硬核”實戰分享:企業微服務架構設計及實施的六大難點剖析
前言
現如今不管是傳統企業還是互聯網公司都在談論微服務,微服務架構已經成為了互聯網的熱門話題,同時,微服務的開發框架比如Dubbo、SpringCloud等也是在高頻迭代中,以滿足層出不窮的技術需求。當企業遇到系統性能瓶頸、項目進度推進乏力、系統運維瓶頸的時候,都會試圖把微服務當著一根救命稻草,認為只要實施微服務架構了,所有的問題都迎刃而解。然而,在實施微服務過程中出現的各種各樣問題如何優雅的去解決呢?本文接下來將介紹如何以“硬核”的方式去解決微服務改造過程中遇到的難點問題。
一、服務拆分粒度問題
服務到底怎么拆分合適
在微服務架構中“服務”的定義是指分布式架構下的基礎單元,包含了一組特定的功能。服務拆分是單體應用轉化成微服務架構的第一步,服務拆分是否合理直接影響到微服務架構的復雜性、穩定性以及可擴展性。服務拆分過小,會導致不必要的分布式事務產生,而且整個調用鏈過程也會變長,反之,如果服務拆分過大,會逐步演變為單體應用,不能發揮微服務的優勢。判斷一個服務拆分的好壞,就看微服務拆分完成后是否具備服務的自治原則,如果把復雜單體應用改造成一個一個松耦合式微服務,那么按照業務功能分解模式進行分解是最簡單的,只需把業務功能相似的模塊聚集在一起。比如:
- 用戶管理:管理用戶相關的信息,例如注冊、修改、注銷或查詢、統計等。
- 商品管理:管理商品的相關信息。
業務功能分解模式另外的優勢在于在初級階段服務拆分不會太小,等到業務發展起來后可以再根據子域方式來拆分,把獨立的服務再拆分成更小的服務,最后到接口級別服務。
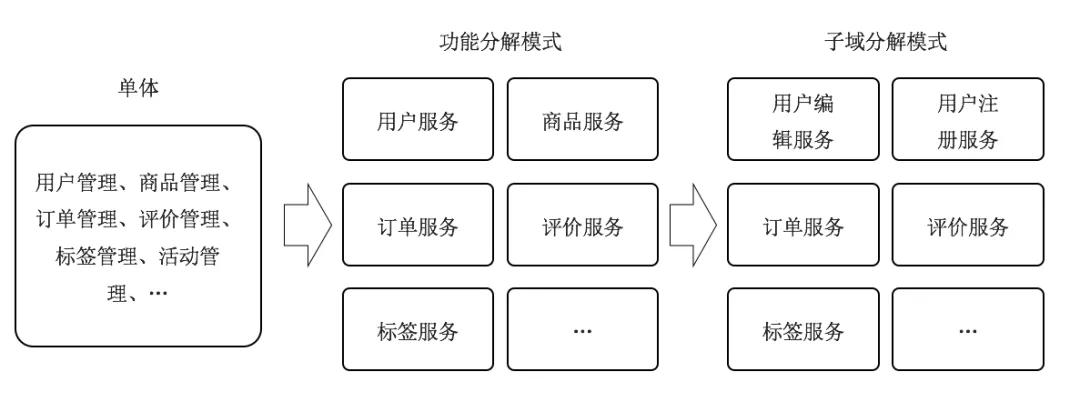
以用戶管理舉例,在初始階段的做服務拆分的時候,把用戶管理拆分為用戶服務,且具備了用戶的增刪改查功能,在互聯網中流量獲客是最貴的,運營團隊通過互聯網投放廣告獲客,用戶在廣告頁上填寫手機號碼執行注冊過程,如果此時注冊失敗或者注冊過程響應時間過長,那么這個客戶就可能流失了,但是廣告的點擊費用產生了,無形中形成了資源的浪費。當用戶規模上升之后需要對增刪改查功能做優先級劃分,所以此時需要按方法維度來拆分服務,把用戶服務拆分為用戶注冊服務(只有注冊功能),用戶基礎服務(修改、查詢用戶信息)。
哪些功能需要被拆分成服務
無論是單體應用重構為微服務架構,還是在微服務架構體系下有新增需求,都會面臨這些功能或者新增需求是否需要被拆分為服務。雖然沒有相關規定,但是可以遵循服務拆分的方法論:當一塊業務不依賴或極少依賴其它服務,有獨立的業務語義,為超過 2 個或以上的其他服務或客戶端提供數據,應該被拆分成一個獨立的服務模,而且拆分的服務要具備高內聚低耦合。所謂的高內聚是指一個組件中各個元素互相依賴的程度,是衡量某個模塊或者類中各個代碼片段之間關聯強度的標準,比如用戶服務,只會提供用戶相關的增刪改查信息,假如還關聯了用戶訂單相關的信息,那就說明這個功能不是高內聚的功能,拆分的不好。
低耦合是指系統中每個組件很少知道或者不知道其他獨立組件的定義,其中的組件可以被其他提供相同功能的組件替代。
二、緩存到底怎么用才更有效
緩存需要在哪層增加
微服務架構下,原本單體應用被劃分為聚合層和原子服務層,每一層所負責的功能各不相同。
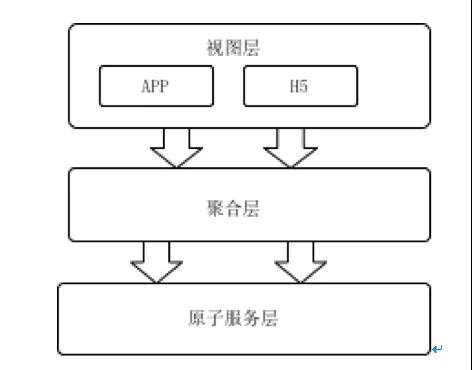
1、聚合層:收到終端請求后,聚合多個原子服務數據,按接口要求把聚合后的數據返回給終端,需要注意點是聚合層不會和數據庫交互;
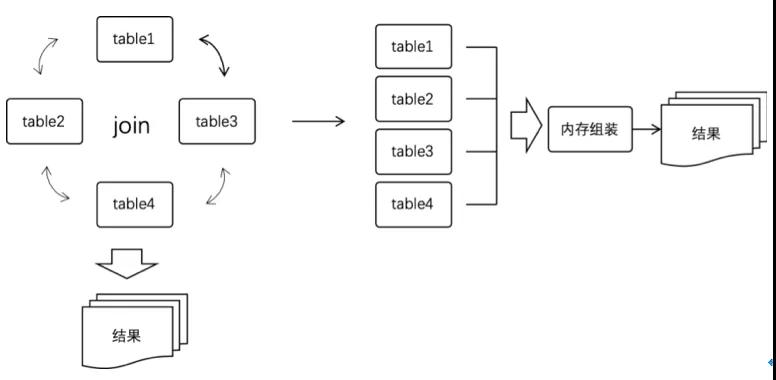
2、原子服層:數據庫交互層,實現數據的增刪改查,結合緩存和工具保障服務的高響應;要遵循單表原則,禁止2張以上的表做join查詢,如有分庫分表,那么對外要屏蔽具體規則,提供服務接口供外部調用。
