我從新冠數據里學到的四個數據科學基礎知識
大數據文摘
出品來源:medium
編譯:千雪、aileen
雖然現在大家很容易獲取機器學習和數據科學的學習工具,但是除了學習如何使用工具以外,往工具里輸入數據之前如何有效地探索數據,并找出其局限性也同樣重要。
最令人驚訝的是,總有很多人經常不看數據就開始構建模型,這很明顯是一個錯誤行為。想構建一個有效的模型,就必須了解如何收集數據,以及數據之間在哪些地方存在差距。無論你是要處理Excel表格里的幾百行數據還是TB級別的圖像分類數據集,這都同樣重要。
因為數據是從現實世界中收集而來的,而現實世界充滿了怪誕奇葩的事,所以每一個現實世界的數據集也都充滿了不確定性。目前在COVID-19流行期間,人們日常關注的疫情數據就是如此:每天收集整理并修正來自全世界的數據,這并不是一件容易的事。因此,你現在看到的報告數字,就顯示出了你在其他現實世界的數據集中也能看到的差別和問題。
現在,讓我們一起來看看COVID-19的報告數據,感受一下如果不提前檢查數據就開始構建模型,我們將會出現哪些錯誤。
第1課:不同的數據收集方式會創造出并不真實的數據趨勢
COVID-19的國際報告標準是要求每個國家或地區報告醫院的每天死亡人數,這樣就可以比較出該疾病是如何影響不同的國家的。
我們來看看英國報道的每日數字:
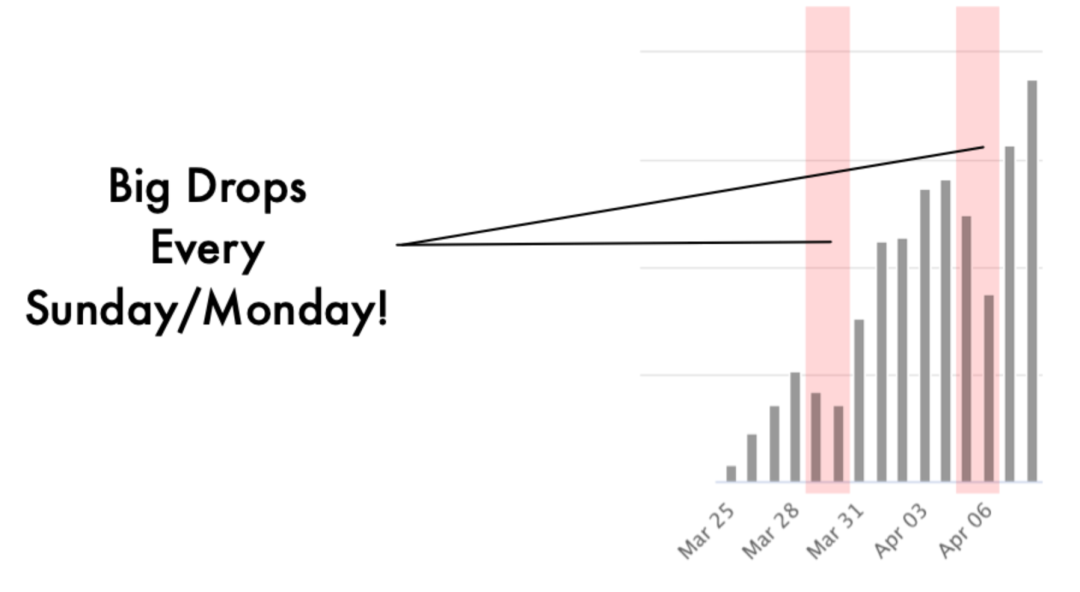
英國因COVID-19導致的每天死亡人數:每個周日/周一死亡人數都會大幅下降!
請注意,該報告的死亡人數遵循著完美的每周周期:死亡人數在每個星期之初(即周日和周一)發生顯著下降。這是一個非常有趣的發現,對模型可能會產生巨大影響。讓我們猜測一下,是否是因為那兩天人們的物資待遇或生活方式有所不同,所以才會導致不同的結果?
