













如何突破Decoder性能瓶頸?揭秘FasterTransformer的原理與應用
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
4月9日,英偉達x量子位分享了一期nlp線上課程,來自NVIDIA的GPU計算專家、FasterTransformer 2.0開發者之一的薛博陽老師,與數百位開發者共同探討了:
- FasterTransformer 2.0 新增功能介紹
- 如何針對Decoder和Decoding進行優化
- 如何使用Decoder和Decoding
- Decoder和Decoding能夠帶來什么樣的加速效果
應讀者要求,我們將分享內容整理出來,與大家一起學習。文末附有本次直播回放、PPT鏈接,大家也可直接觀看。
以下為本次分享的內容整理:
大家好,今天為大家介紹的是FasterTransformer 2.0的原理與應用。
什么是FasterTransformer?
首先,參加本期直播的朋友對Transformer架構應該都有了一定了解。這個架構是在“Attention is All You Need”這篇論文中提出的。在BERT Encoder中使用了大量Transformer,效果很好。因此,Transformer已成為 NLP 領域中非常熱門的深度學習網絡架構。
但是,Transformer計算量通常是非常大的。因此,Transformer的時延往往難以滿足實際應用的需求。
△Attention is All You Need截圖
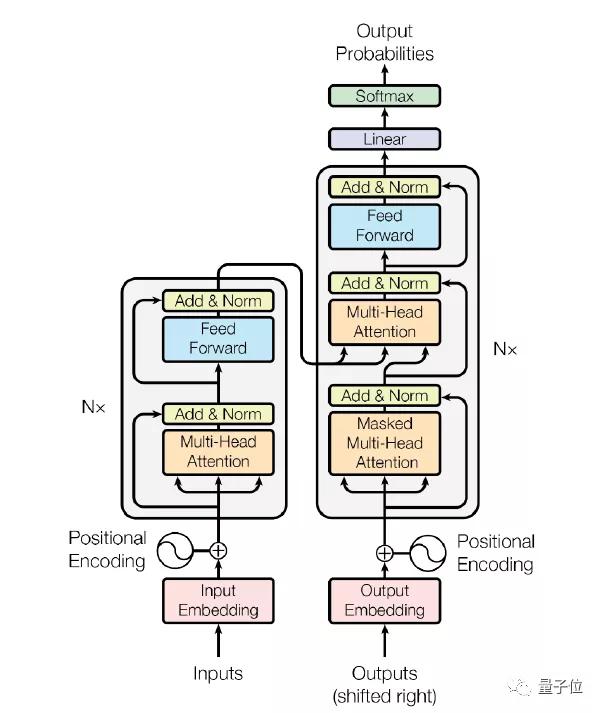
Transformer架構可以應用于Encoder或Decoder上。在Encoder中,Transformer包含1個multi-head attention和1個feed forward網絡,在Decoder中,包含2個multi-head attention和1個feed forward網絡。
其中,純Encoder架構在目前的很多應用中都有很好的表現,比如Q&A系統、廣告推薦系統等,因此,針對Encoder的優化是非常有必要的。
而在一些場景中,如翻譯場景,我們需要Encoder和Decoder架構。在這種架構下,Decoder消耗的時間占比是非常高的,可能達到90%以上,是推理的主要瓶頸。因此,針對Decoder的優化也是一項重要的工作,能帶來明顯的加速效果。
實際應用中,FasterTransformer 1.0版本針對BERT中的Encoder為目標做了很多優化和加速。在2.0版本中,則主要新增了針對Decoder的優化,其優越的性能將助力于翻譯、對話機器人、文字補全修正等多種生成式的場景。