如果使用到緩存,那么到底在聚合層加還是原子層加還是其他呢?應該遵循“誰構建,誰運維”這一理念,是否使用緩存應該由對應的開發人員自行維護,也就是說聚合層和原子層都需要增加緩存。一般來說聚合層和原子層由不同的團隊開發,聚合層和業務端比較貼近,需要了解業務流程更好的服務業務,和App端交互非常多,重點是合理設計的前后端接口,減少App和后端交互次數。原子服務則是關注性能,屏蔽數據庫操作,屏蔽分庫分表等操作。在聚合層推薦使用多級緩存,即本地緩存+分布式緩存,本地緩存不做緩存數據的變更,使用TTL自動過期時間來自動更新緩存內的數據。
緩存使用過程中不可避免的問題
在使用緩存的時候不可避免的會遇到緩存穿透、緩存擊穿、緩存雪崩等場景,針對每種場景的時候需要使用不同的應對策略,從而保障系統的高可用性。
1、緩存穿透:是指查詢一個一定不存在緩存key,由于緩存是未命中的時候需要從數據庫查詢,正常情況下查不到數據則不寫入緩存,就會導致這個不存在的數據每次請求都要到數據庫去查詢,造成緩存穿透,有2個方案可以解決緩存穿透:
1) 可以使用布隆過濾器方案,系統啟動的時候將所已存在的數據哈希到一個足夠大的bitmap中,當一個一定不存在的數據請求的時候,會被這個bitmap攔截掉,從而避免了對底層數據庫的查詢壓力。
- @Component
- public class BloomFilterCache {
- public static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000);
- @PostConstruct
- public void init(){
- List<Integer> list=Lists.newArrayList(); //初始化加載所有的需要被緩存的數據ID
- list.forEach(id ->bloomFilter.put(id));
- }
- public boolean addKey(Integer key){
- return bloomFilter.put(key);
- }
- public boolean isCached(Integer key){
- return bloomFilter.mightContain(key);
- }
- }
這里的BloomFilter選用guava提供的第三方包,服務啟動的時候,init方法會加載所有可以被緩存的數據,把id都放入boolmFilter中,當有新增數據的時候,執行addKey把新增的數據放入BoolmFilter過濾器中。
當在需要使用緩存的地方先調用isCached方法,如果返回true表示正常請求,否則拒絕。
2) 返回空值:如果一個查詢請求查詢數據庫后返回的數據為空(不管是數據不存在,還是系統故障),仍然把這個空結果進行緩存,但它的過期時間會很短,比如1分鐘,但是這種方法解決不夠徹底。
2、緩存擊穿:緩存key在某個時間點過期的時候,剛好在這個時間點對這個Key有大量的并發請求過來,請求命中緩存失敗后會通過DB加載數據并回寫到緩存,這個時候大并發的請求可能會瞬間把后端DB壓垮,解決方案也很簡單通過加鎖的方式讀取數據,同時寫入緩存。
- Object [] objects={0,1,2,3,4,5,6,7,8,9};
- public List<String> getData(Integer id) throws InterruptedException {
- List<String> result = new ArrayList<String>();
- result = getDataFromCache(id);
- if (result.isEmpty()) {
- int objLength= objects.length;
- synchronized (objects[id% objects.length]) {
- result = getDataFromDB(id);
- setDataToCache(result);
- }