然而,這個每周的周期是假的,它只是一個涉及到數據如何收集和報告的人工產物。
每個醫療機構每天向中央機構報告一次死亡總數,英國報告的總死亡人數就是用這些數字的總和減去昨天的數字。
這會導致兩個明顯的問題:
- 一天的總和可能是(甚至通常是)不完整的。如果有醫療機構未能及時報告或報告不全,那么這些死亡人數就不會計入英國當天的死亡總數,而是匯總到未來一天的總數中。
- 每個醫療機構報告的死亡人數總和與英國范圍內向公眾報告的死亡人數總和之間存在1天的延遲。
那么解釋這個每周的周期就很簡單了。周末時醫院人手不夠,他們沒法及時報告自己的全部死亡人數。延遲報告就會導致周末時死亡人數下降,而周末之后死亡人數相應上升。由于報告滯后了一天,因此數據中是周日和周一顯示死亡人數下降,而不是周六和周日。
這就是數據集的常見問題——不同的數據收集方式會制造出真實數據本身并不存在的數據趨勢。再舉個例子,許多免費的圖像數據集是由攻讀博士學位的研究生創建的。因此,如果你想從網上獲取帶有汽車圖像的隨機數據集,那么你可能會獲得很多校園停車場中的小汽車圖片,而不會有很多大型卡車的圖片。但是在美國,皮卡車與小汽車的銷量卻幾乎是3比1!
第2課:一定要多多探究離群值
