Apache Flink 掃雷系列 - PyFlink如何解決多JAR包依賴問(wèn)題
《Apache Flink 掃雷系列》簡(jiǎn)介
本篇是《Apache Flink 掃雷系列》的第一篇,所以簡(jiǎn)單介紹一下這一系列的特點(diǎn),本系列所定義的”雷”是指由于目前Apache Flink目前的設(shè)計(jì)問(wèn)題導(dǎo)致的用戶非便利性問(wèn)題的臨時(shí)解決辦法。那么為什么明知道有設(shè)計(jì)問(wèn)題還不進(jìn)行設(shè)計(jì)重構(gòu),避免這些”雷”的存在呢?其實(shí)社區(qū)的發(fā)展和我們各個(gè)公司內(nèi)部產(chǎn)品發(fā)展一樣,都有一些客觀因素導(dǎo)致實(shí)際存在的問(wèn)題無(wú)法及時(shí)得到解決,比如,社區(qū)的Release或者內(nèi)部產(chǎn)品發(fā)布的的周期問(wèn)題,在沒(méi)有新的Release之前的一些對(duì)用戶非友好的問(wèn)題就需要有一些“非正規(guī)”的解決方式,或者說(shuō)是臨時(shí)解決方案,這種方案的特點(diǎn)就是,能解決問(wèn)題,但不是通用性解決手段,只能民間流傳,不能官方宣揚(yáng)。所以《Apache Flink 掃雷系列》就是為大家提供能夠解決大家現(xiàn)實(shí)問(wèn)題,但是可能不是最佳實(shí)踐,大家在這系列中可以有更大的反哺社區(qū)的機(jī)會(huì):)
開(kāi)篇說(shuō)”雷”
本篇的”雷”是目前針對(duì)Apache Flink 1.10集以前版本中,在利用CLI提交作業(yè)時(shí)候只能提交一個(gè)JAR的功能問(wèn)題解決,也就是針對(duì)命令參數(shù)-j,--jarfile
掃雷難度
面對(duì)合并多個(gè)JAR包,也許Java用戶還好(雖然不便利,但應(yīng)該都會(huì)操作),但對(duì)于Python用戶,在沒(méi)有涉及過(guò)Java開(kāi)發(fā)的情況下,可能要花費(fèi)一些時(shí)間來(lái)完成JARs的合并,甚至有可能有種無(wú)從下手的感覺(jué)。所以本篇主要針對(duì)的是不了解Java的Flink Python用戶。
案例選取
為了大家能夠?qū)嶋H的體驗(yàn)實(shí)際效果,我們選取一個(gè)具體的案例來(lái)說(shuō)明如果進(jìn)行多JARs的合并。我們就選取我在2020年3月17日直播中所說(shuō)的《PyFlink 場(chǎng)景案例 - PyFlink實(shí)現(xiàn)CDN日志實(shí)時(shí)分析》來(lái)進(jìn)行說(shuō)明。
案例回顧
《PyFlink 場(chǎng)景案例 - PyFlink實(shí)現(xiàn)CDN日志實(shí)時(shí)分析》核心是針對(duì)灌入Kafka的CDN日志數(shù)據(jù)經(jīng)過(guò)PyFlink進(jìn)行按地區(qū)的下載量,下載速度的統(tǒng)計(jì),最終將統(tǒng)計(jì)數(shù)據(jù)寫入到MySql中。同時(shí)放入到Kafka的數(shù)據(jù)格式是CSV('format.type' = 'csv')。所以我們依賴的JARs如下:
- flink-sql-connector-kafka_2.11-1.10.0.jar
- flink-jdbc_2.11-1.10.0.jar
- flink-csv-1.10.0-sql-jar.jar
- mysql-connector-java-8.0.19.jar
我們可以用如下命令下載:
- $ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.10.0/flink-sql-connector-kafka_2.11-1.10.0.jar