上表比較了Encoder和Decoder計算量的不同。當我們需要編解碼一個句子的時候,Encoder可以同時編碼很多個字,甚至可以直接編碼一個句子。
但是Decoder是一個解碼的過程,每次只能解碼一個字,因此,解碼一個句子時我們需要多次Decoder的forward,對GPU更不友善。
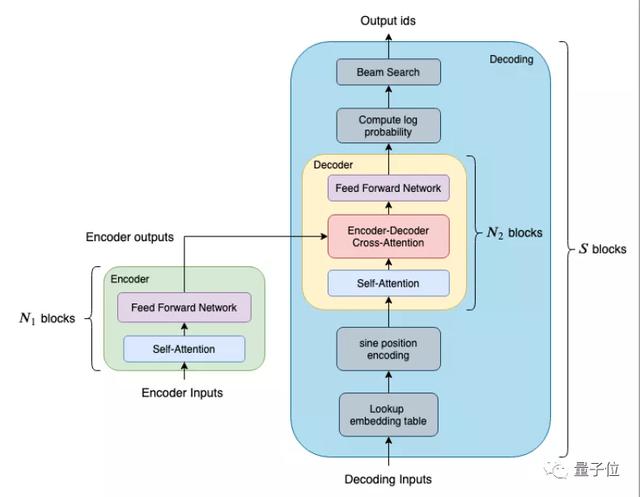
△Faster Transformer框架
上圖列出了FasterTransformer中針對BERT優化的模塊。在編碼方面,以BERT為基準,提供了一個單層的、等價于BERT Transformer 的模塊,供使用者做調用。當我們需要多層的Transformer時,只需調用多次Encoder即可。
解碼方面更為復雜,為了兼顧靈活性與效率,我們提供兩個不同大小和效果的模塊:
Decoder(黃色區塊) 由單層的 Transformer layer 組成,它包含兩個attention和一個feed forward 網絡;而Decoding(藍色區塊)除了包含多層的 Transformer layer 之外,還包括了其他函數,例如 embedding_lookup、beam search、position Encoding 等等。
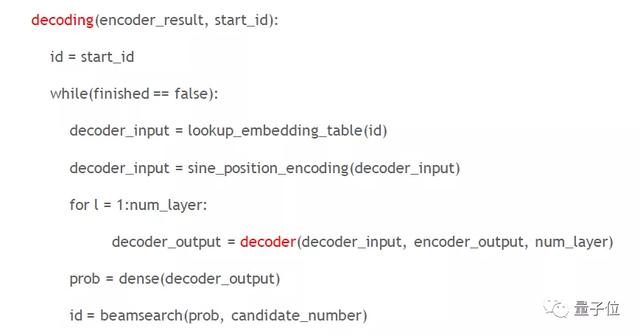
我們用一個簡單的虛擬碼展示Decoder和Decoding的區別。
在Decoding中通常有兩個終止條件,一是是否達到預先設定的最大的sequence length,第二個條件是所有的句子是否都已經翻譯完畢,未終止時會不斷循環。
以句子長度為128的句子翻譯場景為例,若其 Decoder 是由6層的 Transformer layer 組成的,總共需要調用 128x6=768 次的Decoder;如果是使用 Decoding 的話,則只需要調用一次Decoding,因此Decoding的推理效率更高。
小結

首先,FasterTransformer提供了高度優化過的Transformer layer:在Encoder方面是基于BERT實現的;在Decoder方面基于OpenNMT-TensorFlow開源的庫做為標準;Decoding包含了翻譯的整個流程,也是基于OpenNMT-TensorFlow。
其次,FasterTransformer 2.0的底層由CUDA和cuBLAS實現,支持FP16 和 FP32 兩種計算模式,目前提供C++ API和TF OP。
現在,FasterTransformer 2.0已經開源,大家可以在DeepLearningExamples/FasterTransformer/v2 at master · NVIDIA/DeepLearningExamples · GitHub獲取全部源代碼。
如何進行優化?
先以Encoder為例。
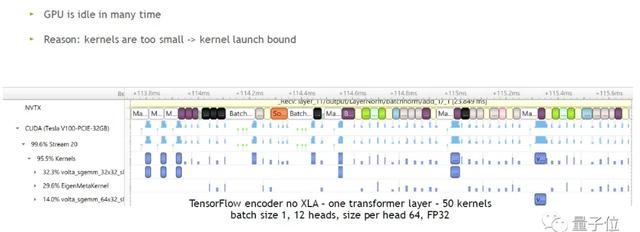
△TF Encoder Transformer layer
參數:no XLA,batch size 1,12 heads,size per head 64,FP 32
圖中藍色方塊表示GPU在實際運行,空白的表示GPU在閑置,因此GPU在很多時間是閑置狀態。造成GPU閑置的原因是kernels太小,GPU要不斷閑置以等待CPU啟動kernel的時間,這也稱為kernel launch bound問題。
如何解決這個問題?