- }
- return result;
- }
這里加鎖的方法使用的是Object數組,是希望因不同的id不會因為從數據庫加載數據被阻塞,例如id=1、id=2、id=3的key同時在緩存中消失,微服務路由策略剛好都把這些請求都路由到同一臺機器上,假設查詢DB需要50毫秒,如果僅使用synchronized(object){……}則id=3的請求會被阻塞,需要等等150毫秒才能返回結果,但是使用上述方法則只需要50毫秒出結果。其中objects數據的大小可以根據DB能承載的并發量以及原子服務數量綜合考慮。
3、緩存雪崩:是指在設置緩存時使用了相同的過期時間,導致緩存在某一時刻同時失效,所有的查詢都請求到數據庫上,導致應用系統產生各種故障,這樣情況稱之為緩存雪崩,可以通過限流的方式來限制請求數據庫的次數。
三、串行化并行解決效率問題
一個應用功能被拆分成多個服務之后,原本調用一個接口就能完成的功能如今變成需要調用多個服務,如果按順序逐個調用的話,使用微服務改造后的接口會比原始接口響應時間更長,因此要把原本串行調用的服務修改為并行調用,同時原本通過SQL的join多表聯合查詢操作變成單表操作,然后在聚合層的內存中做拼接。
例如接口A,需要調用S1(耗時200毫秒),S2(耗時180毫秒),S3(耗時320毫秒)這3個接口,使用串行調用方式,那么接口A累計耗時=SUM(S1+S2+S3)=700毫秒。為了讓響應時間更短,就需要把這些串行調用的方式更改為并行調用的方式,并行調用方式調用接口A累計耗時為MAX(S1,S2,S3)=320毫秒。可以使用jdk8提供的CompletableFuture方法,偽代碼如下:
- CompletableFuture<DTOS1> futureS1 = CompletableFuture.supplyAsync(() -> {
- S1接口 },executor);
- CompletableFuture<DTOS2> futureS2 = CompletableFuture.supplyAsync(() -> {
- S2接口 },executor);
- CompletableFuture<DTOS3> futureS3 = CompletableFuture.supplyAsync(() -> {
- S3接口 },executor);
- CompletableFuture.allOf(futureS1, futureS2, futureS3).get(500, TimeUnit.MILLISECONDS);
此時就把原本串聯調用的服務變成并行調用,節約了接口請求時間,但卻引發一個新的問題,內部接口調用換成網絡RPC調用,會導致服務調用的不確定性,引起接口不穩定。
四、服務的熔斷降級處理
把內部接口調用替換為RPC調用,在調用過程中可能會出現網絡抖動、網絡異常,當服務提供方(Provide)變得不可用或者響應慢時,也會影響到服務調用方的服務性能,甚至可能會使得服務調用方占滿整個線程池,導致這個應用上其它的服務也受影響,從而引發更嚴重的雪崩效應。因此需要梳理所有服務提供者并把服務分級,同時引入了Hystrix或則Sentinel做服務熔斷和降級處理,目的如下:
降級目的:業務高峰期的生活,去掉非核心鏈路,保障主流程正常運行;
熔斷目的:防止應用程序不斷地嘗試可能超時或者失敗的服務,能達到應用程序正常執行而不需要等待下游修正服務。
熔斷器需要做以下設置:
設置錯誤率:可以設置每個服務錯誤率到達制定范圍后開始熔斷或降級;
具備人工干預:可以人工手動干預,主動觸發降級服務;
設置時間窗口:可配置化來設置熔斷或者降級觸發的統計時間窗口;
具備主動告警:當接口熔斷之后,需要主動觸發短信告知當前熔斷的接口信息;
以Sentinel為例,它提供了很多微服務框架的適配器,如果是Dubbo應用,提供了SentinelDubboConsumerFilter和SentinelDubboProviderFilter等Filter,企業零開發即可快速接入Sentinel完成對服務的保護,只需要在工程的pom.xml里面引入
