打破存儲性能瓶頸,實現(xiàn)AI應用的騰飛
經(jīng)典的“木桶理論”告訴我們,決定桶能裝多少水,是由最低的那塊木板來決定的。
同樣目前數(shù)據(jù)在整個IT系統(tǒng)中的運行過程,也有一個瓶頸一直存在,就是存儲介質(zhì)的性能。
互聯(lián)網(wǎng)催生了海量應用,海量應用誕生了海量的不同種類的數(shù)據(jù)。要讓多元的數(shù)據(jù)發(fā)揮價值,不僅需要更強的處理器,更快的網(wǎng)絡還有最終數(shù)據(jù)存儲的讀寫能力。
今天算力發(fā)展喜人,多元的數(shù)據(jù),催生著多元的算力的出現(xiàn),通用算力CPU、人工智能算力GPU、TPU、NPU等處理器的蓬勃發(fā)展,X86、ARM架構(gòu)等算力的架構(gòu)發(fā)展。
網(wǎng)絡技術(shù)發(fā)展喜人,移動互聯(lián)、視頻、直播等對于海量的數(shù)據(jù)傳輸需求,催生了數(shù)據(jù)中心的網(wǎng)絡帶寬100G、400G端口的發(fā)展。華為早在2018年正式發(fā)布全新400G光網(wǎng)絡商用解決方案,支撐運營商全業(yè)務場景的400G網(wǎng)絡快速部署。
同樣存儲技術(shù)在性能方面的發(fā)展并不喜人,海量的數(shù)據(jù)催生了存儲技術(shù)的發(fā)展,介質(zhì)上從磁盤到NAND、3D NAND的固態(tài)盤,接口從SAS、SATA、PCIE、NVME傳輸協(xié)議的升級。但是我們看到存儲在單位容量增長的速度,遠遠大于單位存儲傳輸性能的速度。數(shù)據(jù)在存儲介質(zhì)和外界交換的傳輸速度成為整個IT系統(tǒng)的瓶頸。
在積極突破存儲瓶頸的方向上,目前提出有三種方法,一、直接采用全新的架構(gòu)和技術(shù)重新定義存儲技術(shù)。二、采用分布式存儲,讓數(shù)據(jù)分散傳輸來提升整個IT系統(tǒng)的效率。三、研發(fā)新的存儲介質(zhì),包括原子存儲技術(shù)和DNA存儲技術(shù)。
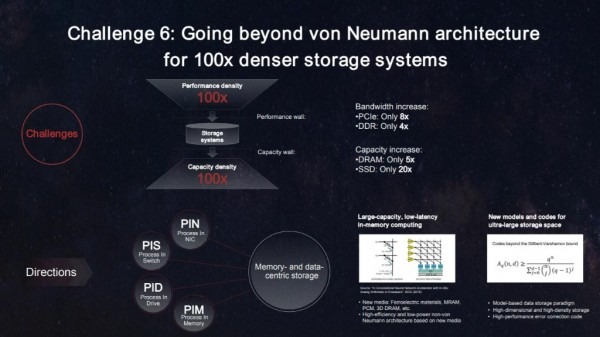
研發(fā)新的架構(gòu)和技術(shù)。在不久前的2021華為全球分析師大會,華為發(fā)布了邁向智能世界2030的九大技術(shù)挑戰(zhàn)與研究方向,其中就有針對IT架構(gòu)中最后的挑戰(zhàn),存儲性能提升給出了方向,包括構(gòu)建提升存儲性能百倍的新存儲技術(shù)研究方向。
華為希望從突破馮諾依曼架構(gòu)來提升存儲能力。目前的IT架構(gòu)基于馮諾依曼架構(gòu),數(shù)據(jù)在CPU、內(nèi)存、存儲介質(zhì)之間移動,其中任何一個環(huán)境的性能差,都會對整個系統(tǒng)帶來性能挑戰(zhàn)。
我們看到CPU的性能一直在提升,內(nèi)存的性能也在提升,網(wǎng)絡的帶寬也在提升,存儲的容量也在提升,但是存儲的性能卻一直是瓶頸,包括當前的PCIE、NVME等存儲接口的帶寬速度遠跟不上外部網(wǎng)絡的性能增長。
華為的思路是要提升存儲性能,需要突破馮諾依曼架構(gòu)的限制,從以CPU為中心,轉(zhuǎn)向以內(nèi)存為中心、以數(shù)據(jù)為中心,從搬移數(shù)據(jù)轉(zhuǎn)向搬移計算,打破性能墻。
還有一種方案提高數(shù)據(jù)存取的效率,當面臨海量數(shù)據(jù)存取的時候,用最少的存取,實現(xiàn)最大的應用。這就是是分布式存儲。
比如現(xiàn)在火熱的IPFS就是一種比較火熱的分布式存儲系統(tǒng),其核心概念是基于內(nèi)容尋址、版本化、點對點的超媒體傳輸協(xié)議。也就是數(shù)據(jù)存取直接指向資源,并確保這些數(shù)據(jù)都是來自最近的資源。而不是先找到存放的存儲介質(zhì),在調(diào)取介質(zhì)里的數(shù)據(jù)。這樣就大大減少了存儲介質(zhì)性能對于數(shù)據(jù)存取的影響。比如一個10TB的文件,可以打散分布在1000個邊緣端的存儲介質(zhì)上。而且調(diào)用的時候,不需要下載到本地,直接調(diào)用1000個邊緣端的存儲性能。從而實現(xiàn)數(shù)據(jù)的高效利用。
第三就是新的存儲介質(zhì),包括原子存儲技術(shù)和DNA存儲技術(shù),如果能夠真正研發(fā)出來,就能夠?qū)崿F(xiàn)存儲性能的千倍以上的提升,當然目前是理論階段,距離真正落地商業(yè)還有還長的距離。