我們嘗試開啟TF的XLA,其他參數不變。圖中我們看到,從原本計算1層Transformer layer需要50個kernel縮減到24個左右。大部分kernel變得比較寬,雖有加速,但是閑置的時間還是比較多。
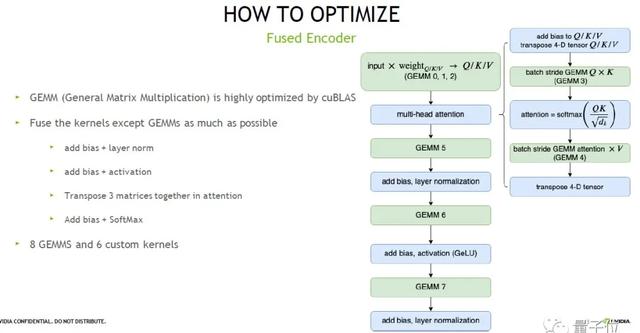
因此,我們提出FasterTransformer針對Encoder進行優化。
首先,我們把矩陣計算部分挑選出來,用NVIDIA高度優化的庫cuBLAS 來計算,此外的部分,我們把能融合的kernel都盡可能融合起來。
最終的結果如上圖右邊,經過整體的優化后,我們只需要8個矩陣計算加6個kernel就可以完成單層Transformer layer計算,也就是說所需kernel從24個減少到14個。
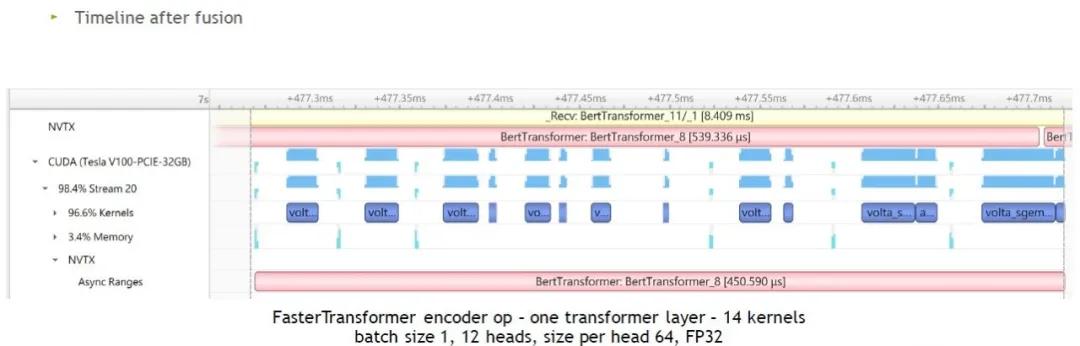
我們可以看到,優化后每一個 kernel 都相對比較大,時間占比小的kernel也減少了。但還是有很多空白的片段。

我們直接調用C++ API,如圖,GPU閑置的時間幾乎沒有了。因此,小batch size情況下,我們推薦使用C++ API以獲得更快的速度。當batch size比較大時,GPU閑置時間會比較少。
接下來我們看下Decoder。
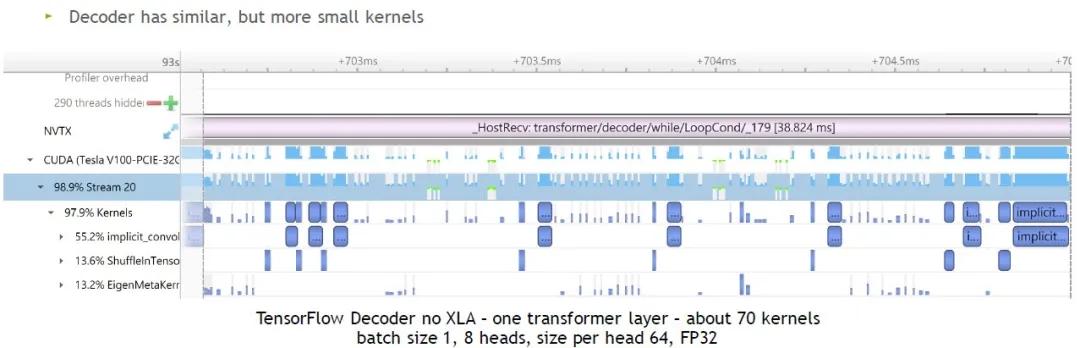
參數:no XLA,batch size 1,8 heads,size per head 64,FP32
經過統計,TF需要使用70個左右kernel來計算1層Transformer layer。直觀來看,非常小、時間占比非常短的kernel更多。因此,batch size比較小的情況下,優化效果會更明顯。
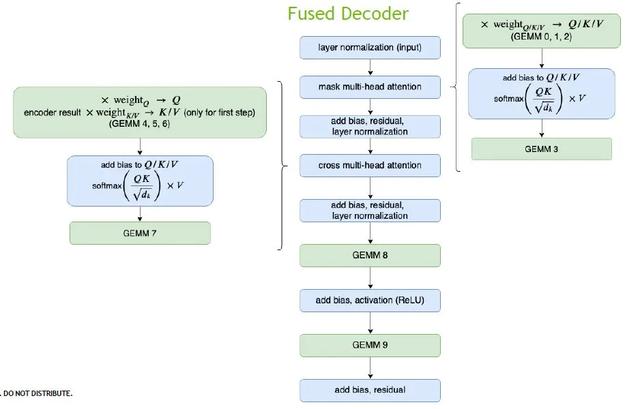
Decoder的優化同上述Encoder,特別之處是,Decoder里面的矩陣計算量非常少,因此我們把整個multi-head attention以一個kernel來完成。經過優化之后,原本需要70個kernel才能完成的計算,只需要使用16個kernel就能夠完成。
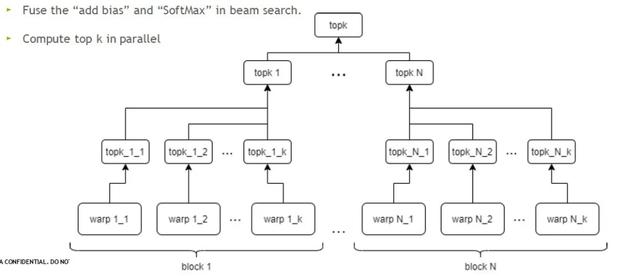
在更大的Decoding模塊中,另一個時間占比較多的kernel是beam search,這里我們針對top k做出優化。在GPU中可以同時執行多個block和多個warp,并行運算,大大節省時間。