- $ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-jdbc_2.11/1.10.0/flink-jdbc_2.11-1.10.0.jar
- $ curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-csv/1.10.0/flink-csv-1.10.0-sql-jar.jar
- $ curl -O https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.19/mysql-connector-java-8.0.19.jar
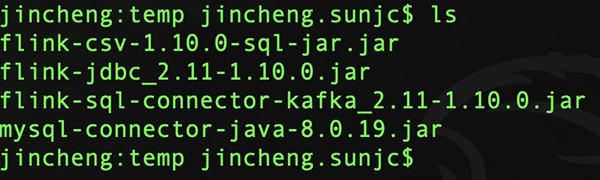
我們將如上4個(gè)JARs下載到某個(gè)目錄,我這里下載到本機(jī)的temp目錄:
“雷”存在的場(chǎng)景說(shuō)明
為啥在博客《PyFlink 場(chǎng)景案例 - PyFlink實(shí)現(xiàn)CDN日志實(shí)時(shí)分析》并沒(méi)有提到要合并JARs的問(wèn)題? 是的,這個(gè)“雷”的存在是有一定的條件的:
作業(yè)提交的集群環(huán)境沒(méi)有預(yù)先安裝你所有需要的JARs(大部分情況都是不會(huì)安裝的)
上面條件是必須成立,才會(huì)存在掃雷的問(wèn)題。那么在博客中我在集群環(huán)境預(yù)安裝了說(shuō)需要的JARs,也就是博客中提到的下載JARs到集群lib目錄
- PYFLINK_LIB=python -c "import pyflink;import os;print(os.path.dirname(os.path.abspath(pyflink.__file__))+'/lib')")
的操作。
合并JARs的注意點(diǎn)
合并JARs的一個(gè)很重要的點(diǎn)是涉及到了JAR包的Service Provider機(jī)制,詳細(xì)規(guī)范詳見(jiàn)。這是讓Python人員是很難注意到的合并重點(diǎn)。JAR包的Service Provider機(jī)制會(huì)允許在JAR包的META-INF/services目錄下保存Service Provider的配置文件。簡(jiǎn)單說(shuō)就是他為開(kāi)發(fā)者提供了一種擴(kuò)展機(jī)制,在開(kāi)發(fā)階段只是定義接口,然后在包含實(shí)現(xiàn)的JAR包進(jìn)行實(shí)現(xiàn)配置,就可以調(diào)用到實(shí)際接口的實(shí)現(xiàn)類。關(guān)于JAR包META-INF目錄結(jié)構(gòu)簡(jiǎn)單說(shuō)明如下:
- META-INF - 目錄中的下列文件和目錄獲得Java 2平臺(tái)的認(rèn)可與解釋,用來(lái)配置應(yīng)用程序、擴(kuò)展程序、類加載器和服務(wù):
- MANIFEST.MF - 清單文件,用來(lái)定義與擴(kuò)展和數(shù)據(jù)包相關(guān)的數(shù)據(jù)。
- INDEX.LIST - 這個(gè)文件由JAR工具的新“-i”選項(xiàng)生成,其中包含在一個(gè)應(yīng)用程序或擴(kuò)展中定義的數(shù)據(jù)包的地址信息。它是JarIndex的一部分,被類加載器用來(lái)加速類加載過(guò)程。
- x.SF - JAR文件的簽名文件。x代表基礎(chǔ)文件名。
- x.DSA - 這個(gè)簽名塊文件與同名基礎(chǔ)簽名文件有關(guān)。此文件存儲(chǔ)對(duì)應(yīng)簽名文件的數(shù)字簽名。
- services - 這個(gè)目錄存儲(chǔ)所有服務(wù)提供程序配置文件。
注意:provider配置文件必須是以UTF-8編碼。
合并操作
1. 解壓JARs
