













又一批長事務(wù),P0故障誰來背鍋?
最近幾周,發(fā)生過多起因?yàn)槭聞?wù)問題引起的服務(wù)報(bào)錯(cuò)。現(xiàn)象為數(shù)據(jù)庫連接池連接占滿,數(shù)據(jù)庫連接長時(shí)間等待,最終導(dǎo)致請求線程hang住,服務(wù)大面積報(bào)錯(cuò)。這個(gè)時(shí)候,服務(wù)資源、數(shù)據(jù)庫資源大量空閑,但就是進(jìn)行不下去,影響是比較惡劣的。
誰來背鍋?當(dāng)然是架構(gòu)師。因?yàn)檫@次所有的服務(wù)都活著,沒運(yùn)維什么事。
面試時(shí),大家可能都會碰到關(guān)于事務(wù)相關(guān)的問題,升級版的可能是分布式事務(wù)的問題。在互聯(lián)網(wǎng)行業(yè)中,一句馬馬虎虎的補(bǔ)償事務(wù)就能蒙混過關(guān),畢竟都是些短小精悍的接口。
但在很多企業(yè)級應(yīng)用中,這行不通。我們必須直面慘淡的現(xiàn)實(shí)。
為什么要用長事務(wù)?
在許多業(yè)務(wù)非常復(fù)雜的后臺系統(tǒng),經(jīng)常頻繁操作DB,為了保證數(shù)據(jù)的一致性,能夠在出錯(cuò)時(shí)回滾數(shù)據(jù),通常會使用事務(wù)。
就拿最簡單的單機(jī)數(shù)據(jù)庫事務(wù)來說。
在事務(wù)操作期間,如果持續(xù)時(shí)間過長,只有等事務(wù)結(jié)束之后,DB連接才會釋放,此類長時(shí)間占用DB連接的事務(wù)操作,稱為長事務(wù)。一旦外部有大量請求,并發(fā)調(diào)用此操作,那么將會有大量的DB連接被持有而沒有被釋放掉,直到連接池爆滿。
這個(gè)時(shí)候,如果有其他請求到來,那十有八九是以失敗告終。
也就是說,連接資源被少數(shù)長事務(wù)操作占用。在這種情況下,即使是最簡單接口查詢,都不能夠正常進(jìn)行。
幾粒老鼠屎,壞了一鍋粥。
一些魔幻的反應(yīng)
當(dāng)你去排查這種問題的時(shí)候,可能會陷入僵局。jstack顯示,多數(shù)請求其實(shí)是阻塞在tomcat的線程池上,而且是一些訪問速度非常快的請求被阻塞。
比如,tomcat的200個(gè)線程,有180個(gè)阻塞在耗時(shí)不到1ms的/status接口上。
很多人就一臉懵逼。經(jīng)驗(yàn)失靈。
jstack此時(shí)的輸出結(jié)果,欺騙了我們。真正造成阻塞的,是那額外的20多個(gè)線程。
有哪些改善?
保證事務(wù)的短小是一個(gè)基本要求,包括但不限于:
應(yīng)控制慢查詢的調(diào)用頻率,盡量減少慢查詢。很多情況下,這條規(guī)則是自欺欺人的,需要業(yè)務(wù)做一些妥協(xié)。
事務(wù)內(nèi)不應(yīng)包含任何RPC調(diào)用,減少事務(wù)的粒度。通常,一些RPC調(diào)用,包括其他非事務(wù)資源的調(diào)用,耗時(shí)非常不可控。如果把它們也納入事務(wù)的范圍之內(nèi),勢必會加劇資源的占用。事務(wù)內(nèi)不應(yīng)包含其他容易超時(shí)或者長時(shí)間阻塞的服務(wù),如HTTP調(diào)用、IO操作。
次優(yōu)先級服務(wù)如消息隊(duì)列,不應(yīng)該放在事務(wù)內(nèi),避免因?yàn)橄㈥?duì)列不可用引起的服務(wù)不可用。給類似消息隊(duì)列的組件,設(shè)置一個(gè)合理的超時(shí)時(shí)間的非常有必要的,否則它就會一直等在那里。但即使是這樣,也盡量不要把它們納入到事務(wù)操作之內(nèi)。
跨庫、跨類型(如Redis),不應(yīng)該放在同一事務(wù)中,可避免交叉影響。
你可以看到上面的這些描述,有些和我們所追求的數(shù)據(jù)一致性是相悖的。這不奇怪,依然是CAP原理的權(quán)衡。有些業(yè)務(wù)選擇的是寧可卡死不再響應(yīng),也不能進(jìn)入異常數(shù)據(jù);有些則首先讓業(yè)務(wù)運(yùn)行下去,臟數(shù)據(jù)會通過補(bǔ)償事務(wù)進(jìn)行修正。
一切看你的選擇。
設(shè)計(jì)總有人背鍋,補(bǔ)償總有人做出犧牲。
解決方式
那么如何來快速解決大事務(wù)造成的服務(wù)不可用問題呢?