數據集里幾乎總是會存在離群值(也叫逸出值,是指數據中有一個或幾個數值超出了其余數值的范圍),但你絕不會希望你的數據分析里一直出現離群值,這是因為離群值可能只是簡單疏忽或異常事件發生的結果。所以,探究離群值是一件很重要的事,
這樣就可以確定在數據分析中是否應當包括它們,還是將它們排除出去。
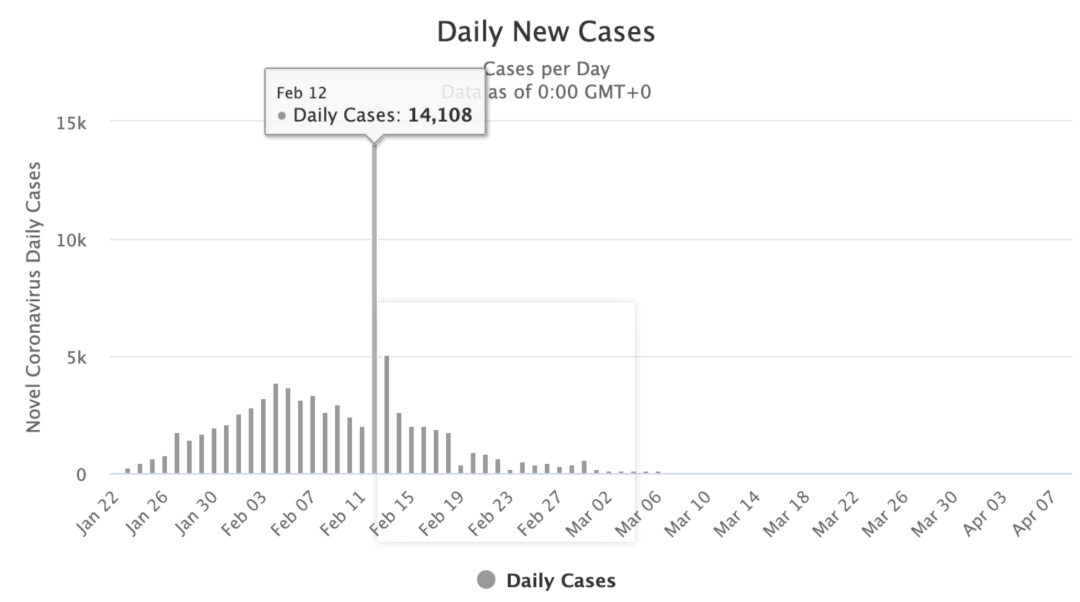
這是全球實時數據統計網站worldometers.info提供的中國COVID-19新增病例報告的比率:
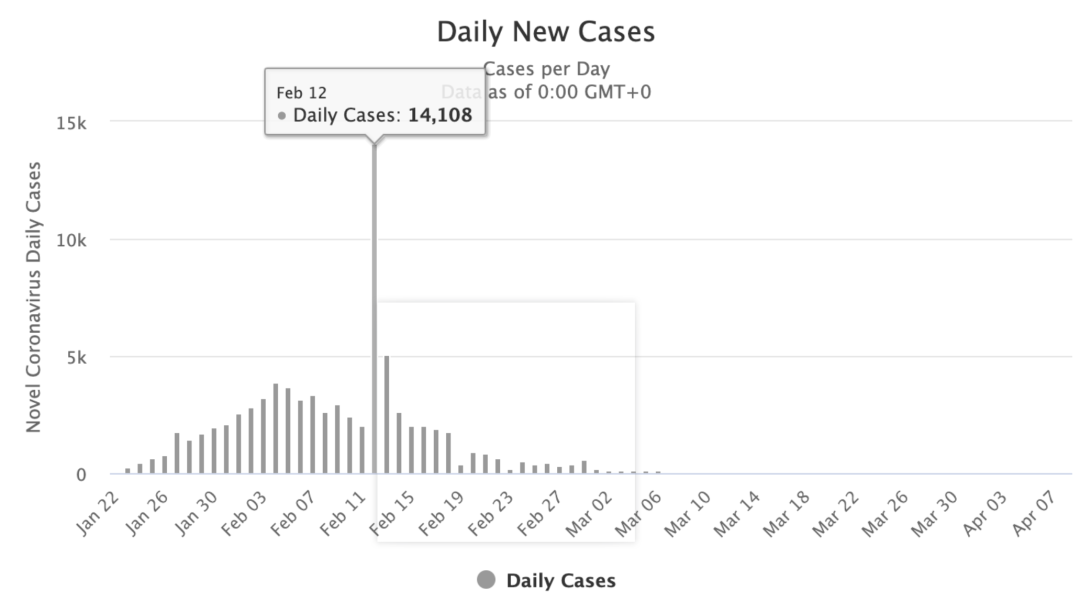
每日新增病例
2月12日有一個巨大的離群值,中國報告了14108例新增COVID病例,這一天的增加量是前一天新增病例的好幾倍。
如果你盲目地用這些數據建立模型,那么這個離群值會把整個模型的結果弄亂。相反,如果你認為這個離群值代表真實事件,則可能會誤導你以為2月12日左右發生了一些特殊情況,所以導致感染增加。
然而事實上,出現這種大幅度躍升情況的真正原因是中國于2月12日更改了報告方法。在此之前,中國僅報告由RNA病毒測試方法確認的病例。但是由于測試瓶頸,醫生同時也通過胸部X光片來檢查患者的肺部癥狀,以此篩查COVID-19病患。2月12日,中國將之前所有通過X光片確診的病例也進行了報告,這才導致報告病例激增。也就是說,這些病例并不是全在2月12日這一天發生,只是在那天將他們全部添加到了報告總數中。
