Apache Flink 漫談系列 - PyFlink核心技術揭秘
原創
大家好,非常高興在今天的峰會能與大家一起分享Apache PyFlink的核心技術部分。

首先,還是簡單的自我介紹一下,我是孫金城,花名 金竹,來自阿里巴巴,從2016年開始一直投入在開源建設中,目前是Apache Flink PMC成員,Apache Beam Committer和Apache IoTDB的PMC成員。同時也是Apache 軟件基金會的成員,Apache Member。平時也喜歡寫一些技術類博客和錄制一下視頻課程,也歡迎大家關注我的公眾號。

今天我們有4個部分的內容分享,首先我們快速了解一下PyFlink的使命愿景,然后重點介紹PyFlink的核心技術點,最后是和大家快速介紹PyFlink的未來規劃和現有的應用案例。那么我們開始今天的第一部分,PyFlink的使命愿景。

首先,Apache Flink 是一個有狀態的分布式流式計算框架。可以作用在有限和無限的數據集合之上。
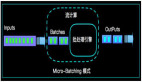
那么業界對有限和無限數據集合上進行流式計算處理,有2種典型的架構,一個是Micro-Batching的模式,也就是將流看成是批的特例。那么另一種就是Apache Flink的架構模式,純流的架構模式,將批看成是流的特例。純流的設計將計算的延時做到了極致。

那么Flink這種分布式亞秒級延時的能力如何暴露給用戶呢?Flink提供了SQL,DataStream和ProcessFunction多層API供用戶選擇,但是非常遺憾的是只能提供給Java用戶群體。
那么,如果將Flink的能力進行放大,面向更多的用戶群體將是一件非常有意義的事情,那么如何在在Flink上進行多語言的支持呢?增加哪些語言的支持呢?

我們在進行PyFlink的工作之前進行了一些調研,我們發現Python語言在2020年的活躍程度超過了Java語言,并且是一個持續上升的趨勢。

那么我們再進一步了解,為什么Python語言如此備受關注,大家都利用Python語言完成怎樣的工作呢?帶著這些問題,隨著AI的崛起,Python不僅僅廣泛應用在數據分析和web開發領域,更多的也在AI/機器學習領域也有廣泛應用。更有趣的一件事是,連公路巡警的愛好都變成了Python編程,8/9歲的小孩也在用Python做趣味游戲。這足以見證Python的受歡迎程度。所以將Python作為Flink多語言支持最重要的開發語言。

Python非常受歡迎,并且Python有非常成熟的生態發展,但是這里有一個典型的問題,那就是這些生態庫大多是單機模式,在大數據時代的今天,Python生態面臨的一個典型問題就是:
如何支持海量數據的處理,如何提供分布式能力?

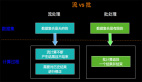
所以,面對Flink能力需要面向更多的用戶群體,Python又是最受歡迎的語言,Python就成為了Flink多語言支持的第一個語言。同時面對Python語言的分布式能力的匱乏,PyFlink的使命也是要將Python生態具備分布處理能力。所以,Pyflink的使命就是Flink能力輸出到Python用戶,并令Python生態具備分布式化能力。

好的,接下來我們看看PyFlink如何完成自己的使命,有哪些核心的技術細節。

首先,Flink能力輸出到Python用戶最核心問題顯而易見是Python VM和Java VM的握手,他們之間要建立通訊,這是PyFlink首要解決的問題。

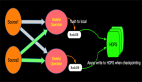
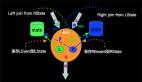
面對PVM和JVM通訊問題,我們選擇了Py4J,在PythonVM啟動一個Gateway,并且Java VM啟動一個Gateway Server用于接受Python的請求,同時在Python API里面提供和Java API一樣的對象,比如 TableENV, Table,等等。這樣Python在寫Python API的時候本質是在調用Java API,同時還有作業部署問題,我們可以用Python命令,Python shell和CLI等多種方式進行作業提交。

那么Py4J和JVM交互的原理是什么呢?其實最核心的機制是在Python端每創建一個對象,都會對應的在Java端創建一個Java對象,并生成一個對象ID,Java端利用Map保存對象ID和對象。同時將對象ID返回Python端,Python端基于對象ID和方法參數進行操作本質上都是在操作Java對象。
 那么基于這樣的架構有怎樣的優勢呢?第一個就是簡單,并確保Python API語義和Java API的一致性,第二點,Python 作業可以達到和Java一樣的極致性能,在剛剛結束的阿里雙11狂歡節中,創造了峰值40億的處理能力。
那么基于這樣的架構有怎樣的優勢呢?第一個就是簡單,并確保Python API語義和Java API的一致性,第二點,Python 作業可以達到和Java一樣的極致性能,在剛剛結束的阿里雙11狂歡節中,創造了峰值40億的處理能力。

OK,在完成了現有Flink功能向Python用戶的輸出之后,接下來我們繼續探討,如何將Python生態功能引入Flink中,進而將Python 功能分布式化。如何達成?結合現有Flink Table API的現狀和現有Python類庫的特點,我們可以對現有所有的Python類庫功能視為 用戶自定義函數(UDF),集成到Flink中。這樣我們就找到了集成Python生態到Flink中的手段是將其視為UDF,那么集成的核心問題是什么?沒錯,那就是Python UDF的執行問題。好,我們針對這個核心問題我們如何處理呢?