- $ mkdir jobjar csv jdbc kafka mysql
其中jobjar存放最終我們打包的JAR內(nèi)容, csv jdbc kafka mysql存放對(duì)應(yīng)的JAR所解壓的內(nèi)容。具體命令如下:
- $ unzip flink-csv-1.10.0-sql-jar.jar -d csv/
- $ unzip flink-sql-connector-kafka_2.11-1.10.0.jar -d kafka/
- $ unzip flink-jdbc_2.11-1.10.0.jar -d jdbc/
- $ unzip mysql-connector-java-8.0.19.jar -d mysql
解壓之后我們會(huì)在剛才的目錄得到如下文件內(nèi)容:
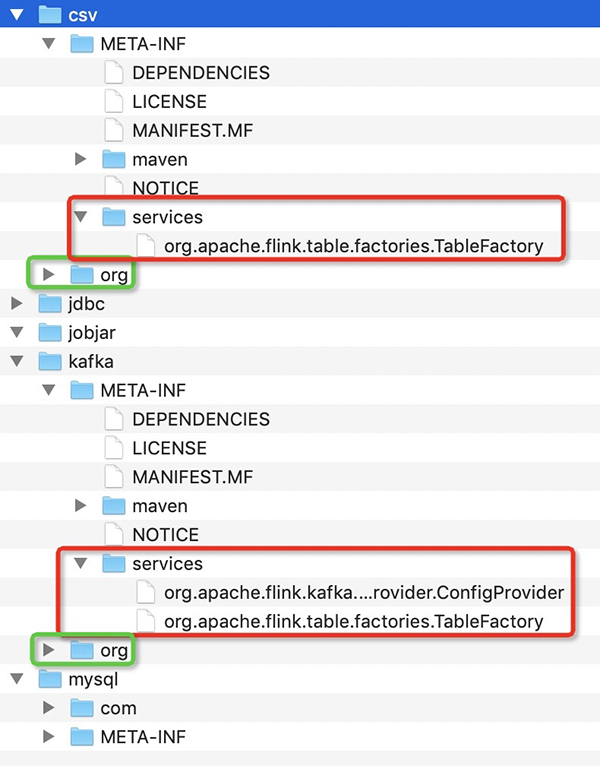
我們核心要處理的是class文件夾和 META-INF/services文件夾,如圖csv和kafka的JAR解壓之后的內(nèi)容。其中,Class文件夾可以直接拷貝。但是services要進(jìn)行同名的合并,比如上用于Flink的Connector的服務(wù)發(fā)現(xiàn)配置org.apache.flink.table.factories.TableFactory是需要將文件內(nèi)容進(jìn)行合并的。
2. 合并JARs
首先我們創(chuàng)建META-INF和META-INF/services目錄,目錄結(jié)構(gòu)如下:
- jincheng:jobjar jincheng.sunjc$ tree -L 2
- .
- └── META-INF
- └── services
- 2 directories, 0 files
(1) class文件合并
將csv jdbc kafka mysql的class直接copy到j(luò)objar目錄,如下:
- $ cp -rf ../csv/org .
- $ cp -rf ../jdbc/org .
- $ cp -rf ../kafka/org .
- $ cp -rf ../mysql/com .
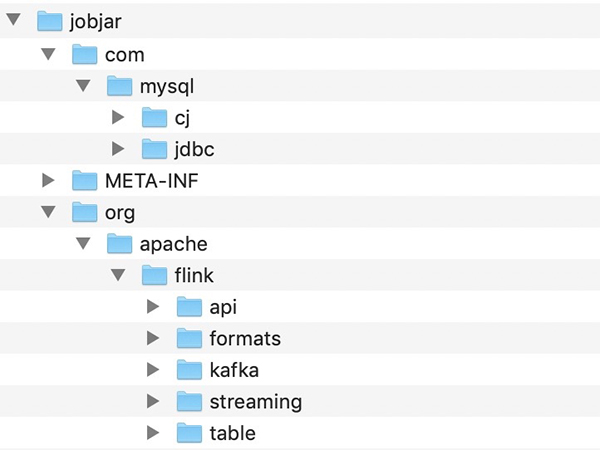
- $ tree -L 2
- .
- ├── META-INF
- │ └── services
- ├── com
- │ └── mysql
- └── org
- └── apache
詳細(xì)的目錄結(jié)構(gòu)如下:
(2) services合并
Service Provider是JAR的一個(gè)標(biāo)準(zhǔn),不僅僅Flink的Connector使用了Service Provider機(jī)制,同時(shí)Kafka使用了配置的服務(wù)發(fā)現(xiàn)。所以我們要將所有的services里面的內(nèi)容按文件名進(jìn)行合并。以csv和kafka為例:
在CSV里面的META-INF/services里面只有一個(gè)和Flink的connector相關(guān)的配置,內(nèi)容如下:
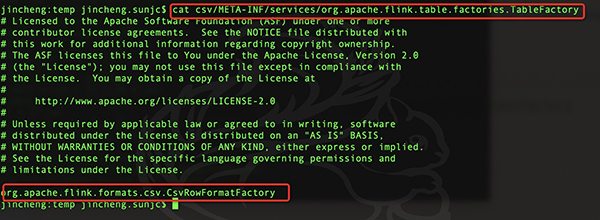
在Kafka里面的META-INF/services里面有Flink的connector相關(guān)的配置和Kafka內(nèi)部使用的配置,內(nèi)容如下:

所以我們需要將Kafka相關(guān)的直接copy到j(luò)objar/META-INF/services/目錄,然后將csv和Kafka關(guān)于org.apache.flink.table.factories.TableFactory的配置進(jìn)行內(nèi)容合并。合并的內(nèi)容如下:
- # Licensed to the Apache Software Foundation (ASF) under
- ...