只要你做一下搜索,很容易為這個離群值找到解釋。而有了這些信息,你就可以決定如何處理這個離群值。但如果你在開始建模之前沒有真正仔細查看數據,就不會發現這些。
第3課:對地理數據進行歸一化
大家特別容易忘記的一個基本技巧是,用人口或其他具有代表性的因素對數據進行歸一化后,按地理區域收集的數據總是更有意義。畢竟,一個擁有500人的村莊,與一座800萬人口的城市相比,300例病例代表的發生概率要大得多。
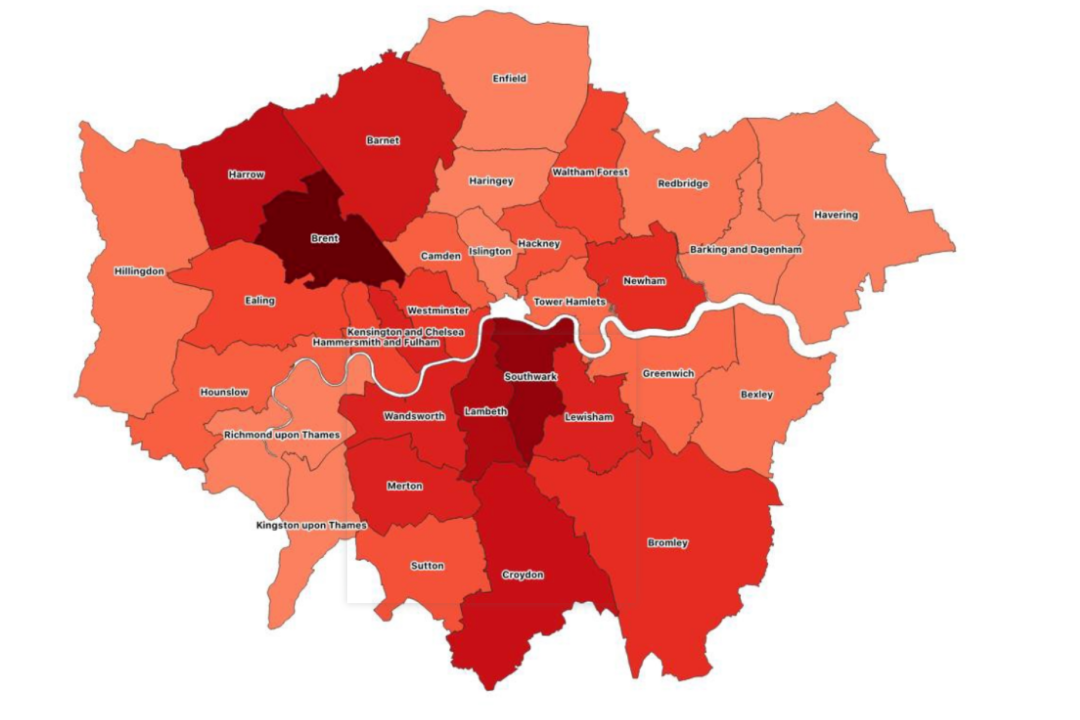
例如,下面這張地圖使用了政府提供的統計數據,截至2020年4月8日為止,以倫敦每個區的COVID病例數為陰影:
倫敦各個區的COVID病例數分布圖,顏色更深=病例更多
然而問題在于,不同的行政區有不同的人口數量。當我們在地圖上僅僅使用病例數進行著色時,最終不可避免地還是要重新繪制人口圖。
在這個地圖上,位于城市最南端的克羅伊登(Croydon)和位于市中心的南華克(Southwark)具有相同的顏色。但是克羅伊登的人口比南華克多20%,而且面積更大。如果僅僅因為這兩個地區的病例數相同,就說這兩個地區受到同樣的影響,這是沒有道理的,因為克羅伊登的感染率相對更低。