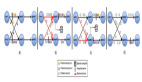
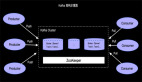
解決Python UDF執行問題可不僅僅是VM之間通訊的問題了,它涉及到Python執行環境的管理,業務數據在Java和Python之間的解析,Flink State Backend能力向Python的輸出,Python UDF執行的監控等等,是一個非常復雜的問題。面對這樣復雜的問題,我們選擇了統一編程模型Apache Beam,Beam為了解決多語言和多引擎支持問題高度抽象了一個叫 Portability Framework 的架構,如下圖,Beam目前可以支持Java/Go/Python等多種語言,其中圖下方 Beam Fu Runners 和 Execution之間就解決了 引擎和UDF執行環境的問題。其核心是對利用Protobuf進行數據結構抽象,利用gRPC協議進行通訊,同時封裝了核心的gRPC 服務。所以這時候Beam更像是一只螢火蟲,照亮了PyFlink解決UDF執行問題之路。我們接下來看看Beam到底提供了哪些gRPC服務。

如圖 Runner部分是Java的算子執行,SDK Worker部分是Python的執行環境,Beam已經抽象Control/Data/State/Logging等服務。并這些服務已經在Beam的Flink runner上穩定高效的運行了很久了。所以在PyFlink UDF執行上面我們可以站在巨人的肩膀上了:),這里我們發現Apache Beam 在API層面和在UDF的執行層面都有解決方案,而PyFlink在API層面采用了Py4J解決VM通訊問題,在UDF執行需求上采用了Beam的Protability Framework解決UDF執行環境問題。這也表明了PyFlink在技術選型上嚴格遵循以最小的代價達成既定目標的原則,在技術選型上永遠會選擇最合適的,最符合PyFlink長期發展的技術架構。

好,那么現在我們回答,Flink如何支持多語言呢?
在API層面,其他語言要搞定algin現有的Java語言API。
在語言的執行環境問題上面,Flink可以重用Beam提供的基礎設施。換句話說,我們可以在Flink runner和fnapi級別上輕松地重用基本服務和數據結構。這將使Flink很容易支持多種語言。
下面的內容我們一起看看PyFlink的UDF架構設計。

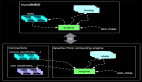
K,我們再整體看一下 PyFlink UDF的整體架構。在UDF的架構中我們我既要考慮Java VM和Python VM的通訊問題,又要考慮在編譯階段和在運行階段的不同需求。
圖中我們以綠色表示Java VM的行為,藍色表示Python VM的行為。
首先我們看看編譯階段,也就是local的設計,在local的設計是純API的mapping調用,我們仍然要過Py4J來解決通訊問題。也就是如圖Python每執行一個API就會同步的調用Java所對應的API。對UDF的支持上,需要添加UDF注冊的API,register_function,但僅僅是注冊還不夠,用戶在自定義Python UDF的時候往往會依賴一些三方庫,
所以我們還需要增加添加依賴的方法,那就是一系列的add方法,比如add_Python_file()。
在編寫Python作業的同時,Java API也會同時被調用在提交作業之前,Java端會構建.JobGraph。然后通過CLI等多種方式將作業提交到集群進行運行。
我們再來看看運行時Python和Java的不同分工情況,首先在Java端與普通Java作業一樣,JobMaster將作業分配給TaskManger,TaskManager會執行一個個Task,task里面就涉及到了Java和Python的算子執行。
在Python UDF的算子中我們會設計各種gRPC服務來完成Java VM和Python VM的各種通訊,比如 DataService 完成業務數據通訊,StateService完成Python UDF對Java Statebackend的調用,當然還有Logging和Metrics等其他服務。這些服務都是基于Beam的Fn API來構建的,最終在Python的Worker里面運行用戶的UDF,運行結束之后再利用對應的gRPC服務將結果返回給Java端的PythonUDF算子。
當然Python的worker不僅僅是Process模式,可以是Docker模式甚至是External的服務集群。這種擴展機制,為后面PyFlink與Python生態的其他框架集成打下了堅實的基礎。