- ...
- # limitations under the License.
- org.apache.flink.formats.csv.CsvRowFormatFactory
- org.apache.flink.streaming.connectors.kafka.KafkaTableSourceSinkFactory
我們最終將4個(gè)JARs的services配置進(jìn)行合并之后的最終代碼如下:
- # Licensed to the Apache Software Foundation (ASF) under
- ...
- ...
- # limitations under the License.
- org.apache.flink.formats.csv.CsvRowFormatFactory
- org.apache.flink.streaming.connectors.kafka.KafkaTableSourceSinkFactory
- org.apache.flink.api.java.io.jdbc.JDBCTableSourceSinkFactory
大家可以嘗試使用的命令如下:
- $ cat ../csv/META-INF/services/org.apache.flink.table.factories.TableFactory | grep ^[^#] >> META-INF/services/org.apache.flink.table.factories.TableFactory
- $ cat ../kafka/META-INF/services/org.apache.flink.table.factories.TableFactory | grep ^[^#] >> META-INF/services/org.apache.flink.table.factories.TableFactory
- $ cat ../kafka/META-INF/services/org.apache.flink.kafka.shaded.org.apache.kafka.common.config.provider.ConfigProvider | grep ^[^#] >> META-INF/services/org.apache.flink.kafka.shaded.org.apache.kafka.common.config.provider.ConfigProvider
- $ cat ../jdbc/META-INF/services/org.apache.flink.table.factories.TableFactory | grep ^[^#] >> META-INF/services/org.apache.flink.table.factories.TableFactory
3. 創(chuàng)建JAR
這一步驟沒(méi)有特別強(qiáng)調(diào)的內(nèi)容,直接用用zip或者jar命令進(jìn)行打包就好了。
- $ jincheng:jobjar jincheng.sunjc$ jar -cf myjob.jar META-INF com org
我最終產(chǎn)生的JAR可以在這里下載,用于對(duì)比你自己打包的是否和我的一樣:)
OK,到這里我們就完成了多JARs的合并工作。我們可以嘗試應(yīng)用CLI進(jìn)行提交命令了。
CLI提交作業(yè)
- 啟動(dòng)集群(我修改了flink-conf,將端口更改到4000了)
- /usr/local/lib/python3.7/site-packages/pyflink/bin/start-cluster.sh local
- Starting cluster.
- Starting standalonesession daemon on host jincheng.local.
- Starting taskexecutor daemon on host jincheng.local.
當(dāng)沒(méi)有添加-j選項(xiàng)時(shí)候,提交作業(yè)如下:
- $PYFLINK_LIB/../bin/flink run -m localhost:4000 -py cdn_demo.py
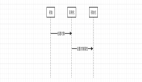
報(bào)錯(cuò)如下:

提供正確的-j參數(shù),將我們打包的JAR提交到集群的情況,如下:
- $PYFLINK_LIB/../bin/flink run -j ~/temp/jobjar/myjob.jar -m localhost:4000 -py cdn_demo.py

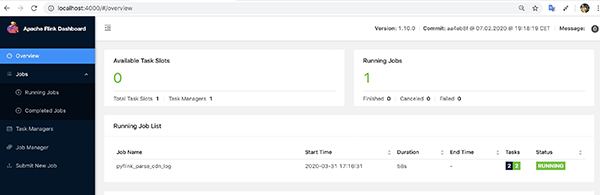
同時(shí)Web控制臺(tái)可以查看提交的作業(yè):
小結(jié)
本篇核心介紹了PyFlink的用戶如何解決多JARs依賴作業(yè)提交問(wèn)題,也許這不是最Nice的解決方法,但至少是你解決多JARs依賴作業(yè)提交的方法之一,祝你 “掃雷” 順利,也期望如果你有更好的解決辦法,留言或者郵件與我分享哦:)!
【本文為51CTO專欄作者“金竹”原創(chuàng)稿件,轉(zhuǎn)載請(qǐng)聯(lián)系原作者】