現方案不能完全等價的當做典型的消息隊列模式看待。當然,我們可以創建一個主題,這個主題和擁有一個消費者的消費組進行關聯。
這樣我們就模擬出了一個典型的消息隊列。不過這會有許多缺點,我們會在第二部分詳細討論。
值得特別注意的是,Kafka 是按照預先配置好的時間保留分區中的消息,而不是根據消費者是否消費了這些消息。
這種保留機制可以讓消費者自由的重讀之前的消息。另外,開發者也可以利用Kafka的存儲層來實現諸如事件溯源和日志審計功能。
結束語
盡管有時候 RabbitMQ 和 Kafka 可以當做等價來看,但是他們的實現是非常不同的。
所以我們不能把他們當做同種類的工具來看待;一個是消息中間件,另一個是分布式流式系統。
作為解決方案架構師,我們要能夠認識到它們之間的差異并且盡可能的考慮在給定場景中使用哪種類型的解決方案。
第二部分(未完成)會指出這些差異并且提供什么時候使用哪種方案的指導建議,后面會為大家更新。