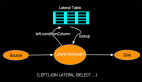
這里最重要的是如何使用beam的基礎設施來執行Python UDF。我們來看看pyflink如何集成Beam的可移植性框架來執行Python UDF。一個場景的場景是對輸入數據執行一系列轉換并將結果寫入另一個外部存儲系統。我們知道Flink是用Java 開發的,但是,用戶定義的轉換邏輯是Python開發的。如圖示例,假設ParDo使用了Python UDF,在Beam中引入了一個ExecutableStage,它包含了用戶定義的Python函數的所有必要信息,如:輸入/輸出數據類型、用戶定義函數的有效負載、用戶定義函數中使用的狀態和定時器等等。同時,Beam還提供了一個Java庫,可用于管理特定語言的執行環境。”forStage()“將根據ExecutableStage中定義的信息生成執行用戶定義函數所需的進程,就是SDK harness部分,這樣建立runner與SDK Harness之間就建立起了通訊連接。

Beam的SDK harness支持執行多種功能,例如ParDo、Flatten等;?不同的函數有不同的執行模式,因此SDK harness定義了一個特定的操作類來執行它。但是我們怎樣才能清楚地定義beam中每個函數的執行邏輯呢?Beam提供了非常靈活的插件機制,也就是為每種類型的函數定義一個URN,比如Input/output/parDo等。這樣的插件機制也為Flink集成Beam框架提供了便利途徑。

那么在PyFlink中使用Python SDK Harness的作原理如下:?
在啟動階段,Python SDK Harness將為所有內置操作建立URN和操作映射。
在處理新包的初始化階段,運行程序將把URN和函數一起發送到SDK Harness。SDK Harness可以根據給定的URN構造相應的操作。然后使用該操作來執行輸入的數據和對應的用戶定義函數邏輯。
我們看到如圖我們定義各種URN,包括input/output,coder等等。

OK,那么注冊URN也非常簡單,就是我們添加了一些用于創建自定義操作和Coder的函數。這些函數用Beam的python sdk工具包中定義的decorator進行裝飾。decorator包含兩個參數:URN和一個基于protobuf的自定義參數。

OK,支持了Python UDF之后,我們還將Pandas的與PyFlink進行了集成,我們可以非常便利的在PyFlink中定義PandasUDF,同時我們還提供了frompandas和topandas的api支持Flink和Pandas間的操作轉換。
同時我們在udf的執行性能上也不斷的優化,在1.11的版本相對于1.10有30倍的性能提升。

OK,接下來我們快速看看PyFlink的未來規劃。

PyFlink的發展始終要以本心驅動,我們要圍繞將現有Flink功能輸出到Python用戶,將Python生態功能集成到Flink當中為目標。
首先解決Python VM和Java VM的通訊問題,
然后將現有的Table API功能暴露給Python用戶,提供Python Table API,
這也就是Flink 1.9中所進行的工作,
接下來我們要為將Python功能集成到Flink做準備就是集成Apache Beam,提供Python UDF的執行環境,
并增加Python 對其他類庫依賴的管理功能,
為用戶提供User-defined-Funciton的接口定義,支持Python UDF,
這就是Flink 1.10所做的工作。
為了進一步擴大Python生態的分布式功能,PyFlink將提供Pandas的Series和DataFram的支持,也就是用戶可以在PyFlink中直接使用Pandas的UDF。
同時為增強用戶的易用性,讓用戶有更多的方式使用PyFlink,后續增加在Sql Client中使用Python UDF。
面對Python用戶的機器學習問題,增加Python 的 ML pipeline API。
監控Python UDF的執行情況對,對實際的生產業務非常關鍵,所以PyFlink會增加Python UDF的Metric管理. 這就是在Flink1.11中的工作。
同時我們還需要對性能不斷有優化,對Datastream和已經k8s等提供支持,這些在PyFlink 1.12中提供給大家。
后續還會不斷將Flink現有功能推向Python生態,將Python 生態的強大功能不斷集成到Flink當中,進而完成Python生態分布化的初衷。

當然,PyFlink同樣會注重生態的集成,如與Zeppelin,jupyter,PyAlink等集成工作的推進。

最后,快速看一下PyFlink的應用案例。

PyFlink可以應用在事件驅動/數據分析/ETL/機器學習等多種場景中。目前也有很多的投產用戶。
比如,比特幣大陸,聚美優品等等。目前PyFlink已經趨于成熟,非常適合大家選擇Flink快速構建分布式計算系統的切入開發語言。

目前PyFlink功能趨于完備,當然也會有更多的工作要做,但無論如何,我相信后續會慢慢成熟起來!我將會在2020年12月份開始將精力投入到IoT領域,開啟一段新的探索~
作者介紹
孫金城,51CTO社區編輯,Apache Flink PMC 成員,Apache Beam Committer,Apache IoTDB PMC 成員,ALC Beijing 成員,Apache ShenYu 導師,Apache 軟件基金會成員。關注技術領域流計算和時序數據存儲。