除了擴(kuò)容,其實(shí)是無解。重啟大法也不見得好用。因?yàn)楸蛔钄嗟恼埱螅瑫愿鼉疵偷膽B(tài)勢再次來襲。
你可能會想到調(diào)大連接池的大小。但在實(shí)踐中得知,也不好用,大事務(wù)請求會迅速將連接池占滿。
但我們可以提前進(jìn)行防御。
以Spring為例,事務(wù)的使用方式大多數(shù)是使用@Transactional注解來控制的,或者是聲明式事務(wù)方式。我建議以以下方式進(jìn)行預(yù)防和發(fā)現(xiàn):
1) 重新掃描或者Review業(yè)務(wù)代碼,排查事務(wù)中是否有以上提到的各種情況。然后將除DB操作外的其他操作移動到事務(wù)之外。
2) 每個(gè)事務(wù)操作都給予足夠重視,對于執(zhí)行復(fù)雜度和時(shí)間復(fù)雜度不確定的事務(wù),添加超時(shí)報(bào)警,及時(shí)發(fā)現(xiàn)引起的原因。
同時(shí),還需要加強(qiáng)監(jiān)控,輔助進(jìn)行問題排查。
1) 業(yè)務(wù)可以考慮定時(shí)將數(shù)據(jù)庫連接池的信息進(jìn)行打印,通過看日志的方式進(jìn)行初步排查。
2) 使用jstack查詢執(zhí)行棧,找出阻塞的點(diǎn)。
3) 排查并聯(lián)系下游服務(wù),找出主要原因
xjjdog傾向于使用監(jiān)控快速發(fā)現(xiàn)問題。如圖,通過連接池監(jiān)控,可以看到數(shù)據(jù)庫連接池連接數(shù)長時(shí)間保持在高位不釋放,同時(shí)等待的線程數(shù)急劇增加。發(fā)生此種現(xiàn)象多數(shù)可以考慮是否是以上原因引起。
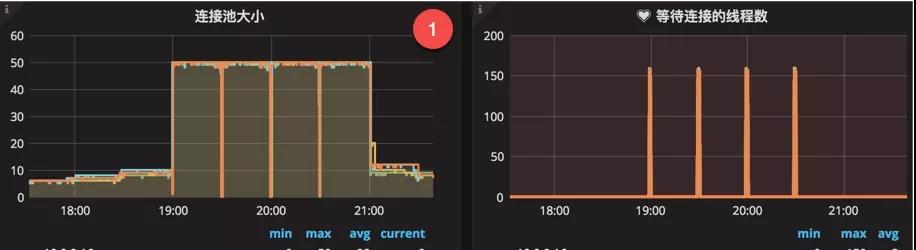
發(fā)生問題時(shí),應(yīng)及時(shí)(多次)使用jstack定位到線程的阻塞位置,然后排查下游服務(wù)是否有問題,或者是否存在慢查詢。
最好的情況是服務(wù)已經(jīng)進(jìn)行了對代碼的梳理,那么引起的原因大概率只剩下了慢查詢。針對慢查詢,druid數(shù)據(jù)庫連接池,提供了sql的聚合,能夠查看是每一類查詢語句的具體執(zhí)行情況。如圖,短時(shí)間內(nèi)SQL請求飆升,最大執(zhí)行時(shí)長上升,連接池占滿:
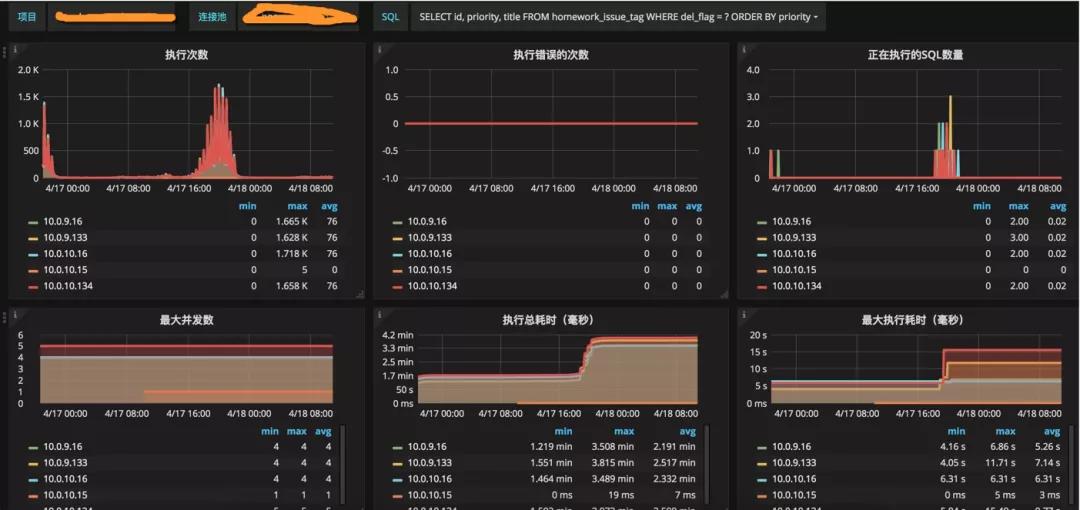
具體是哪一句SQL所引起的,一目了然。
End
長事務(wù)問題的危險(xiǎn)級別屬于高危型,通常會造成嚴(yán)重的后果,可以通過觀察監(jiān)控,防范于未然。
最優(yōu)的解決方式,當(dāng)然是業(yè)務(wù)模型的改進(jìn)。但這東西第一涉及到開發(fā)成本,第二涉及到跨部門協(xié)作。
出錢的老板,無法聽懂你這些夢話。
在一些公司內(nèi)部,這兩者都是讓人抓狂的事情,還不如痛痛快快背個(gè)鍋,來得實(shí)在。





