那么解決方案就是通過人口等其他因素對地圖進行歸一化。只需要簡單地將每個區的病例數除以該區的總人口數,就可以得出發病率。使用發病率來繪制,我們將獲得一個更容易理解的地圖,從而評估受影響最嚴重的區域:
倫敦各個區按2018年人口標準化的COVID病例數分布圖,顏色更深=病例更多
如果按人口劃分,我們會發現克羅伊登(Croydon)的發病率只是中等水平,而泰晤士河邊的南沃克(Southwark)是受災最嚴重的地區之一。
在美國這樣人口分布非常不均的國家查看國家或地區級數據時,這種影響甚至更大。在美國,幾乎所有人都居住在東海岸、西海岸或德克薩斯州附近。相比之下,其他大部分地區都人口稀少。如果我們對數據不進行歸一化就繪制美國地圖,最終可能只是按照人口密閉度畫了地圖。
第4課:對一些出乎意料的結果保持懷疑并多次檢查
無論你多么努力地去理解數據然后建立正確的模型,總會有無數種方式導致模型意外出錯。因此,如果你將數據輸入模型后,得出了一個出乎意料的特殊結果,那么你應該考量一下,是否要對數據有所懷疑,并且仔細檢查是否遺漏了數據。
IHME創建的模型是報告美國COVID-19疫情的模型之一,該模型預測了COVID-19的流行高峰期和對醫療保健系統的總需求。他們預計在美國將造成約6萬人死亡:
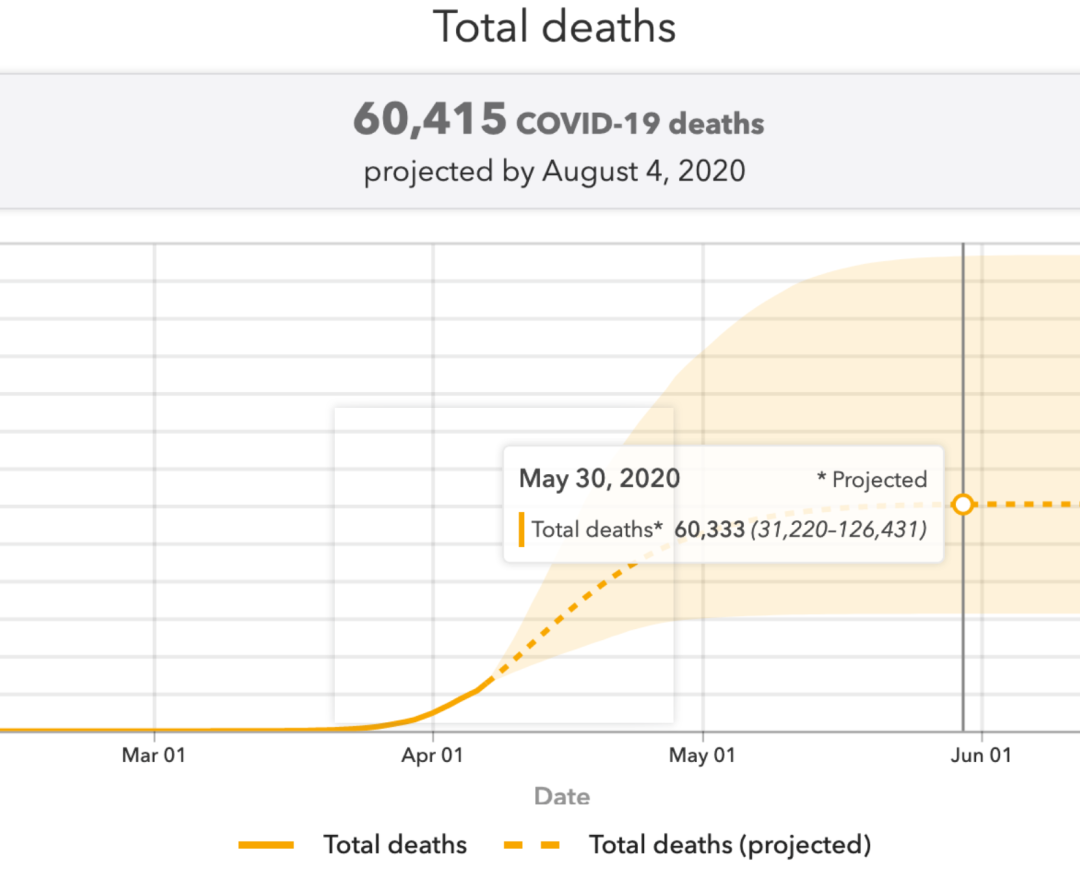