- <dependency>
- <groupId>com.alibaba.csp</groupId>
- <artifactId>sentinel-apache-dubbo-adapter</artifactId>
- <version>1.7.2</version>
- </dependency>
如果是Spring Cloud,只需要在pom.xml里面引入以下內容即可快速接入
- <dependency>
- <groupId>com.alibaba.cloud</groupId>
- <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
- </dependency>
這里需要注意2點:
1) 要先梳理服務做好服務分級,降級、熔斷是針對非核心流程,如核心流程處理能力不滿足業務需要,則需要擴充或者優化核心流程;
2) 降級是動態配置后立即生效,而非手動去修改源代碼后再發布服務服務;
五、接口冪等處理
在分布式環境中,網絡環境比較復雜,如前端操作抖動、APP自動重試、網絡故障、消息重復、響應速度慢等原因,對接口的重復調用概率會比單體應用環境下更大,所以說重復消息在分布式環境中很難避免,所以在分布式架構中,要求所有的調用過程必須具備冪等性,即用戶對于同一操作發起的一次請求或者多次請求的結果是一致的,不會因為多次點擊而產生了副作用。接口的冪等性實際上就是接口可重復調用,在調用方多次調用的情況下,接口最終得到的結果是一致的。冪等的處理方案有多種,比如冪等表、樂觀鎖、token令牌,但是在實際過程中并不是每個場景都需要做冪等處理。例如有些場景自身具備冪等性
- select * from user_order where order_num=?
無論查詢多次其結果不會因為查詢次數導致結果有影響,所以select的操作天然具備冪等性,無需處理。
- update sys_user set user_state=1 where user_id=?
直接賦值型的update語句操作多次不會影響結果,所以此類update操作也天然具備冪等性。
但是當以下語句多次調用的時候會引起數據不一致,因此需要對冪等處理
- insert into user_order(id,order_num,user_id) values(?,?,?)
- update user_point set point = score +20 where user_id=?
唯一主鍵機制:這個機制是利用了數據庫的主鍵唯一約束的特性,解決了在insert場景時冪等問題。但主鍵的要求不是自增的主鍵,而是需要業務生成全局唯一的主鍵,如果有分庫分表了那么唯一主鍵機制就沒有效果了。
冪等表:利用數據庫唯一索引做防重處理,當第一次插入是沒有問題的,第二次在進行插入會因為唯一索引報錯,從而達到攔截的目的。
樂觀鎖:通過version來判斷當前請求的數據是否有變動,例如
- update user_point set point = point + 20, version = version + 1 where user_id=100 and version=20
Token令牌:為防止重復提交, 為每次請求生成請求唯一鍵,服務端對每個唯一鍵進行生命周期管控,規定時間內只允許一次請求,非第一次請求都屬于重復提交,后端要給出單獨生成token令牌接口,前端要在每次調用時候先獲取token令牌。
無論是唯一主鍵機制還是冪等表都存在唯一鍵的要求,以電商下單場景為例,看看如何來做冪等處理。例如用戶在App下單后,下單請求首先通過Nginx反向代理,轉發到聚合層,聚合層再調用原子服務,其中訂單號為全局唯一。這種場景訂單號誰來生成,如何來保障用戶下單的冪等性呢?