△更多優化細節
如何使用FasterTransformer?
大家可以在DeepLearningExamples/FasterTransformer/v2 at master · NVIDIA/DeepLearningExamples · GitHub根目錄下找到對應資料:

針對 Decoder 和 Decoding,FasterTransformer 分別提供了 C++ 和 TensorFlow OP 這兩種接口。
C++接口
首先創建一個Eecoder,超參數如圖:

其次,設定訓練好的模型權重;
設置好后,直接調用forward即可。
TF OP接口
首先,我們需要先載入OP。這里以Decoder為例,會自動創建TF需要使用的庫,調用接口時先導入.so文件(圖中已標紅):

然后調用Decoder,放入input、權重、超參數,然后針對out put 做Session run。
這里需要注意的是,參數里有一個虛擬的輸入 (pseudo input)。這個輸入是為了避免 TensorFlow 的 decoder 和 FasterTransformer Decoder 發生并行,因為我們發現并行執行時,Decoder中的memory可能會被污染。實際應用的時候可以將這個輸入拿掉。
優化效果
最后我們來看下優化的效果如何。首先測試環境設置:

使用的GPU是NVIDIA的Tesla T4和V100。
Encoder模塊在Tesla V100的結果
超參數設置:12 layers,32 sequence length,12 heads,64 size per head(BERT base),under FP 16
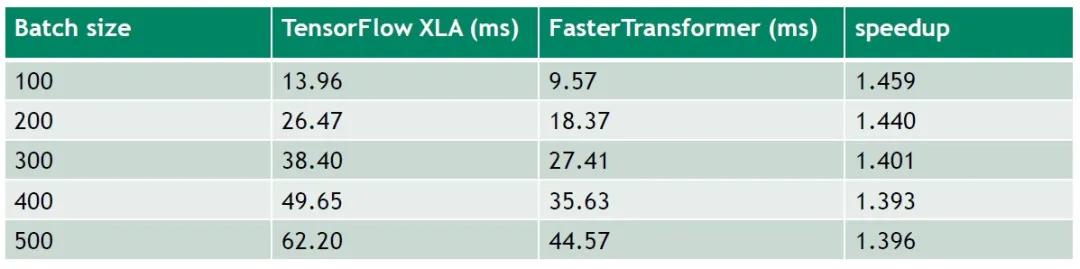
結果如上圖,batch size從100逐步增加到500的過程中,FasterTransformer對比TF開啟XLA,大概可以提供1.4倍的加速。
Decoder和Decoding模塊在Tesla T4的結果
超參數設置:Batch size 1,beam width 4,8 heads,64 size per head,6 layers,vocabulary size 30000,FP 32
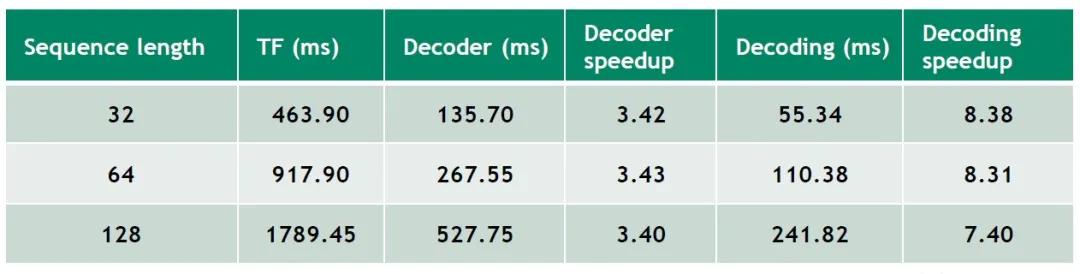
結果如上圖,不同的sequence length下,相比于TF,FasterTransformer Decoder可以帶來3.4倍左右的加速效果,Decoding可以帶來7-8倍的加速,效率更高。
超參數設置:Batch size 256,sequence length 32,beam width 4,8 heads,64 size per head,6 layers,vocabulary size 30000

結果如上圖,把batch size固定在較高值時,不同的FP下,FasterTransformer Decoder和Decoding也帶來一定的加速效果。



