IHME預測的美國COVID死亡人數
他們最近還增加了對英國的預測,盡管只是初步預測,但預測的死亡人數甚至更高,達到66,000:
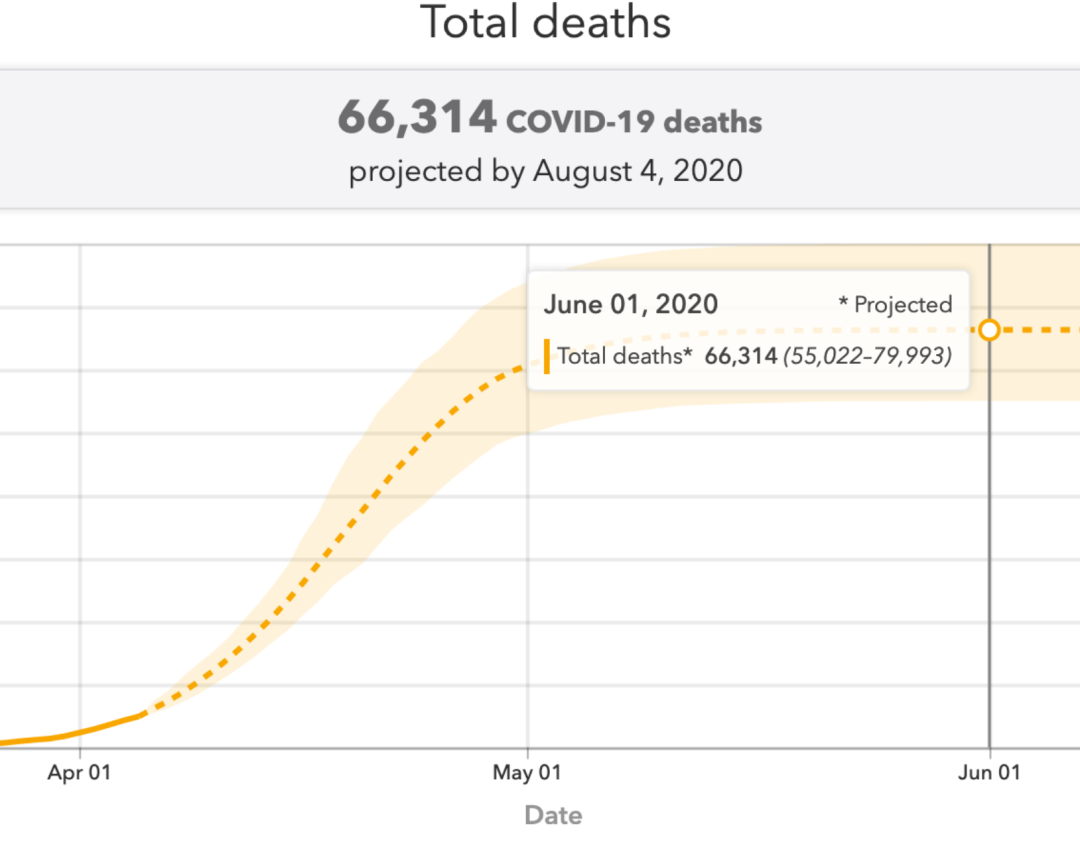
IHME預測的英國COVID死亡人數(舊)
這是一個非同尋常的預測。該模型表示,人口約為3.3億的美國,將比人口約為6600萬(美國的1/5)的英國死亡人數更少。由于差異如此之大,在我們搞清楚原因之前,應當對此有所懷疑。
這種懷疑與該模型創建團隊的能力或工作質量無關,畢竟非常確定性地去預測一個罕見事件,這本就是一件難事。模型可以幫助我們了解不同的變量是如何驅動結果的,但它們也僅僅只是模型。所以我們不能盲目地相信模型,每當我們看到比較極端的預測結果時,都應當去嘗試了解到底發生了什么。
新模型發布后的頭幾天,英國報告的實際數字都低于該模型的最低預測范圍。于是幾天后,IHME就用更大的置信區間更新了這張圖,這代表該預測具有更多的不確定性:
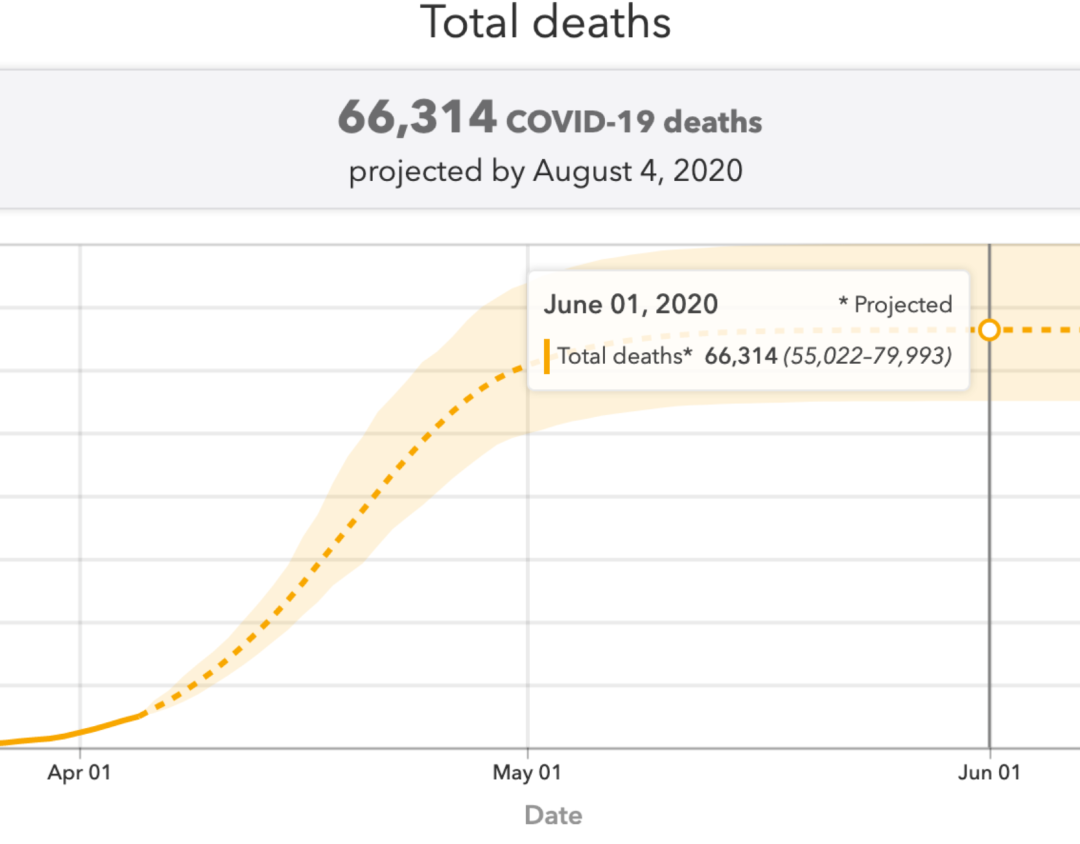
IHME預測的英國COVID死亡人數(新)