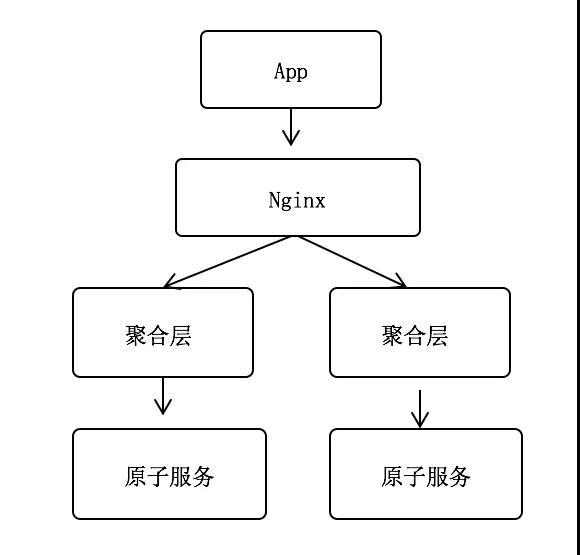
- 假設原子服務生成訂單號:如果聚合層第一次調用原子服務超時了,此時原子服務已經生成了訂單號為A并寫入訂單表。因第一次超時,聚合層會再次發送請求調用原子服務,此時原子服務再生成訂單號B并寫入訂單表,導致一次下單生成2份訂單數據。
- 假設聚合層生成訂單號:如果訂單號是聚合層生成,理論上多次調用原子層都是同一個訂單號,具備冪等性,但是如何Nginx重復調用聚合層的話,仍然會導致一次申請多個訂單的情況。
- 假設Nginx生成訂單號:如果Nginx生成訂單號,理論上多次調用原聚合層都是同一個訂單號,具備冪等性,但是如何App端重復調用Nginx的話,任然會導致一次申請多個訂單的情況。
- 假設App生成訂單號:最后只能是App針對每一次下單生成一個訂單號,并和請求報文一起發送給后端。因為每個App根據規則生成訂單號可能會導致訂單號重復。
比較優雅的解決方案是App在下單的時候生成以一串針對該用戶唯一的序列(sequenceId)和下單請求一起發送到后端,聚合層首先判斷sequenceId是否存在,如存在則直接返回成功,否則生成訂單號并把sequenceId寫入緩存,然后調用原子服務插入訂單數據,如果原子服務寫入訂單成功則刪除緩存中的sequenceId。通過這里例子可以看到,在微服務中解決任何問題不能僅看一小塊,需要從全局角度來看待問題。
六、如何保障數據一致性
因事物所具備的四大特性ACID(原子性、一致性、隔離性、持久性),使用事物是保障數據一致性的有效手段。例如用戶在平臺上下單訂購某種業務的時候,需要涉及到訂單服務,積分服務,在單體模式下這種業務非常容易實現,通過事務即可完成,偽代碼如下:
- @Transaction
- public Boolean createOrder(OrderDTO order){
- 創建訂單
- 增加積分
- }
然而在微服務的情況下,原本通過簡單事務處理的卻變得非常復雜,訂單、積分被拆分為不同的服務部署在獨立的服務器上,并且數據存在在不同的數據庫中,傳統的事物處理模式已經失效,這里又引出了分布式框架下數據的一致性要求。在談數據一致性要求的時候有2個非常重要的理論即CAP定理和Base理論:
1、CAP定理:C表示一致性,也就是所有用戶看到的數據是一樣的,A表示可用性,是指總能找到一個可用的數據副本,P表示分區容錯性,能夠容忍網絡中斷等故障。
2、BASE理論:BA指的是基本業務可用性,支持分區失敗,當分布式系統出現故障的時候,允許損失一部分可用性,例如在電商大促的時候,對一些非核心鏈路的功能進行降級處理來提高系統的可用性,S表示柔性狀態,允許系統存在中間狀態,這個中間狀態不會影響系統整體可用性。比如,數據庫讀寫分離,寫庫同步到讀庫(主庫同步到從庫)會有一個延時,E表示最終一致性,數據最終是一致的,例如主從同步雖然有短暫的數據不一致情況,但是最終數據還是一致的。
分布式系統中最重要的是讓系統穩定并滿足業務需求,而不是追求高度抽象,絕對的系統特性。針對分布式事物目前開源方案有阿里巴巴開源的無侵入分布式解決方案Seata,它為用戶提供了 AT、TCC、SAGA 和 XA 事務模式,為用戶打造一站式的分布式解決方案,例如最簡單的AT模式,特點就是對業務無入侵式,分二階段提交,通過簡單配置并在接口上增加@GlobalTransactional即可完成分布式事物,但是在性能上有衰減。在實際中可以通過本地事務和發送MQ消息這種柔性事物方式來解決分布式事物所面臨的問題,既能保障服務的穩定性又能保障調用效率的高效性,在MQ可以使用Apache的RocketMQ所提供的事物消息和本地事物表結合。其中以下概念需要理解下:
1、半事務消息:暫不能投遞的消息,發送方已經成功地將消息發送到了消息隊列服務端,但是服務端未收到生產者對該消息的二次確認,此時該消息被標記成“暫不能投遞”狀態,處于該種狀態下的消息即半事務消息。
2、消息回查:由于網絡閃斷、生產者應用重啟等原因,導致某條事務消息的二次確認丟失,消息隊列服務端通過掃描發現某條消息長期處于“半事務消息”時,需要主動向消息生產者詢問該消息的最終狀態(Commit 或是 Rollback),該詢問過程即消息回查。
整個流程如下:聚合服務收到創建訂單請求的時候,會發送一個事務性的MQ消息,注意這里的消息只是發送到消息隊列,并沒有收到生產者的確認,因此消息處于半事物狀態,消息隊列收到消息后會回調生產者,這個時候就可以完成本地事物(寫訂單表,寫日志表),如果事物提交成功,則把發送確認消息給MQ。針對下單這種情況,必須要考慮以下幾種異常:
1、 App調用下單接口,此時發送MQ消息異常則直接返回下單失敗,App需要重新點擊下單