即使有了新的置信度區間,該模型仍然預測出了比其他團隊類似模型預測的更高的數字。倫敦帝國理工學院的Neil Ferguson教授在媒體上引用了這個模型,他認為這個模型在英國的預測是有缺陷的,因為IHME錯誤地模擬了醫院利用率,而他的模型則預測出了更低的數字。因此,現在我們就能看到這樣的案例,兩個單獨的模型給出了兩個完全不同的預測范圍。
當然這并不是什么壞事。探究別人的模型,本就是檢驗自己的假設和模型中是否存在未考慮因素的好方法。真正糟糕的情況是我們盲目地相信任何特定的模型,因為沒有一個模型可以完美地處理所有的極端情況。
同樣,我們也要對自己的模型保持質疑——如果你覺得結果令人匪夷所思,那么就假設你的模型犯了一個錯誤,去探究,去查看,直到你搞清楚為什么會得到這樣的結果。總而言之,不要盲目相信自己的模型!
當作者發表這騙文章幾小時后,IHME更新了他們的英國模型并將其對英國死亡人數的預測從66,314大幅度降低至37,494(降低了近50%)。然而這個數字仍然比其他模型的預測值還要高一些,不過已經接近多了。因此,這個故事的寓意是正確的——對意外的結果要始終保持懷疑~
相關報道:
https://medium.com/@ageitgey/four-basic-data-science-lessons-illustrated-by-covid-19-data-7d94134a5b0e
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】