2、 MQ回調生產者的時候,生產者開始寫入訂單數據,此時事物發生異常,則返回UNKNOW狀態,不要返回ROLLBACK_MESSAGE,因為App已經收到下單成功的通知了,不允許再出現下單失敗的情況;
3、 MQ長時間(默認1分鐘,時間可調整)沒有收到生產者確認提交消息,會進行消息的回查
相關代碼具體如下:
- public class TransactionOrderProducer {
- public void init(){
- producer = new TransactionMQProducer(group);
- producer.setTransactionListener(orderTransactionListener);
- this.start();
- }
- //事務消息發送
- public TransactionSendResult send(String data, String topic) throws MQClientException {
- Message message = new Message(topic,data.getBytes());
- return this.producer.sendMessageInTransaction(message, null);
- }
- }
當消息隊列收到消息后,會回調orderTransactionListener的executeLocalTransaction方法,在這個方法里面createOrder會執行訂單入庫的操作,同時會在日志表總記錄一條數據。
- public class OrderTransactionListener implements TransactionListener {
- @Override
- public LocalTransactionState executeLocalTransaction(Message message, Object o) {
- LocalTransactionState state;
- try{
- String order = new String(message.getBody());
- orderService.createOrder(order,message.getTransactionId());
- state = LocalTransactionState.COMMIT_MESSAGE;
- }catch (Exception e){
- state = LocalTransactionState.UNKNOW;
- }
- return state;
- }
- @Override
- public LocalTransactionState checkLocalTransaction(MessageExt messageExt) {
- LocalTransactionState state;
- String transactionId = messageExt.getTransactionId();
- if (transactionService.check(transactionId)){
- state = LocalTransactionState.COMMIT_MESSAGE;
- }else {
- String body = new String(messageExt.getBody());
- OrderDTO order = JSONObject.parseObject(body, OrderDTO.class);
- try {
- orderService.createOrder(order, messageExt.getTransactionId());
- }catch (Exception e){
- return LocalTransactionState.UNKNOW;
- }
- state = LocalTransactionState.COMMIT_MESSAGE;
- }
- return state;
- }
- }
積分服務只需要消費普通MQ的消息即可完成分布式事物,在這里把原先要求一致性的事物寫入訂單和增加積分轉換為先寫入訂單,積分服務消費MQ來增加積分,達到柔性事物的機制。
結語
以上六種常見問題是在實施微服務中最容易遇到的問題,當然解決辦法也是因人而異,但是遇到問題的時候不能僅僅去看一個點,比如冪等問題,如果僅看一個技術點的話,很難優雅的處理冪等問題。總的來說實施微服務不難,因為已經有很多成功案例可以借鑒,遇到問題的時候多去想,從多個角度去考慮,從全局去考慮。
潘志偉,某金融企業,擁有十多年從業經驗,精通微服務架構,精通大數據,擁有億級用戶平臺架構經驗,萬級并發的API網關經驗。